
Imagine navigating through a labyrinth of data without a map or, even worse, with several inconsistent maps. Frustrating, isn't it? It’s a challenge that today's enterprises face when they overlook the critical role of a data warehouse. In a world overflowing with data, data warehouse consulting can become your compass, a source that guides decision-making and strategic planning.
Why is building a data warehouse important? Imagine having multiple departments generating tons of data like customer interactions and transaction histories. Simply storing this data won't cut it; you must turn it into valuable insights for real business impact. A data warehouse consolidates these scattered data sources and enables advanced analytics. This helps reveal trends, make accurate predictions, and guide data-driven decisions. The benefits include better operational efficiency, new revenue opportunities, and a competitive advantage.
In a world full of data but short on insights, a data warehouse is essential for making the most of the information you already have. Join us at N-iX to learn how to build an effective data warehouse in our step-by-step guide.
Choosing from the dueling methodologies
Before moving to the specific steps of building a data warehouse, it’s wise to learn about the methodological background of this question. Building a data warehouse is fundamentally influenced by the methodology you follow. Generally, the field has two dominant methods: Inmon and Kimball. Here, let’s take a look at the key processes and distinctive features of each to help you make an informed decision.
Inmon approach: The top-down model
The Inmon approach emphasizes creating a centralized data warehouse as the first step, followed by constructing data marts. This top-down model aims for a unified, enterprise-wide data solution.

1. Centralized data warehouse
The focal point is a centralized data warehouse that serves as the single source of truth for the entire organization. All organizational data is funneled into this unified structure.
2. Data normalization
One of the hallmarks of the Inmon approach is its emphasis on data normalization. This means that the data in the warehouse is organized in a way that reduces redundancy, thus ensuring data integrity and facilitating efficient querying.
3. Data marts
Once the centralized data warehouse is established, Inmon's model recommends constructing data marts. These are smaller, more focused databases tailored to meet the needs of individual departments such as marketing, finance, or HR. Data marts make extracting specific insights relevant to their operations easier for these departments.
4. High initial investment
The Inmon approach demands a substantial upfront investment, but the payoff is a robust, unified data warehouse capable of supporting complex queries and providing in-depth analytics across the organization.
Kimball approach: The bottom-up model
The Kimball approach advocates a bottom-up methodology, where individual data marts are initially developed for specific business units and then integrated into a full-scale data warehouse.

1. Data marts first
The data marts designed for specific business functions are the building blocks. These can be developed rapidly, offering immediate business value.
2. Star schema
The Kimball model utilizes the Star schema to organize data. This structure is relatively simple but highly effective for fast and flexible querying, making it well-suited for quick, iterative analytics.
3. Quicker deployment
The focus on initially creating data marts allows organizations to deploy functional elements of the data warehouse quickly, offering immediate business benefits.
4. Scalability
These individual data marts can be scaled and seamlessly integrated to form a comprehensive data warehouse, making this approach flexible and adaptable.
Selecting between the Inmon and Kimball methodologies is not a one-size-fits-all decision but should be tailored to your organization's needs, resources, and goals. N-iX Data team is proficient in implementing both Inmon and Kimball methodologies for data management.
If you're a large enterprise seeking a robust, long-term data warehouse, our teams are skilled in the Inmon approach. We employ the Kimball method for organizations needing quick analytics capabilities to build agile data marts. This dual expertise allows us to tailor our strategy to your unique business needs.
The hybrid approach combines the best elements from Inmon and Kimball methodologies to create a versatile data management strategy. In this approach, source data is kept unchanged, making recovering from ETL issues easier and enhancing system resilience. Before loading into the data warehouse, the data undergoes transformation and cleaning to ensure quality. The data in the warehouse is organized using a Star schema, offering flexibility and optimized query performance.
Multiple data marts can also be supported off the main warehouse, allowing for different technologies, products, and data subsets. These marts can also support various aggregates based on the Star schema. While users can query raw, warehouse, and mart-level data, most queries are typically directed at the data marts for better performance. The choice between Inmon, Kimball, or the hybrid approach should be tailored to your organization's needs, resources, and objectives.
Building a data warehouse: A step-by-step guide
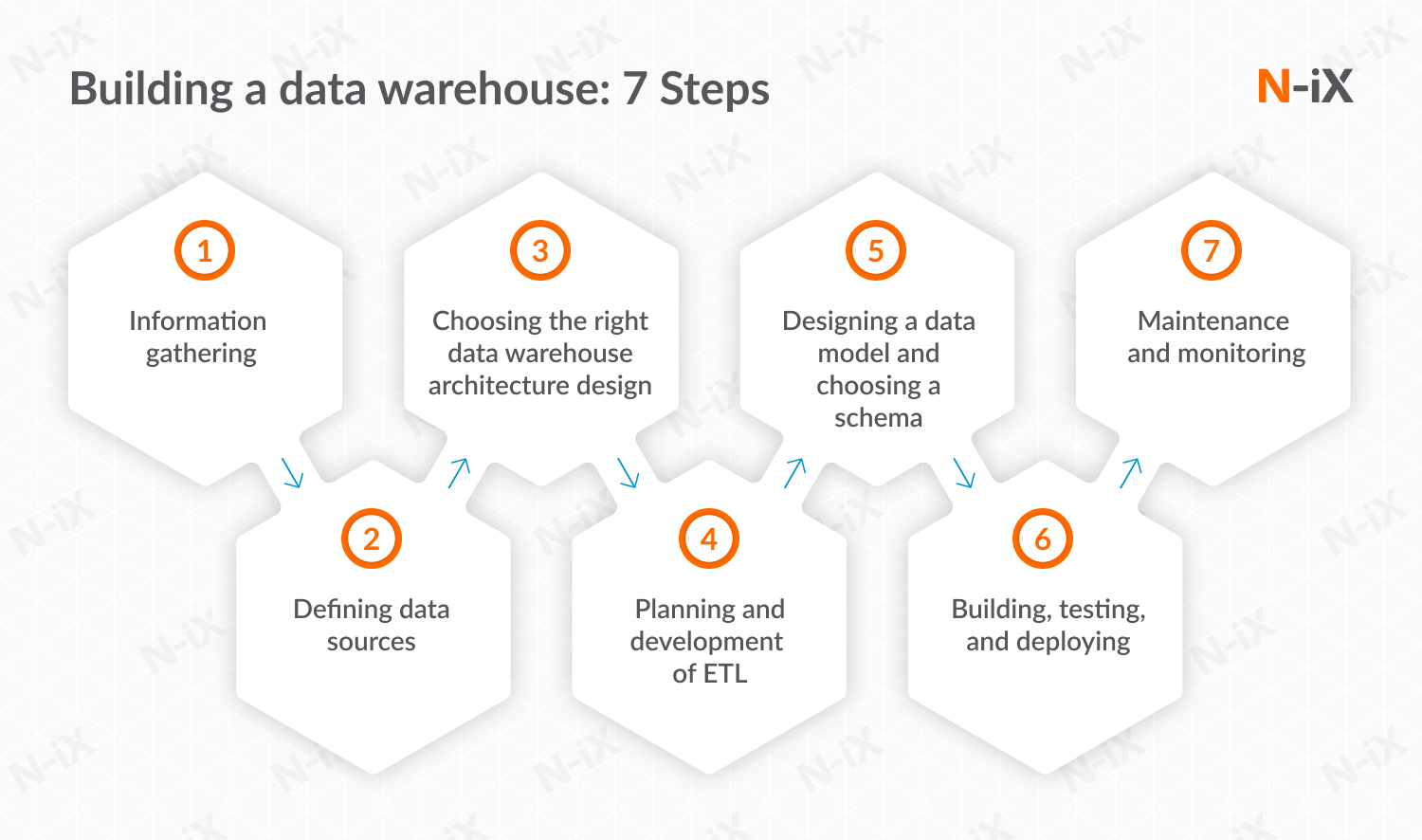
Building a data warehouse doesn't have to be exceptionally overwhelming. We've distilled the entire process into seven steps that offer a roadmap to a successful implementation. This guide is a strategic playbook, turning the complexity into an actionable game plan for building a robust data warehouse.
1. Information gathering
The initial phase of building a data warehouse is far more than a cursory review of your business needs and available resources. It's an in-depth information-gathering stage that sets the trajectory for the project. Let's delve into the specific processes involved.
-
Aligning with business objectives:
You can't design a data warehouse in a vacuum. Conduct detailed interviews with business stakeholders–CFOs, CMOs, data analysts, etc.–to pinpoint exact analytics needs. Are you looking to enhance customer segmentation, automate supply chain management, or facilitate real-time decision-making? The answers will drive the functionalities your data warehouse must support.
-
Assessing the infrastructure:
Analyze your existing hardware and software landscape to determine compatibility with the planned data warehouse. This isn't just about whether your servers have enough processing power but compatibility. Are your existing systems largely on-premises, or have you moved to the Cloud? Have you made a thorough assessment to choose between the data lake and the data warehouse? All these answers influence your architectural choices and may also dictate whether you need additional data integration or transformation tools.
-
Analyzing the data source quality:
Data quality is paramount. Scrutinize your proposed data sources for potential issues like missing values, inconsistencies, or duplicate entries. Evaluate the formats (CSV, SQL databases, etc.) and identify any needed transformations. If a data source is not up to standard, it is time to decide whether it should be cleaned, enriched, or excluded.
-
Estimating a project timeline:
Develop a project roadmap with milestones tied to business goals. This isn’t a rough estimate but should be a detailed timeline, including phases for testing, data migration, and user training.
The information gathered during this critical first phase is the bedrock upon which the subsequent steps are built. Without a thorough understanding of these areas, even the best-laid data warehouse plans risk falling short of business expectations. Due to the data warehouse building, it’s a good idea to have samples of reports or dashboards that business users expect to see.
2. Defining data sources
Understanding where your data originates and how it will flow into your data warehouse is crucial for achieving your strategic business goals. Here's a more detailed breakdown of the processes involved in this phase.
1. Key data source
You've outlined your business objectives; now identify the databases, applications, or systems that hold the data to meet these goals. They could range from your sales CRM holding valuable customer information to ERP systems storing operational data like inventory levels. Create a prioritized list of these sources based on their importance for the KPIs you aim to analyze.
2. Data integration requirements
Different sources often mean other data formats. Financial data might be stored in an Oracle database, while customer interactions are logged in a NoSQL database like MongoDB. Each will have its own data types, structures, and retrieval methods. A detailed understanding of this will enable you to select the right integration tools–traditional Extract, Transform, Load (ETL) software, real-time streaming services, or cloud-based integration platforms.
3. Data ownership and access
Knowing who owns what data is crucial not just from a governance standpoint but also for practical reasons. For instance, if a department holds sales data, you need their permission to access it. Additionally, find out what credentials, API keys, or special query languages are required for data extraction. Secure these early to avoid bottlenecks later.
4. Data velocity
Some data sources, such as transactional databases, might be updated in near real-time, while others, such as batch uploads from legacy systems, might only be updated daily or weekly. Understanding the data generation and update rate is crucial for configuring your ETL pipelines. Real-time data may require stream processing tools, while traditional ETL processes might sufficiently handle batch data.
5. Data source reliability
Not all data sources are created equal, especially if we’re talking in terms of reliability. An API that experiences frequent downtimes will not be suitable for a data warehouse that requires real-time analytics. Evaluating each data source's uptime, maintenance schedules, and past reliability is essential. Building a data warehouse requires planning contingencies for critical but unreliable sources, such as fallback data sources or cached data layers.
6. Integration points
Map out the journey of the data as it flows from these sources into your data warehouse. Will sales data from the CRM go directly into a centralized fact table, or will it first be aggregated in a finance-focused data mart? This mapping exercise ensures that each data element finds its place in your overall architecture, making your analytics more organized and intuitive.
Defining your data sources sets the stage for effective data integration, transformation, and, eventually, analytics. It ensures that you're not just aggregating data but doing so in a way aligned with your business objectives and technical capabilities.

3. Choosing the right data warehouse architecture design
The choices of a specific architecture will fundamentally influence how the data warehouse performs, scales, and evolves. It's pivotal to align your architectural decisions with your business needs. For many modern enterprises, this means considering a data lakehouse architecture, which blends the capabilities of data lakes and warehouses to meet long-term scalability requirements.
- In the one-tier architecture model, there's a direct connection between the data sources and the end-users. The data warehouse typically resides on a single server where data is collected and directly accessible for query and analysis. This approach is most suitable for smaller, less complex data needs where quick setup is a priority.
- In a two-tier architecture, the data warehouse is separate from the operational databases. The data undergoes ETL processes before it is moved to the data warehouse, creating an intermediary layer that allows for more effective data cleansing, transformation, and integration.
- A three-tier architecture adds another layer between the end-users and the data warehouse, commonly known as the data mart layer. It allows more efficient data retrieval as each department or function can have its dedicated data mart, streamlining analytics.
We recommend looking at our featured article on Enterprise Data Warehouse for a more comprehensive look at the nuances, advantages, as well as use cases for each of these architectures.
The choice of architecture will have cascading effects on your ETL processes, data modeling, and even the hardware or cloud services you'll need. Hence, it’s crucial to thoroughly evaluate your options in the context of both your immediate and long-term business objectives.
4. Planning and development of ETL
ETL processes are the backbone of any data warehouse, acting as the pipeline that moves data from its sources into a format suitable for analytics. Given its central role, a well-planned ETL strategy is a must. Here’s how to get started:
1. Identify ETL tools
The first order of business is to identify the ETL tools most suitable for your specific needs. These could range from traditional ETL platforms like Informatica and Talend to cloud-native services like Google Dataflow or Azure Data Factory. The final choice will be influenced by factors such as the volume of data, speed requirements, and compatibility with your existing IT infrastructure and target technologies. Sometimes, tools can be very vendor-oriented and tied to specific RDBMS or NoSQL technology.
2. Map your data
Before data can be transformed, it must be mapped from the source to the target schema in the data warehouse. This involves outlining how different fields in the source databases correspond to tables and columns in the target data warehouse. Data mapping ensures that data from various sources can be unified coherently.
3. Decide on the transformation logic
Defining the rules and processes for transforming the raw data into a usable format for analytics is crucial. This can include anything from simple data cleansing tasks, like removing duplicates or filling in missing values, to more complex operations, like generating and calculating new data points.
4. Design the ETL workflow
With the mapping and transformations outlined, the next step is to design the workflow. This involves optimizing ETL tasks, specifying dependencies, and setting up error-handling mechanisms. It's vital to ensure the workflow is streamlined for performance and can recover gracefully from failures.
5. Allocate resources
Determine the hardware and computing resources needed to run your ETL processes efficiently. Consider factors like CPU, memory, and network bandwidth. If your data warehouse is cloud-based, you'll also need to consider the costs and limitations of the cloud resources you’re using. When following the ELT approach, these processes will add a significant load to your target DWH system, so you must review the DWH RDBMS/NoSQL specs.
6. Proceed to development and testing
With the planning complete, you can now develop the ETL pipelines. Rigorous testing is critical at this stage. Test your ETL processes with a subset of data first, scaling up to full volume as you validate the data transformations' performance, reliability, and accuracy.
Planning and developing the ETL is not just a technical exercise but needs to be tightly aligned with your business goals. A well-executed ETL process ensures that the data feeding into your warehouse is reliable, timely, and ready for insightful analytics.
5. Designing a data model and choosing a schema
Once you've outlined your ETL processes, the next focus is on how this data will be organized within the data warehouse. The process involves two main tasks: designing a data model and choosing the appropriate schema.
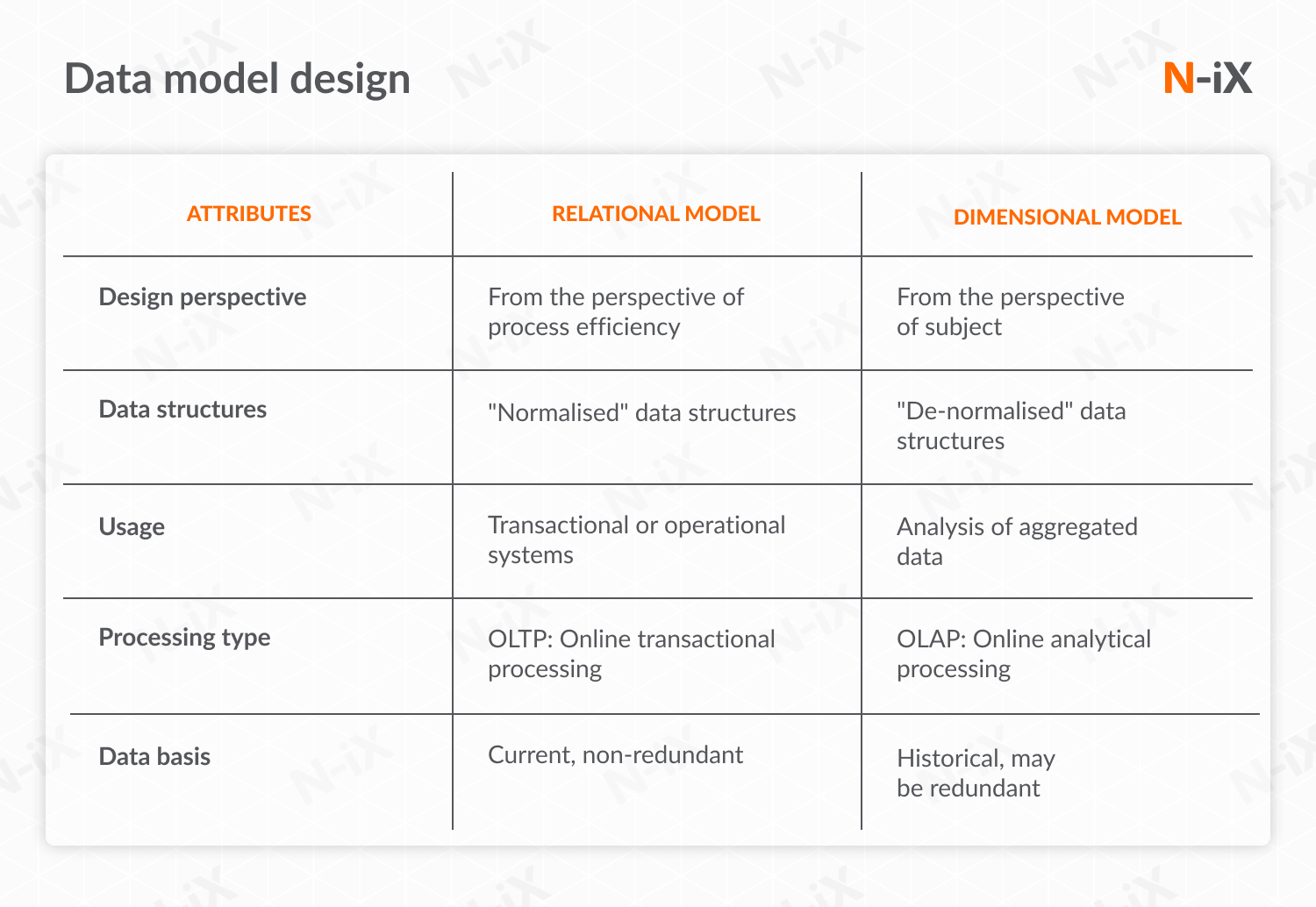
Data model design
The data model design provides a conceptual representation of the data, outlining how elements relate within the data warehouse. Two primary types of data model designs are commonly used:
Entity-relationship model (ER-model) outlines the relationships between different entities (tables) in your database. It is beneficial for complex queries that involve multiple tables.
The dimensional data model (DDM) focuses more on usability and is designed to simplify complex queries into straightforward SQL queries. It is well-suited for data warehousing environments where performance and ease of use are priorities.
Choosing a schema
The schema is a blueprint that defines the structure of your data warehouse. Your choice of schema affects how quickly and easily you can extract information from it. There are several options:
Star schema is a denormalized schema where one large "fact table" is connected to multiple "dimension tables." It's designed for fast query performance and is easy to understand.
Snowflake schema adds tables to a typical Star schema, normalizing it to eliminate redundancy. This reduces the disk space needed but may result in more complex queries.
The data vault is a detail-oriented, historical-tracking, and uniquely linked set of normalized tables that support multiple business domains. It is beneficial for large enterprises that require full auditing and traceability. Also, it depends heavily on careful business key choices for every entity used in your model. The data vault is flexible and scalable for adding new sources and can be scaled to hundreds of petabytes, but it’s unsuitable for static data and fast query performance.
Star schemas generally offer faster query performance and are easier to navigate, making them well-suited for real-time business intelligence tools and aggregation queries. On the other hand, snowflake schemas are more normalized, easing database maintenance and beneficial for data governance. Their structure is better suited for specific, drilled-down queries and generally consumes fewer resources like memory and CPU. The final choice should align with specific use cases, such as the types of queries you frequently run, your team's skill set, and your overall performance needs.
6. Building, testing, and deploying
After laying down the foundational elements like ETL processes, data models, and schema, it's time to build your data warehouse. This is where the rubber meets the road, bringing your plans into a functioning system. Here's a rundown of what this critical stage involves:
1. Building the physical warehouse
By this point, you should know whether your data warehouse will be on-premises or cloud-based. The build process involves setting up the server infrastructure, configuring storage, and implementing security protocols. If you are using a cloud-based solution, this could include setting up virtual machines, storage buckets, and configuring access rights.
2. ETL pipeline implementation
The ETL processes outlined in Step 4 need to be implemented. It involves setting up the ETL jobs to pull data from your defined sources, transform it according to your transformation logic, and then load it into the data warehouse. You'll need to set schedules for these ETL jobs based on the freshness requirements of your data.
3. Data validation
Data validation is a two-pronged task. First, you must validate that the data loaded into the data warehouse maintains its integrity, meaning it hasn't been corrupted or changed unintentionally during the ETL process. Second, you must validate that the transformed data meets business requirements and can accurately serve analytics and reporting needs.
4. Performance testing
In this stage, you validate if your data warehouse can handle the projected load. By running queries and stress tests, you're mimicking real-world scenarios. It's about more than just whether your system can manage these loads but how efficiently it can do so. When the system goes live, you're not firefighting performance issues but rather focusing on leveraging the data for business insights.
5. Deployment
This is the leap from staging to production. Up until this point, your data warehouse has been a construct, albeit a well-tested one. Moving it to production means it's now a live entity, interfacing with your analytics and business intelligence platforms. This move is not merely about data warehouse migration but ensuring the system integrates well with other production-level applications and services. It’s vital to have a rollback plan should things not go as planned.
6. Soft launch
This is your safety net before going all in. A soft launch with a limited user group provides real-world testing that's controlled but invaluable. The feedback you gather can help you make those final adjustments to improve system performance or user experience. A soft launch is often the most enlightening phase, as it is the first time end-users interact with the system. Addressing issues at this stage can save you from complications that might otherwise require more drastic measures if discovered later.
Each phase, from construction to testing and, finally, deployment, is geared towards ensuring that the system is not just operational but efficient and reliable. The goal is a system that seamlessly integrates with your business intelligence tools, providing the data you need to make informed choices and drive your business forward.
7. Maintenance and monitoring
Congratulations, your data warehouse is running. However, the journey doesn't end with deployment. To ensure that your data warehouse continues to deliver value, you must actively maintain and monitor it. Here's what you need to focus on:
1. Regular updates
Businesses change, and your data warehouse needs to adapt accordingly. This involves more than adding new data; it includes revising existing schemas, integrating new data sources, and potentially altering transformations and data models. Failure to update your warehouse could lead to misalignment with business objectives and outdated insights, adversely affecting decision-making.
2. Scaling
As your data grows, your initial setup might show its limitations. Investing in more powerful computing resources or considering distributed computing solutions becomes more critical. Implementing automated scaling solutions can be beneficial in dynamically adjusting to varying workload demands. Scalability also involves human resources—ensuring your team can manage a more complex environment.
3. Metadata management
Metadata is the contextual layer providing extra information about the stored data. Proper metadata management is essential for both regulatory compliance and internal data governance. It's what makes data searchable, understandable, and trustworthy. You should have protocols for tracking metadata and ensuring it’s consistently and accurately updated, facilitating data lineage tracking and impact analysis.
4. Performance tuning
Performance issues are not always obvious, especially if they gradually worsen over time. Regular monitoring can help identify bottlenecks in data loads, query processing, or data transformation tasks. Refining indexing strategies, revising SQL queries, or modifying the underlying architecture is crucial to ensure the system performs optimally. High performance not only enhances user satisfaction but also contributes to operational efficiency.
5. Monitoring for data quality
Data quality can erode for various reasons, such as changes in source systems, human error, or system glitches. Data quality tools can continuously validate data for completeness, consistency, and accuracy. Automated alerts for suspicious data patterns or anomalies can help you act before minor issues become major problems.
6. Audits and reporting
Ensuring data's secure and compliant use is a continuous task. Audit mechanisms should provide detailed logs of who accessed what data, when, and what actions they performed. This step is crucial for internal data governance, and nowhere is external regulatory compliance more important than in a data warehouse in healthcare, where adherence to standards like HIPAA is mandatory. Regular reports can also help you understand how your data is being used, which queries are most common, and if there are unused data sets that may be archived to free up resources.
Continuous monitoring and regular upkeep are essential for maintaining your data warehouse as a trustworthy and efficient tool. These activities ensure the system remains agile and offers timely, actionable insights. Thus, maintaining a data warehouse enables your organization to consistently make well-informed decisions, helping you stay adaptive and competitive in a constantly changing business landscape.
N-iX personalized approach to building a data warehouse
Making the necessary technological transformations to become a data-driven organization is a monumental step that requires expertise, planning, and the right technology. At N-iX, we understand the complexities involved and are committed to making this journey seamless for you.
The following outlines our structured approach to help you build a robust data warehouse that aligns with your business objectives and technological landscape. From initial discovery to ongoing support, we offer a full spectrum of services tailored to your needs.
1. Understanding your objectives
Our journey begins with an in-depth discussion about your intention to become data-centric. We identify key stakeholders and organizational functions that will be a part of this transformative journey. This foundational stage enables us to craft solutions uniquely tailored to your objectives.
2. Aligning business and data
During our discovery phase, we focus on understanding the intersection between your business imperatives and data assets. The goal is to identify specific workloads or use cases where a data warehouse would immediately benefit your operations. This allows us to custom-fit our strategy to your unique landscape.
3. Technology deep dive
This phase is crucial for bridging the gap between your business needs and the technical capabilities of our data platform solutions. We host workshops and training sessions to familiarize your technical team with the involved technologies. These sessions delve into specific features, data architectures, and best practices for optimizing performance.
4. Project approval
In this stage, we develop a comprehensive business value case that outlines the project’s scope, timelines, and budget. This document serves as a reference point for all stakeholders involved. The case covers the technical details, forecasts ROI, and possibly even a phased implementation plan if the project is particularly large or complex.
5. Solution assessment
We believe that seeing is believing. Therefore, we construct a custom demo replicating a real-world scenario based on your selected workloads and business drivers. This demo provides tangible evidence of how the data warehouse will handle your specific data needs, addressing performance, scalability, and usability queries.
6. Finalizing the agreement
Legal and administrative steps come into play here. We finalize our partnership's terms, conditions, and service level agreements (SLAs). Contracts are reviewed, and a Mutual Action Plan is created, serving as a roadmap that outlines each step of the project, from initial implementation to the go-live date.
7. Putting plans into action
Execution begins as soon as the project is approved. This stage is crucial for setting the right pace and ensuring the project remains on track. An educational package is often provided to fill your team's skills gaps. The implementation phase commences, backed by experts offering hands-on support and regular updates on milestones reached.
8. Going live
The final step in the setup process is operationalizing the data warehouse. We provide support teams and documentation to ensure a seamless transition, facilitating your personnel as they adapt to the new system. We also conduct final performance tests to ensure everything is optimized for your live environment.
9. Ongoing support
Post-launch, we don't just hand over the keys and walk away. Continuous monitoring and performance reviews are part of our service package. Whether it's resolving technical hiccups or strategizing for future scalability, we offer a range of ongoing services tailored to your specific operational and business needs.

By diving deeper into each stage, we aim to offer a thorough, tailored experience that ensures your data warehouse is a business asset that drives actionable insights and contributes to your organization's success.
Building a data warehouse: Our success stories
When building a data warehouse, we focus on transforming complex data ecosystems into streamlined, efficient operations. Our expertise has delivered tangible benefits, from significantly reducing operational expenses to automating processes that saved thousands of work hours annually. But don't just take our word for it—our case studies speak for themselves.
Elevating in-flight connectivity and creating EDW for Gogo
Business challenge:
Gogo, a leader in in-flight connectivity, aimed to migrate to cloud-based solutions, build a unified data platform, and enhance in-flight Internet speed. The challenges included handling diverse data sources and optimizing operational expenses for Wi-Fi performance penalties.
N-iX approach:
N-iX engineered an AWS-based data platform aggregating data from over 20 sources like plane and airborne logs. The team facilitated this by implementing a cloud-hosted data lake using a mix of Amazon RDS, Amazon S3, Amazon Redshift, and Amazon EMR. N-iX then performed data migration and set up AWS Redshift for reporting purposes. We designed a unified AWS-based Enterprise Data Warehouse (EDW) that provides insights into device performance and hardware operations onboard the aircraft.
Value delivered:
- Cost reduction. Gogo experienced substantially decreased operational expenses, particularly in penalties paid to airlines for sub-par Wi-Fi performance.
- Enhanced data management. The unified AWS-based EDW streamlined the data management process, consolidating data from multiple sources.
In summary, N-iX helped Gogo transition to a robust AWS-based data platform, reducing costs associated with poor in-flight Wi-Fi and centralizing disparate data sources for improved operational efficiency.
Automation, cloud migration, and cost optimization for a global tech company
Business challenge:
The client, a global provider of managed cloud services, faced significant challenges in generating Monthly Service Reviews (MSRs). The process was inefficient, costly, and manual, mainly because the client had a sprawling on-premise infrastructure and no centralized system to handle the massive data generated by their equipment.
N-iX approach:
Our designated Data team tackled this challenge by migrating the client’s on-premise MS SQL Server infrastructure to Google Cloud Platform (GCP), where a unified data warehouse was built. This warehouse consolidated over 70 operational data sources, 4 other data warehouses, and 1 data lake, decommissioning 20 servers.
Our Data team located and eliminated anomalies to ensure high data quality. N-iX also implemented an ELT (Extract-Load-Transform) methodology to handle data from various vendors instead of the standard ETL. This standardization enabled efficient data transfer from Kafka to BigQuery.
Finally, N-iX automated the generation of MSRs. Before this, the client used a third-party tool and manual processes, consuming approximately 17,000 work hours annually. The data was centralized in BigQuery post-automation, making MSR generation streamlined and efficient.
Value delivered:
- Cost optimization. By migrating to GCP, we managed to decommission over 20 servers, thus substantially cutting costs.
- Efficiency in data management. The unified data warehouse on GCP streamlined data collection, accessibility, and management.
- Operational efficiency. Automation of MSR generation saved nearly 17,000 work hours per year and eliminated the need for an expensive third-party tool.
Overall, the N-iX Data team delivered a robust and unified data warehouse solution on GCP, optimizing costs, enhancing operational efficiency, and automating manual processes for the client.
Read more: Automation, cloud migration, and cost optimization for a global tech company

Final remarks
Embarking on a data warehouse project is a significant investment that demands a knowledgeable and experienced partner. Besides our extensive expertise in building on-premise, AWS-, and Azure-based data warehouses, N-iX is globally recognized and part of Google Cloud’s Partner Advantage program, specifically for Data Warehouse Modernization Expertise.
With a capable team of 2,400+ professionals specializing in Data technologies like Redshift, BigQuery, and Snowflake, N-iX provides comprehensive data warehousing services. Our track record includes successful data projects with industry giants like Lebara, Gogo, and Vable. Trust N-iX to seamlessly guide you through each phase of your data warehouse journey, aligning each step with your business goals.
If you're ready to make your data work smarter for your business, we're here to make that happen by helping you build a data warehouse for your specific business needs.
Data Lake vs. Data Warehouse: choose the best solution with our guide

Success!
Have a question?
Speak to an expert


