
By implementing an enterprise data warehouse (EDW) businesses can make smarter, data-driven decisions. EDWs can help you get a helicopter view of your business operations by turning multi-sourced data into unified analytics. However, common challenges, such as proper architecture design, choice of data modeling framework or hosting environment, might turn organizations away from EDW implementation.
How do you choose the EDW architectural and implementation approach to ensure it meets your specific needs? And what data modeling framework and hosting environment are the best match for your business? Read and learn the tips from our top experts in data warehouse consulting and Data Analytics.
What is an enterprise data warehouse?
An EDW serves as a central hub for aggregating, cleaning, integrating, and storing business data from multiple sources in one place. In other words, it is a data repository optimized for business reporting and analytical processing. Think of an EDW as a fitness tracker–it collects raw data such as the user's heart rate, sleep cycles, and steps from various sources, processes it, and provides personal recommendations. Similarly, an EDW stores information from different departments and systems within an organization, transforms it, and generates operational, financial, and other reports.
So, how does an EDW convert unprocessed corporate data into actionable insights? The centralized data warehouse prepares data for reporting through data integration and ETL (Extract-Transform-Load) process. Since enterprise data warehouses collect data from multiple sources, integration is essential to ensure that the multisource information is unified into a single, cohesive dataset. Data integration is followed by the ETL process that refines the integrated data. The raw data is extracted from the source database, transformed (cleansed, deduplicated, and simplified) for improving data quality, and loaded into the EDW. As a result, your business data is now consistent and ready for analysis and BI reporting.
Enterprise data warehouse vs data warehouse: Key differences
Both standard data warehouses and EDWs act as centralized repositories for storing data and are critical components for enabling Business Intelligence. Why do we single out an EDW as a separate concept, then? Here are the major distinctive features between the terms:
- Size. Unlike regular data warehouses, EDWs function as a single hub for data across the entire organization. Standard data warehouses are smaller repositories that process data from a specific business unit or function.
- Technical complexity. An enterprise data warehouse typically has a complicated architecture, which allows managing and integrating a wide range of data types and sources. The architecture of data warehouses allows them to only deal with less diverse and simpler data sets.
- Scalability. EDWs are designed with organizational growth in mind. EDWs can seamlessly integrate new data sources and expand capabilities as your business matures. On the other hand, standard data warehouses might require modifications of data schemas, infrastructure, and ETL processes to handle similar scaling.
The data warehouse architecture impacts its ability to integrate multisource data and influences strategic decision-making. So, let's look at different types of enterprise data warehouse architecture and its components.
Related: Data lake vs data warehouse: Which one to choose for your business?
Enterprise data warehouse architecture: structure and types
On a high level, the architectural style of EDW might be split into three layers, each responsible for a specific phase of a data flow:
- Sources layer, where raw data is collected from multiple sources and stored. Data sources usually include enterprise applications (CRMs and ERP systems), flat files, logs, IoT devices, or other organizational data containers.
- Enterprise data warehouse layer, which might contain different functionalities depending on the architecture complexity. Once the data goes through ETL, it is loaded into the data warehouse layer. Here's where structured, semi-structured, and unstructured data is stored and aggregated. This blending of data types within a single system is a core principle of the modern data lakehouse architecture, which aims to get all data ready for reporting and analytics.
- Analytics and outputs comprise the last layer of an enterprise data warehouse architecture. This unit performs data visualization and BI reporting functions, using analytical tools to translate processed data into insightful reports.
However, the structure of an EDW architecture might be more complex than that. For many organizations, business needs call for more scalability and data governance opportunities. Here's when data management companies might also add data mart (a subject-oriented database) and OLAP layers (data hubs for multidimensional analytics) to the repository architecture. Based on the number of additional layers, we differentiate one-tier, two-tier, and three-tier types of EDW architecture. Let's view each of them in more detail.
One-tier architecture
This type of enterprise data warehouse architecture consists only of three basic layers: sources, EDW, analytics and outputs. The data flows directly from your EDW to the reporting layer. What is an enterprise data warehouse based on a one-tier architecture? It is the simplest enterprise data repository, with limited scalability and analytical capabilities. However, it is easy to set up and has low latency–so you can be sure that your EDW will respond with minimal delay. One-tier architecture best suits enterprises prioritizing real-time reporting over deep and complex analytics.
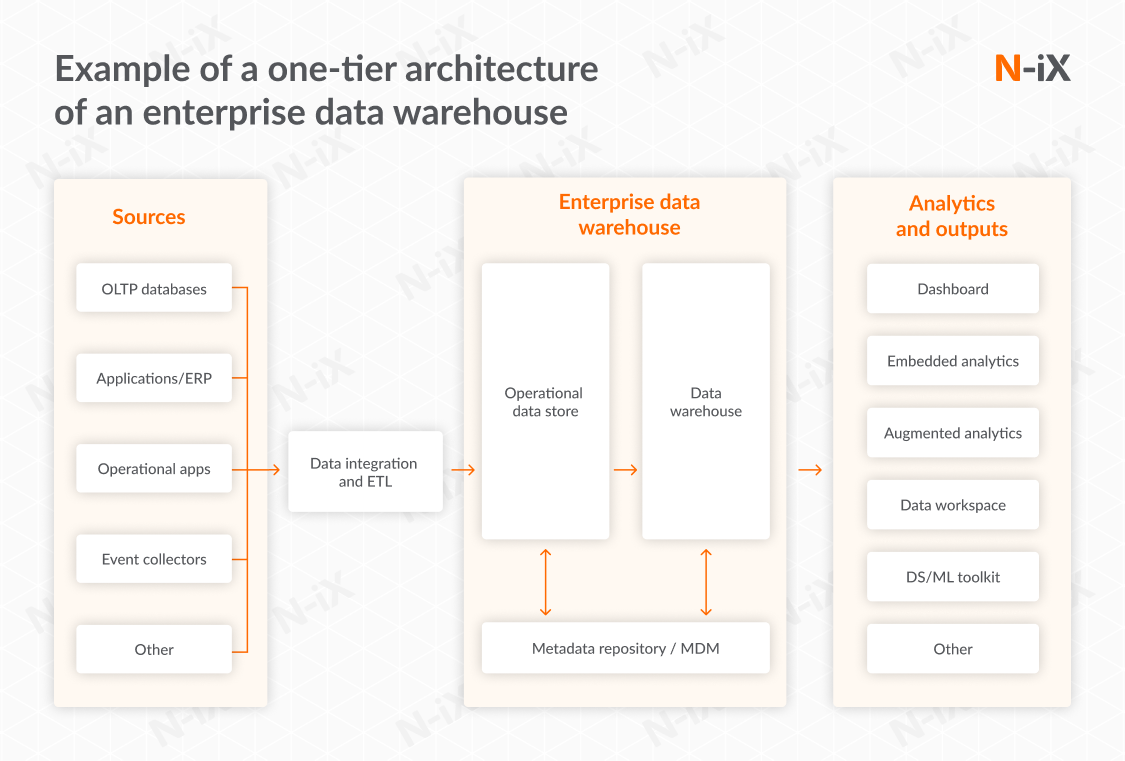
One-tier architecture will match your business needs if:
- Your business has simple data requirements without the need for complex transformations or integrations.
- You need quick, real-time access to data without the latency of multi-tier architectures.
- Only a small group within your organization requires access to the data, reducing the need for elaborate security and access control features.
Two-tier architecture
Suppose you want your EDW to provide reports for specific departmental or functional uses rather than the one dashboard with minimum analysis. In that case, we recommend opting for a two-tier architecture. This type of enterprise data warehouse architecture contains a data mart layer placed between the EDW and the reporting layer. A data mart layer consists of several smaller-sized repositories or data marts, each corresponding to a specific business function. For instance, it might include separate data marts for sales, project management, marketing, and other departments. Though this approach requires more resources, such EDWs produce more relevant, specific reports for every business function. In addition, since each data mart serves a specific purpose, you can reduce the overall query load on the EDW and improve performance.

Choose two-tier architecture in case:
- You want to keep the database and business logic separate, making it easier to update one without affecting the other.
- Your organization has moderately complex data needs that require a higher level of processing than the one-tier architecture.
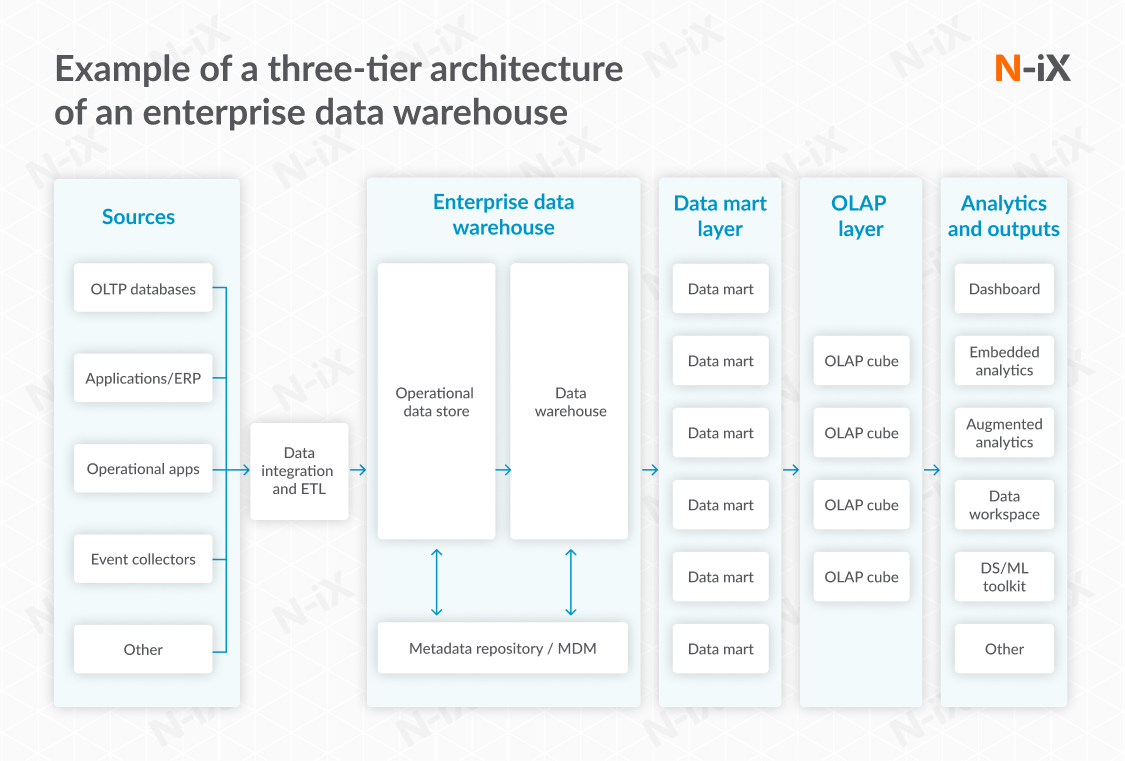
Three-tier architecture
The structure of a three-tiered architecture is similar to the two-tiered–it includes the same components and an additional OLAP layer. The latter is a dataset which consists of three or more dimensions.
Let's compare a regular spreadsheet with the OLAP, taking reporting of an HR department as an example. In a two-dimensional spreadsheet such as Google Sheets, the structure would be linear, and the measures (name, position, salary, department, etc.) would be listed horizontally. The reporting is limited to two dimensions (rows and columns), so it's difficult to effectively represent hierarchical or time-series data. In contrast, the OLAP cube can simultaneously handle multiple dimensions such as employee, position, salary, department, and time (quarter, year). In addition, the cube can either interact directly with an EDW for access to comprehensive organizational data or be used with individual data marts for more specialized information.

Is implementing a three-tier enterprise data warehouse architecture worth the invested resources for a business? With OLAP cubes, you get in-depth reporting with easy navigation–you can slice, dice, drill down, roll up, and pivot the data set, depending on your goal. A reliable data analytics company like N-iX can help you build any EDW, from the simplest to three-tier, tailoring the size and complexity of the solution to your data analytics needs.
Three-tier architecture is a perfect fit for your business if:
- Your organization requires complex data processing, transformations, and integrations.
- Your enterprise is rapidly growing, so you need an architecture that can easily scale along with increasing data and user loads.
- You need a highly flexible system where changes in one layer don't necessarily bring changes in the others.
Learn also the difference between a data mart vs data warehouse
Building an enterprise data warehouse with the right data modeling framework
A well-designed EDW architecture is at the heart of your data management and analytics operations. However, your EDW will only function well with the data modeling framework that fits your business needs. These frameworks define the relationships between data objects as well as the rules for data storage, retrieval, and processing. Let's take a look at some of the most common (but not the only ones) data modeling frameworks.
Adapt
Adapt framework is specialized for OLAP databases, providing a structural approach to the blocks of the multidimensional data model. Though Adapt was initially designed for OLAP datasets, nowadays, enterprises can use it for different data architectures. It comprises nine database objects, each represented using specific symbols for clarity in documentation. The framework outshines traditional techniques such as entity-relationship (ER) and dimensional modeling, especially in certain contexts like OLAP databases. What are its key distinctive features?
- All-encompassing approach, which considers both data and process and is beneficial for building OLAP data marts.
- Focus on logical modeling. Adapt emphasizes the need for logical modeling, encouraging engineers to comprehend the problem before proposing solutions.
- Enhanced team communication, ensured by continuous discussions concerning Adapt, is more regular than for the traditional models. Better communication guarantees that every team member is on the same page, improving overall project efficiency and the solution's quality.
- Complete representation. Within the Adapt methodology, an OLAP application can be thoroughly represented without compromising on design.
BEAM
BEAM (Business Event Analysis & Modelling) is another popular data modeling for an EDW. Unlike Adapt, this approach focuses more on business processes, not reporting. BEAM aims to provide a complete view of the business through its data model, considering events that trigger data changes. The model uses a tabular format and collaborative notations to document business processes. As a result, BEAM stimulates active communication between team members and fosters a strong sense of ownership among stakeholders. Here are the other characteristics that make organizations choose BEAM for their EDWs:
- The 7Ws approach aims at building data stories using specific examples and answering the questions of who, what, when, where, how many, why, and how (7Ws). By focusing on specific сriteria, enterprises can ensure that the data model is directly aligned with business objectives and KPIs.
- Modelstorming, which stands for prioritizing Business Intelligence over technical setup. The approach combines "modeling" and "brainstorming" that is performed in iterations–from a business challenge to implementing technology. In other words, the initial focus is on what business questions need to be answered, not how to achieve this technically.
- Visual modeling. BEAM presents complex processes and metrics in an easy and comprehensive way using timelines, charts, and grids.
- Agility. The BEAM framework is business-driven and agile. By prioritizing business needs, your EDW can quickly adapt to changes in project strategy and market conditions.
- End-user collaboration. End users are involved in the BEAM process, ensuring that data elements and structures actually meet real-world needs.
Common Data Model
Common Data Model is a set of standard schemas that includes data entities, attributes, and relationships. In other words, by using this framework, you can transform data from various databases into a common format (data model) and representation (terminologies, vocabularies, coding schemes). This standardization enables easy data exchange and integration across various systems, platforms, and applications. Apart from the unified format and consistency, the Common Data Model offers such advantages:
- Seamless data integration and disambiguation. The model simplifies the process of processing and decoding data from diverse sources, including processes, user interactions, etc.
- Wide customization capabilities. Within the Common Data Model, you can tailor a standard data model to align with your organization's needs.
Some examples of Common Data Models are Elastic's Common Schema (ECS) Reference, Microsoft's Common Data Model (CDM), OMOP Common Data Model for the healthcare domain, and Database Markup Language (DBML).
In conclusion, data modeling frameworks like Adapt, BEAM, and Common Data Models are indispensable tools for modern data-driven enterprises. With a trusted data analytics partner by their side, organizations can design and build the EDW to govern their data most effectively. N-iX's BI developers are seasoned in adopting robust data analytics, including the implementation of OLAP cubes and setting up reporting with Power BI, Pentaho, Tableau, and other systems.
Read more: From migration to optimization: Streamlining your database development workflow
Enterprise data warehouse components
Now that you are familiar with the components of an EDW architecture and the relationships between them let's explore the vital parts of the very enterprise data warehouses:
- Data sources span databases such as CRM and ERP, as well as flat files (CSV, Excel) and external data (market research, demographic data). They also might include streaming real-time data sets collected mainly from IoT devices.
- Staging area component is considered to be the intermediary space where raw data is first loaded before processing and moved to the main EDW storage. At this level, your data is aggregated, cleaned, and buffered to ensure its readiness for further processing.
- Presentation (access) space is the final layer where processed data is stored for end-user access. In other words, it is already an interface that enables analytics, reporting, querying, and data sharing.
- Data tool integrations or APIs are interfaces and tools for accessing the EDW data, such as BI solutions, query APIs, ETL tools, and data analytics engines like Hadoop or Spark.
Read also: What is the role of a data warehouse in Business Intelligence?
3 major types of EDWs
If you're thinking about implementing an EDW, another vital thing to consider is the hosting environment for your insightful data repository. Here are the options:
- Hosting your EDW on-premises means locating and running all the system's components within the organization's own data center. Such an approach offers complete control over data and system configurations. However, it comes with limited scalability and is less cost-effective than cloud or hybrid data warehousing.
- Unlike hosting on-prem, cloud-based EDW allows you to pay only for utilized resources instead of being responsible for buying and maintaining the infrastructure. In addition, cloud-based EDWs such as AWS Redshift, Snowflake, Azure Synapse Analytics, and Google BigQuery are highly scalable and flexible. Enterprises might adjust their cloud usage based on changing workloads and, as a result, remain cost-effective.
- Hybrid enterprise data warehousing stands for hosting some data or processes in-house for compliance or security, while other workloads are managed in the cloud for better scalability and flexibility.

Keep reading: Redshift vs Snowflake vs BigQuery: Which one to choose for your cloud data migration?
Enterprise data warehousing: Insightful business analytics delivered by N-iX
Let's explore how N-iX implements enterprise data warehousing solutions in different hosting environments with clients' business needs in mind:
Optimizing an on-premises Teradata EDW
Our client reached N-iX with a request to optimize their data warehouse that has been operating on Teradata on-premises platform for over 10 years. The platform had limited scalability and flexibility, as well as managed complex data processes, which could run for 10-15 hours. The client also needed to handle the growing volume of data and launch new ETL processes.
N-iX Data Analysts implemented optimal indexing and aggregation strategies and conducted systematic system upgrades, which boosted the system's scalability. Moreover, when setting up new ETL processes, we uploaded data from multiple sources, including SAP, MS SQL Server, Oracle, Kafka, and flat files to Teradata. Our engineers also implemented automated data uploading from those sources into Teradata and performed data transformation. Finally, we added a new calculation logic to the reporting, which allowed end users to access real-time business insights.
Our engineering efforts resulted in:
- Accelerated data processing: we were able to cut down data processing time from 15 hours to 6 hours;
- Increased platform's ability to handle large amounts of data related to optimization of the Teradata EDW.
Implementing a Snowflake-based EDW for a Fortune 500 industrial supply company
The project was delivered to a top US provider of industrial products. Its global customer base spans over 3.2M people interested in safety, material handling, and metalworking tools, along with services like inventory management and technical support. The key project task was to implement a complex big data platform that would collect information from all the business functions.
Our team has helped the client choose the optimal data warehousing solution. To compare the feasibility of Amazon Redshift and Snowflake platforms and choose the best option, we created a proof of concept. After deciding to move forward with Snowflake, we have managed to link the platform to more than ten different data sources. Currently, the largest table in our system contains up to 5 TB of data, while the overall Snowflake's storage capacity exceeds 20 TB. Each day, our ingestion process loads up to several dozens of GBSs from each data source.
The results of cooperation were:
- Seamless scaling capability and faster query performance related to Snowflake migration.
Building an AWS-based enterprise data warehouse for a top in-flight connectivity provider
Our client is Gogo, an industry leader in in-flight connectivity and entertainment with over 20 years of market presence. The key client's requests were to migrate its solutions to the cloud, build a unified data platform, and optimize in-flight Internet speed.
N-iX engineers have helped Gogo implement an AWS-based data platform, which could aggregate the data from over 20 different sources, such as plane logs and airborne logs. To facilitate the integration of a wide range of sources, we implemented and maintained a cloud-hosted data lake with the help of Amazon RDS, Amazon S3, Amazon Redshift, and Amazon EMR. The next step was to perform data migration and set up reporting using AWS Redshift as a data source. As a result, we helped Gogo implement a unified AWS-based EDW that could provide insights on the availability and in-cabin performance of various devices as well as analyze the operation of WAP points and other hardware.
The key business value for Gogo was:
- Significant decrease in operational expenses on penalties to airlines due to poor Wi-Fi performance;
- Streamlined data management, ensured by consolidating data from over multiple sources into a unified AWS-based EDW.
Developing an Azure-based EDW for a UK fintech company
This global leader in currency and asset management has over $80B in Assets Under Management Equivalents (AUME). The client had a legacy ROMP data system with an embedded reporting module, which no longer satisfied the business's needs in terms of customization, speed, and efficiency.
During an intensive discovery phase, we decided to implement a new data warehouse. The Azure Data Factory was used to connect to the client's existing ROMP system and transfer all 15 years of historical data. Our engineers took ownership of the implementation of the data warehouse as a service, including data replication, pipeline running, data retrieving, data transformation and arrangement of a new data model that is comfortable for reporting. We also transferred the existing data from the client's legacy system into Power BI and set up the connection with the data warehouse.
The project outcomes we’re proud of span:
- Real-time data reporting with a 1-hour maximum delay;
- Decreased operational costs spent on manual reporting and maintenance.
Implementing a GCP-based data warehouse for a leading managed service provider
The client is a leading managed service provider that provides personalized customer hosting solutions for reduced management complexity and IT resource strain.
The N-iX team worked with the client on several Big Data, Data Warehouse, and Data Quality projects. Managing the company's siloed data on-premises presented challenges regarding data governance, storage, accessibility, scalability, and more. Our responsibilities included creating a unified data warehouse on GCP, monitoring data warehouse migration from MS SQL Server to GCP, and automating various internal processes, such as monthly service reviews. Through data warehouse automation, we helped the client consolidate over 70 heterogeneous data sources, as well as migrate four data warehouses and one data lake to Google Cloud.
The cooperation resulted in:
- Significant cost reduction related to optimization of the client’s AIOps;
- Automation of internal processes that has further reduced manual intervention, improving the overall operational efficiency.
Wrap-up
Implementing an enterprise data warehouse can help enterprises reinvent the way they handle their business data if done correctly. The crucial factors to consider and align with your business needs before building your EDW are architectural structure, data modeling framework, and hosting environment.
An experienced data analytics vendor like N-iX can guide you throughout all phases of your journey. N-iX's deep expertise in Data Analytics and Business Intelligence, combined with a strong portfolio of EDW implementations across multiple domains, position us as a trusted partner for your data-driven transformation.

Have a question?
Speak to an expert


