
Are on-premise data warehouses dead? No, but with the rise of AI, IoT, 5G, data warehouse migration to the cloud is the most efficient way to ensure agility, security, and flawless performance. According to the MarketPulse survey by Matillion and IDG Research, 90% of respondents say that they have already performed partial cloud data warehouse migration.
Data is the new oil for businesses. Companies that generate petabytes of valuable data need to find the right place to store it. And when it comes to choosing a cloud-based data warehouse solution, it is challenging to find the one that suits your business case as there are a number of options available on the market.
A leading industry analyst firm Forrester has identified 13 cloud data warehouse (CDW) providers that shape the market. Let’s take a closer look at Snowflake vs Redshift vs BigQuery that are among the leaders. You will discover how each provider measures up and learn how to select the right data warehouse solution that suits your needs, based on real-life use cases.

Shortcuts:
- Why perform data migration to Redshift? [+case study]
- Why perform data migration to BigQuery? [+case study]
- Why perform data migration to Snowflake? [+case study]
- What are the key differences between Snowflake vs Redshift vs BigQuery? [infographic]
- How N-iX can help you choose between Redshift vs Snowflake vs BigQuery
Why perform data migration to Redshift?
Amazon Redshift is a fully-managed cloud data warehouse service offered by AWS that is built on PostgreSQL. It was initially created as a powerful alternative to Oracle (“red” is an allusion to Oracle, whose corporate color is red). If to compare Snowflake vs Redshift vs BigQuery, Amazon Redshift has the largest market share (18.7%), according to Enlyft. About 8,007 companies use it for cloud data management.
Redshift use cases:
- Business Intelligence: powerful reports and dashboards with the help of business intelligence tools.
- Operational Analytics: real-time operational insights on your applications and systems.
- Data sharing: secure and governed collaboration on data.
- Predictive Analytics: automatically created ML models.
Redshift competitive advantages:
- Familiar syntax: Amazon Redshift is based on industry-standard PostgreSQL. This means that migrating from an on-premises PostgreSQL server to Redshift will not require a lot of changes.
- Huge AWS ecosystem: Redshift is a solution created by AWS, which is the world’s leading cloud provider and has the most extensive service offerings. Amazon Redshift fits in perfectly with other AWS tools and services like Kinesis, S3, DynamoDB, EMR, etc.
- Redshift ML: This is a relatively new service by AWS announced in 2020 that allows users to create, train and deploy ML models within Redshift data warehouses using SQL syntax.
- Data lake support: At the end of 2020, AWS announced native support for JSON and semi-structured data. It is based on the new data type ‘SUPER’ that allows you to store the semi-structured data in Redshift tables. Redshift also adds support for the PartiQL query language to seamlessly query and process the semi-structured data. With a data lake built on Amazon Simple Storage Service (Amazon S3), you can easily run big data analytics using services such as Amazon EMR and AWS Glue. You can also query structured data (such as CSV, Avro, and Parquet) and semi-structured data (such as JSON and XML) by using Amazon Athena and Amazon Redshift Spectrum. You can also use a data lake with ML services such as Amazon SageMaker to gain insights.
- Partitioning: Redshift Spectrum allows users to aggregate data based on certain criteria and create partitions each of which has a separate location. It also ensures a quick and easy update of a single partition instead of updating the whole table that may be 100GB in size.
Explore more: How to build a successful data center consolidation strategy
Featured case study #1: End-to-end development of a big data platform for Gogo
Gogo is a leading provider of in-flight connectivity and entertainment with over 20 years of experience. The company needed a qualified engineering team to undertake a complete transition of Gogo solutions to the cloud, build a unified data platform, and streamline the best speed of the in-flight Internet.
The N-iX team has helped the client develop the data platform based on AWS that aggregates all the data from over 20 different sources. There are two main directions on the project. The first one is ingestion and parsing of airborne logs as the team receives a colossal number of logs from the planes - up to 3 TB a day. The task was to develop a flexible parser that would cover most of the client`s cases. For this purpose, we needed to normalize logs in a single structure (a table or a set of tables). Based on our experience, we configured Amazon Kinesis Streams to use the optimal number of shards per app, per user, per consumer, and producer, so there was no throttling. Our team measures the Iterator Age metrics and metrics that showcase the delay of Amazon Kinesis Streams through Kinesis UI.
Another direction is the integration of a variety of data sources to build reporting and analytics solutions that bring actionable insights. We built and supported the data lake on AWS with the help of Amazon RDS, Amazon S3, Amazon Redshift, Amazon EMR. Our engineers have made an end-to-end delivery pipeline: from the moment when the logs come from the equipment to the moment when they are entirely analyzed, processed, and stored in the data lake:

Application log tables and metadata processing are stored in Amazon RDS. We use Amazon EC2 to run custom Finch applications and long-running acquirers. AWS Lambda functions are used to process the notifications, Amazon S3 — to store raw as well as processed files, dimension and fact tables, backups, and application logs. We use Amazon DynamoDB to store data on the processing status of bundles — tar logs from aircraft. Amazon Redshift stores in-memory data warehouse. Also, it is used as a data source for our reporting team. Besides, we use Redshift Spectrum that can directly query data stored across S3 buckets.
We chose Amazon VPC for cloud infrastructure as a service since it allows building scalable and secure data transferring. Gogo uses Athena for data analytics, Amazon EMR for data processing, namely for writing ETL in Spark and Spark Streaming. We use Amazon Kinesis to
transfer processed data from EC2 to S3. Amazon IAM allows us to create and manage AWS users and groups and use permissions. Amazon CloudWatch collects the performance and operational data in the form of logs. Lambda function is triggered by using Amazon SNS notifications. Amazon SQS manages message queues and is used by custom applications.
As a result, we have built a data lake from scratch for collecting data from all sources in one place and delivered a solution for measuring availability and in-cabin performance of various devices as well as analyzing the operation of WAP points and other equipment. Our solutions allow Gogo to significantly reduce the operational expenses on penalties to airlines for the ill-performance of Wi-Fi services.
Why perform data migration to BigQuery?
BigQuery is a cloud data warehouse solution offered by GCP. It has a market share of about 12.5%, according to data by Enlyft. And over 5,000 companies use it for data storing and analysis. BigQuery has no virtual machines, no setting keys or indexes, and no software. You don’t need to deploy multiple clusters and duplicate data into each one. It has separate storage and computing.
BigQuery use cases:
- Data warehouse migration: Bringing data from Netezza, Oracle, Redshift, Teradata, Snowflake, etc. to BigQuery to speed up your time to insights.
- Predictive analytics: Predicting future outcomes and discovering new opportunities with the help of a built-in ML solution and integrations with Vertex AI and TensorFlow.
- Data consolidation: Gathering data in BigQuery from multiple sources for seamless analysis. You can upload CSV, AVRO, JSON, ORC, Parquet and make use of BigQuery Data Transfer Service (DTS), Data Fusion plug-ins, or Google's industry-leading data integration partnerships.
BigQuery competitive advantages:
- A fully managed service: You don’t need to worry about upgrading, securing, or managing the infrastructure as Google does all backend configuration and tuning for you.
- High availability: BigQuery automatically replicates data between zones with no extra charge and no additional setup.
- Native streaming: BigQuery provides a native streaming API for a small fee.
Featured case study #2: Improving data management for a global provider of managed cloud services
Our client is one of the leading managed service providers. They help companies reduce management complexity and strain on IT resources with white-glove, personalized customer hosting solutions.
All of the company’s siloed data was managed on-premises that caused issues with data governance, storage, accessibility, scalability, and more. The client engaged the N-iX team to work in several areas of Big Data, Data Warehouse, and Data Quality. We are responsible for the development of a unified data warehouse on GCP, quality assurance for a data warehouse migrated from MS SQL Server to GCP, and automation of various internal processes, such as monthly service review. Our experts have helped the client consolidate 74 operational data sources and migrate 4 data warehouses and 1 data lake to Google Cloud.
The client had an AIOps solution that had been working for a year. The company had over 40 data centers around the world, managing 100s of 1,000s of customers' virtual machines. Thanks to the advancement of AIOps, the client was able to automate the resolution of over 60% of all initiated tickets. However, it was too expensive, thus they needed a more cost-effective alternative solution. As a result, the client has managed to consolidate 320 dashboards into 20 centrally managed, high-quality resources and decommission 20 servers, leading to more than 1M dollars in savings on MS SQL Server licenses alone.

Why perform data migration to Snowflake?
Snowflake is one of the most popular cloud-based data warehouses provided as SaaS. There is no hardware or software for developers to install, configure, or manage. The main concept of Snowflake architecture is that it separates compute resources from data storage. Compute resources are represented as virtual warehouses that physically are the clusters and can be resized at any time. As data by Enlyft states, Snowflake accounts for 14% of the market. 6,250 companies across the globe have chosen it for cloud data management.
Snowflake use cases:
- Data warehouse modernization: Building a data platform to enable effective reporting, analytics, and management of structured data.
- Modern data lakes: Snowflake goes far beyond data warehousing and offers support for semi-structured data such as JSON, Avro, ORC, Parquet, and XML.
- Secure data sharing: Snowflake enables sharing of database tables, views and user-defined functions (UDFs) using a Secure Share object.
- Modern data application development: Developing data-intensive applications that scale cost-effectively and consistently deliver fast analytics.
- Integrated data engineering: Building simple, reliable data pipelines in the language of your choice.
- Advanced data science: Simple data preparation for modeling with your framework of choice.
Snowflake competitive advantages:
- Time-travel: This feature enables accessing modified data at any point within a defined period. It serves as a powerful tool for performing the following tasks:
- Restoring data-related objects (tables, schemas, and databases) that may have been accidentally or intentionally deleted.
- Duplicating and backing up data from key points in the past.
- Analyzing data usage/manipulation over specified periods.
- Zero copying: This feature is valuable for quick-testing of modifications on big tables. Data can then be inserted, deleted, or updated in the clone independently from the original table. Each change to the clone causes a new micro-partition that is owned by the clone. Later, changes in the original table are not taken over to the clone.
- Masking policy: Snowflake supports masking policies as a schema-level object to protect sensitive data from unauthorized access while allowing authorized users to access sensitive data at query runtime.
- Real-time loading of data by using Snowflake pipes: It enables loading data from files as soon as they’re available in a stage. Snowflake has two different mechanisms for detecting the staged files: Automating Snowpipe using cloud messaging or Calling Snowpipe REST endpoints.
Featured case study #3: Scalable big data analytics platform for a leading industrial supply company
Our client is a Fortune 500 industrial supply company. It offers over 1.6M quality in-stock products in such categories as safety, material handling, and metalworking. The company provides inventory management and technical support to more than 3M customers in North America.
The client needed to transform its existing on-premise data solution and move it to the cloud to ensure better scalability, improve reliability, and reduce costs. N-iX has helped the client migrate from the on-premise Hadoop Hortonworks cluster to AWS and build a unified big data analytics platform on AWS with the help of Snowflake, Airflow, Terraform, Teradata, Tableau.
We managed to integrate more than 100 different data sources into a unified data platform. This includes daily data loads, along with a backfill of historical data. We are working with TBs of data tables, and the size is growing. We compared Amazon Redshift with Snowflake and preferred Snowflake as it meets all the project requirements. As a Snowflake consutling partner we chose it because of these benefits:
- No vendor lock-in: Snowflake is a cloud-agnostic shared-data solution that is compatible with any cloud provider.
- Seamless scaling capability: Snowflake can allocate as many virtual DW's as necessary, size as needed, and shut down on idle or on a schedule.
- A fully-managed solution: Snowflake has more automated maintenance than Redshift.
- Cost-efficiency: We have estimated that for our use case, Snowflake is 1.6 times more cost-effective than Amazon Redshift.
- Great performance: Snowflake processes queries 10 times faster than the Hadoop cluster.

The use of Snowflake and Airflow technologies allows us to automate the data extraction process. Also, Snowflake minimizes data duplication by checking whether the ingested files have been already processed or not.
What are the key differences between Snowflake vs Redshift vs BigQuery?
To figure out which solution is the best cloud data warehouse for you, let’s take a look at offerings provided by Snowflake vs Redshift vs BigQuery.
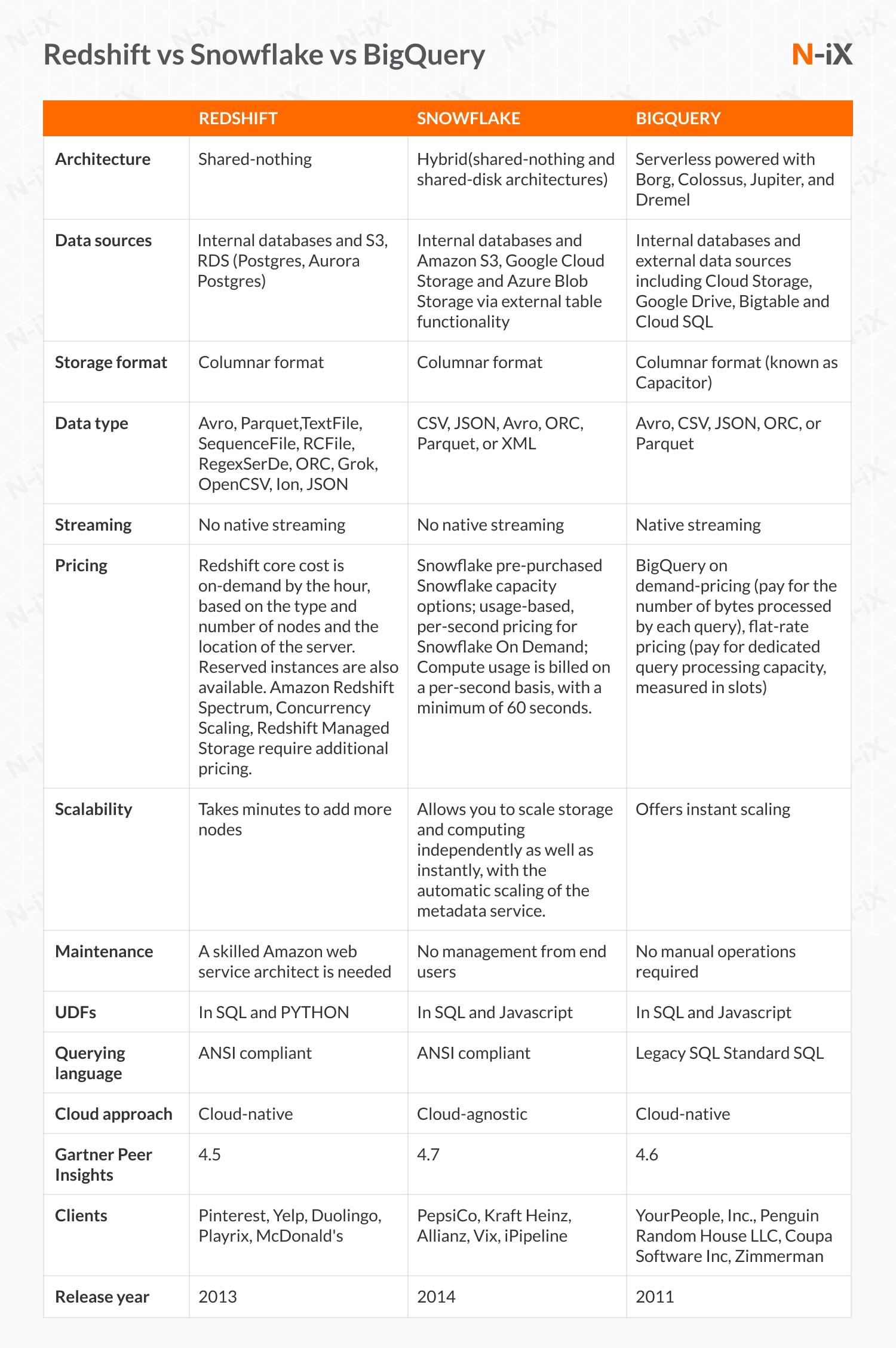
How N-iX can help you choose between Redshift vs Snowflake vs BigQuery
- N-iX is a certified AWS Advanced Consulting Partner, a Microsoft gold certified partner, a Google Cloud Platform Partner, an Opentext Services silver partner, and a Silver SAP partner.
- N-iX boasts a pool of 2,400+ tech experts ready to support you in every stage of your data warehouse migration project.
- N-iX specialists have a proven track record working with cloud-based tools such as Snowflake, Redshift, BigQuery, EMR, Dataproc, Cloud Composer, Synapse Analytics, Azure Data Factory, Databricks, etc.
- N-iX has built successful partnerships with Lebara, Gogo, Vable, Orbus Software, and many other leading companies and helped them leverage the benefits of the cloud.
- N-iX experts have solid expertise in Big Data engineering, Data Science, ML&AI, BI, Cloud, DevOps, and Security.
- N-iX offers Discovery Phase as a service to help companies validate their product idea, choose a tech stack, estimate ROI, and build a feasible prototype.
- The company complies with international regulations, including ISO 27001:2013, PCI DSS, ISO 9001:2015, GDPR, and HIPAA, so your data will always be safe.
- N-iX is trusted in the global tech market: the company has been listed among the top software development providers by Clutch, in the Global Outsourcing 100 by IAOP for 6 consecutive years, recognized by GSA UK 2021 Awards, included in top software development companies by GoodFirms.co, and others.
- N-iX has been recognized by ISG as a Rising Star in data engineering services for the UK market and positioned in the Product Challengers Quadrant both in the data science and data Infrastructure & cloud integration services.


