
Data mesh, a relatively new concept in data architecture, improves data accountability and ownership and makes it easier to both produce and consume. Many leading global enterprises such as Netflix and Intuit have fully embraced it as part of their data transformation process.
However, just as with any new technology or principle, data mesh adoption is not without its challenges. Should you use it instead of a traditional data lake approach? What is the difference between data lake vs data mesh? And what can you do to make sure you get it right? We will explore all of this in this article.
Data lake vs data mesh: what is the difference?
So, what is the difference between data lake vs data mesh? A data lake is a centralized model of data delivery, where all data is collected, processed, and managed in a single platform. Each team involved in the data delivery pipeline can access, manipulate, and analyze all data stored in the data lake. This approach relies on well-defined enterprise data integration patterns to ensure data can still be shared and correlated between domains effectively. Operational optimization is the main draw of this type of architecture, as managing a single platform is both easier and more cost-effective.
However, all data teams contributing and working with the same data can often lead to ownership and accountability challenges that are difficult to mitigate. For instance, it is not unlikely for one team to alter the data they work with. At the same time, they may not be fully aware of the specific needs of another team that has to work with the same data. As a result, they can impact that team’s work without even knowing about it. This, in turn, can lead to various issues, such as inconsistent analysis or ineffective decision-making.
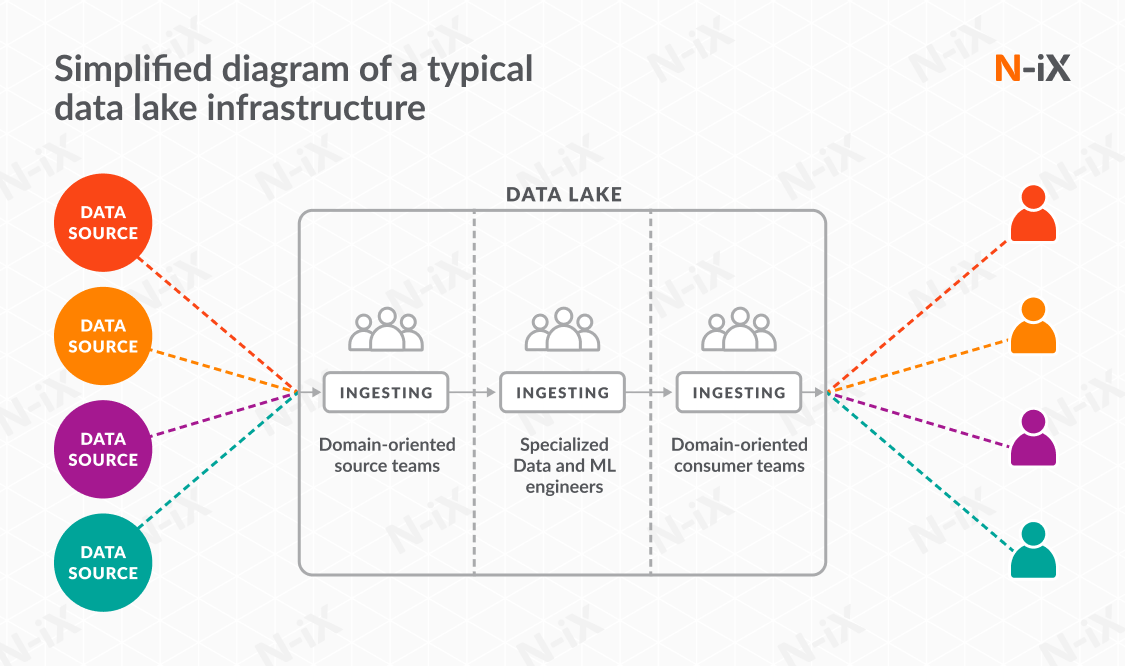
Access to data is the main difference between data lake vs data mesh. Instead of a single platform, a typical data mesh architecture consists of separate autonomous teams that prepare their own data and do not have access to other data besides their own. A central data governance unit led by a single data steward or a team of such specialists is responsible for distributing data access between the teams. When the need arises, teams copy each other’s data and use it in their own system, leaving the original data unaffected.
Each team in a data mesh architecture has complete ownership of their data preparation process. This decentralized, sociotechnical approach is a key differentiator in the data mesh vs data fabric architectural choice, as it empowers domain teams to treat their data as a product. These teams treat their data as a product to be delivered, choosing the technologies and tools they use, completing testing and fixing, and ensuring security.
Data meshing is not without its challenges, however. When dealing with such architecture you have to be prepared to handle data duplication which will inevitably occur as it is copied between the teams.

Key advantages of data meshing
So, what tangible benefits does the use of data mesh architecture bring as compared to data lakes? Let’s take a closer look.
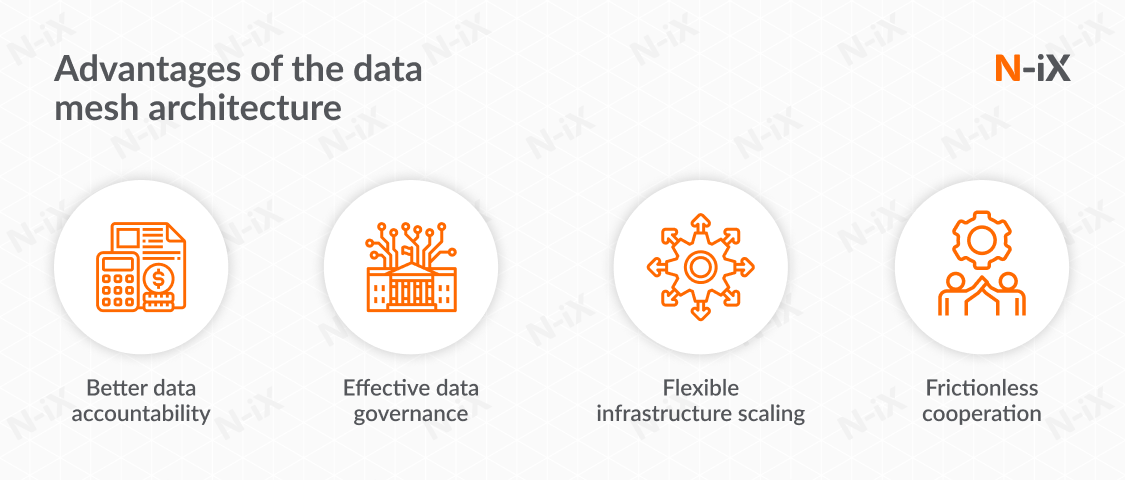
Improved data accountability and management
As mentioned earlier, each team within a data mesh infrastructure is solely responsible for the data they produce, serving as domain experts of said data. They are responsible for the quality of data they provide, making sure it is both accurate and easy to consume.
This makes data management a lot more effective and less time-consuming. Every team is aware of where they can obtain the data they need and who is in charge of fixing any inconsistencies or discrepancies that occur.
Effective data governance
The sole responsibility of a data governance unit is the effective distribution of data access. The data governance team creates a detailed catalog by exploring all sources and types of data. This catalog is used as a guideline to provide each team with access to the data they need.
Requests from one team to access and copy the data produced by another team go through the governance unit which has to review and approve it. This ensures effective data distribution since the infrastructure has a single entity that has a clear view and can control how all data is distributed, as well as who can (and should) use it.
Flexible infrastructure scaling
Scalability is one of the main challenges of normal data lakes. Since the entire infrastructure has to go through the process, scaling a data lake can often be slow and burdensome. This is not the case for distributed data mesh infrastructure. A distributed system allows each team to scale separately and independently of others. As a result, the scaling process of such systems is quicker, easier, and more cost-effective. Furthermore, it boosts the effectiveness of your teams, as they do not have to rely on scaling of the entire infrastructure and can apply it to their own autonomous system as soon as they need.
Frictionless cooperation between teams
Finally, the principle of teams working independently creates an environment of effective and frictionless cooperation. Each team enjoys a smooth working process without any outside interference, allowing them to be in full control of their data. Any alterations made are communicated to the entire team, and no changes occur without the team being aware of them.
Learn more: Snowflake data mesh: Architecture, benefits, and implementation
Best practices to get the most of data mesh
Since data meshing is a relatively new concept, getting it right from the get-go may be challenging. However, following these best practices will help you get it right.
Make sure data meshing is right for you
While data mesh has a lot to offer, it is definitely not for everyone. Large enterprises that have access to lots of diverse sources of data with new ones being added at a fast pace can benefit greatly from distributed data mesh systems. Without having to rely heavily on the work of others, all teams can ensure effective data exchange and smooth cooperation between one another. A centralized data lake, on the contrary, could slow down data delivery and make your teams less effective.
Small and medium-sized businesses that have an unchanging data landscape, on the other hand, could make do with a centralized data lake infrastructure. There is simply no need to design a complex architecture divided into multiple branches when everything can be accomplished by a single specialized team.
A good rule of thumb here is to analyze the number of data domains that are within your organization. Assess how many of your teams (marketing, sales, etc.) drive their decision-making using data, how many products you have, and how many data-driven features you are developing. The higher the number - the more opting for a data mesh architecture makes sense.
Additionally, unless your organization is experiencing very rapid and significant changes, migrating from one type of infrastructure to another is almost never worth it. It is usually a long and costly process that hardly ever yields the benefits that outweigh the time and expenses put into it.
Establish strong data governance
Successful operation of a distributed data mesh infrastructure relies heavily on the expertise of your data governance team. Since this entity is solely responsible for creating guidelines and distributing accesses throughout the entire data pipeline they must have a very clear and detailed understanding of how it works. Therefore, it is crucial for the data governance team to consist of some of the most experienced data experts you have available, such as system architects, tech leads, etc.
Obtain experienced DevOps engineers
Experienced DevOps engineers play a significant role in setting up and optimizing the data delivery infrastructure. This is especially important for distributed infrastructures such as data mesh, where teams that work separately must have efficient ways of delivering and exchanging their data.
The skillset of an experienced DevOps engineer should include:
- Automation and orchestration. Ansible, Bash, Chef, Docker Swarm, Kubernetes, PowerShell, Puppet.
- Continuous integration and delivery (CI/CD). AWS, Azure DevOps, Bitbucket Pipelines, CodeDeploy/CodePipeline, Jenkins Pipelines, TeamCity.
- Cloud platforms. AWS, Azure, Google Cloud, Digital Ocean.
- Infrastructure as a Code (IaC). AWS CloudFormation, Azure Resource Manager, Helm, PowerShell, Terraform.
- Monitoring and logging. AWS CloudWatch, DataDog, ElasticSearch, Grafana, Kibana, Nagios, Prometheus, Splunk, Zabbix.
- Infrastructure security. AWS SG, AWS WAF, Azure Firewall and Application Gateway, Azure NSG, Cisco ASA, OSSEC, Snort, Suricata.
Continue reading: How to hire DevOps engineers: tips, locations, success stories
Form a partnership with a reliable tech vendor
Finding experts with enough expertise is one of the biggest challenges of implementing a data mesh infrastructure, especially if you limit yourself only to the local talent pool. Therefore, it is a good practice to expand your view to other markets and look for technical partners abroad who can help you obtain the right experts.
Since projects like this require broad technical expertise, you need to thoroughly analyze your potential partner’s expertise to make sure they will be up for the task. Your partner must be able to show solid experience in the following:
- Data engineering, with a strong data team and experience in data analytics and big data;
- Cloud development, with official partnership certifications to prove their expertise: AWS Consulting Partner, Google Cloud Partner, and Microsoft Partner;
- DevOps expertise, with a team of experienced engineers that have a proven record of delivering DevOps projects.
Wrap up
Data mesh is a new concept to data delivery that many are eager to try out. However, it is important not to jump on the bandwagon and only opt for this type of architecture if it fits your organization.
In fact, the main takeaway of the data lake vs data mesh comparison is that neither methodology is superior. Moreover, both of them can effectively coexist and complement one another within a single infrastructure. Indeed, it is not uncommon for individual branches of a data mesh architecture to include a centralized data lake where the team collects and processes their data. Since each methodology has its own set of advantages and challenges it can shine under proper conditions.

How can N-iX help you with implementing data mesh?
- N-iX has over 23 years of experience forming technical partnerships with leading global enterprises, such as Gogo and Lebara;
- We have a solid Data unit with over 200 skilled data experts;
- N-iX has over 40 DevOps engineers who have successfully delivered over 50 projects of varying complexity;
- N-iX is the Advanced Amazon Partner, Microsoft Gold Partner, and Google Platform partner, proving its strong expertise in cloud native services.
References
- Data Movement in Netflix studio via Data Mesh. By Medium.
- What is a data mesh - and how not to mesh it up. By TowardsDataScience
Have a question?
Speak to an expert


