
In July 2024, a mistake involving CrowdStrike's cloud-based testing system during update validation check caused what's now referred to as one of the largest IT outages in history. This incident crashed over 8.5M systems globally and cost Fortune 500 companies over $5B in direct losses alone [1]. Post-incident reviews stated that the root cause was not a technology failure but a breakdown in risk management in software engineering.
That story will be familiar to anyone who has shipped software at scale. The names and numbers change, but the pattern doesn’t: a risk that was visible, a process that was absent or bypassed, and a cost that arrived all at once. What separates organizations that avoid these outcomes from those that don't is rarely talent or budget. It’s whether risk management is treated as a structured discipline or an afterthought.
This guide is written for CTOs, digital transformation officers, and business owners who are responsible for software delivery and its consequences. It covers the risk types that cause the most damage and provides expert tips on building a risk management process that holds up under real project pressure.
Key takeaways:
- Most software failures share the same root causes: poor change management, single points of failure, untested assumptions, and known unmanaged risks.
- Proactive risk management costs a fraction of reactive damage control.
- Risk management has a few core steps: identification, analysis and assessment, planning, mitigation and control. Each one may become a point of failure if skipped.
- There are several risk categories in software engineering: schedule, budget, technical, operational, security, people, stakeholders, external, and AI-related. Each requires a different response strategy.
What is risk management in software engineering?
Risk management in software engineering is the structured process of identifying, assessing, and responding to threats that could compromise a software project's timeline, budget, quality, or security. It runs continuously throughout the software development lifecycle and covers technical, operational, people, security, external, and AI-related risks. The goal is not to eliminate uncertainty, which is impossible, but to ensure the team sees it coming and has a plan when it arrives.

Why risk management matters in software projects
Software development is unpredictable by nature. Requirements may change, teams may turn over, and what looked like a manageable assumption in month one becomes a crisis in month six. That uncertainty is not a sign of poor planning but a baseline condition of every software project. The risk management process in software engineering matters because it’s a structured way to stay ahead of that uncertainty rather than react to it. Done right, it can benefit your processes and organization.
Explore further: Software product engineering: how to do it right
Top benefits of risk management in software engineering
The benefits of risk management in software engineering show up where they count most: budgets, timelines, security, and trust.
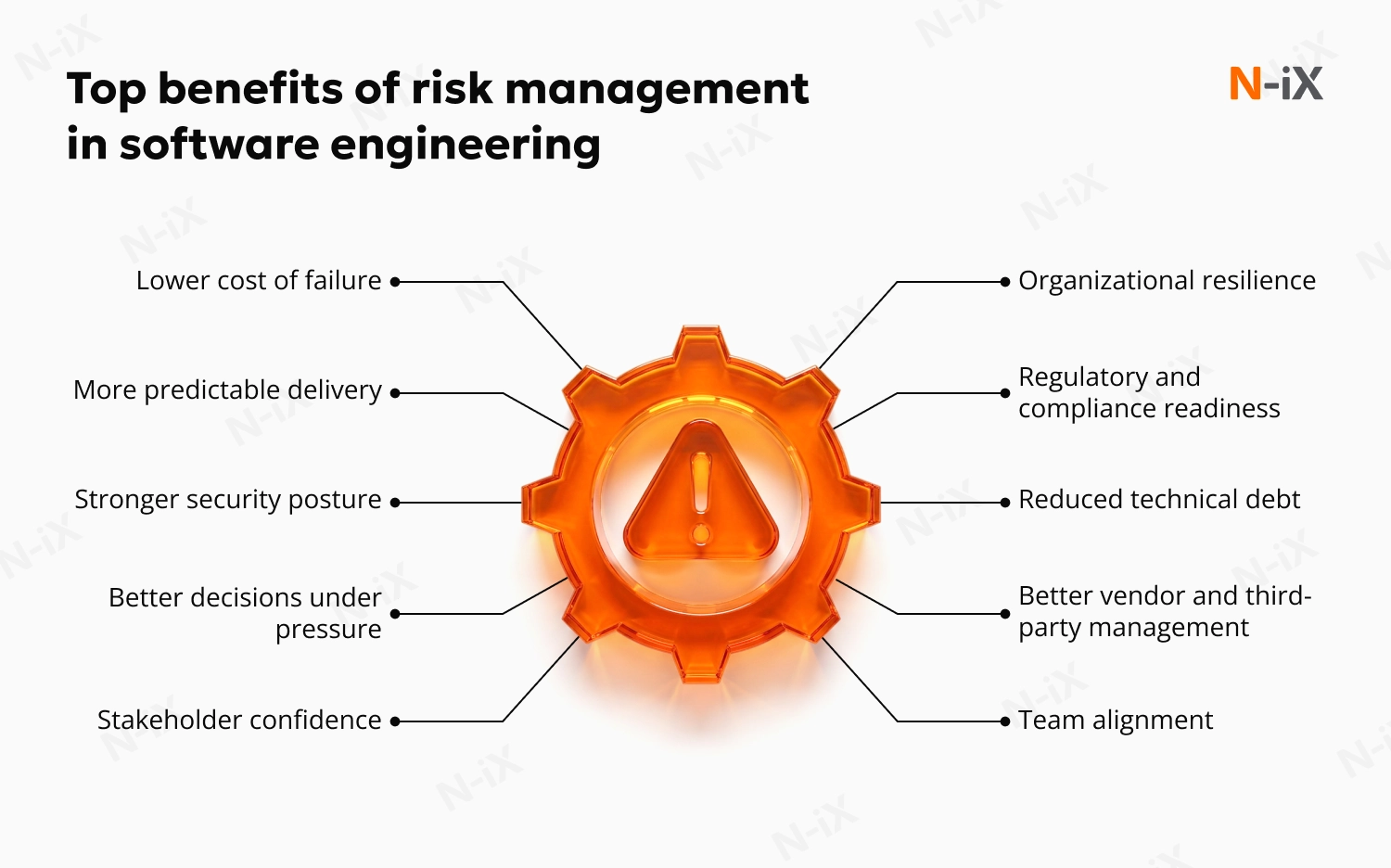
Lower cost of failure
Every stage of development adds more people, more dependencies, and more code built on top of earlier decisions. A risk caught during requirements involves one conversation between two people. The same risk surfaced during testing pulls in developers, QA, project managers, and stakeholders, and requires unpicking work built on the assumption that the risk did not exist. By the time it reaches production, you are also dealing with end users, support teams, and potential contractual consequences. Risk management in software engineering catches issues early, when the blast radius is still small.
More predictable delivery
Missed deadlines rarely come from nowhere. They come from risks that were visible weeks earlier in a form of dependency that was never confirmed, a scope assumption that was never validated, or a resource allocated to two projects at once. Risk management forces those assumptions into the open early enough to act on them. And while it doesn't eliminate surprises, it significantly reduces how often they catch you off guard.
Stronger security posture
Proactive risk assessment catches vulnerabilities before they become incidents. This matters more every year to US markets, where the average cost of data breaches increases annually, rising from $9.36M in 2024 to $10.22M in 2025, according to IBM's Cost of a Data Breach Report 2025 [5].
Better decisions under pressure
When something goes wrong, the difference between a controlled response and a crisis is whether the risk was already mapped. Teams with documented risk ownership know immediately what failed, who should respond, and what the contingency plan is. As a result, risk management in software engineering leads to more calculated decisions and less chaos.
Stakeholder confidence
Boards, investors, and clients do not expect projects to be risk-free—they expect teams to know what the risks are and have a plan to mitigate them. A team that says "here are our top five risks, here is what we are doing about each, and here is what we will do if they materialize" earns a different level of trust than one that reports everything is on track until it suddenly is not. That trust translates directly into faster approvals, more flexible timelines when needed, and longer-term relationships.
Organizational resilience
A team that has mapped its risks doesn’t collapse when one of them materializes. Organizations with a risk management plan in software engineering absorb the hits without losing momentum because they anticipate them and have protocols to follow.
Team alignment
A shared risk register makes risk visible across engineering, operations, and business leadership. It replaces assumption with shared ownership.
Explore the top 15 software engineering companies for enterprise tech projects in 2026
Regulatory and compliance readiness
Organizations with mature risk management processes treat compliance as a byproduct of good practice rather than a separate workstream triggered by an audit. That is a structural cost and reputational advantage over competitors who react rather than prepare.
Reduced technical debt
Technical debt accumulates when teams take shortcuts under pressure. Most of that pressure comes from unmanaged risks that materialize late in delivery. When risks are identified and planned for early, teams make deliberate architectural decisions instead of reactive ones, because the trade-offs are visible before a deadline forces their hand. The result is code that was built with known constraints in mind rather than patched around surprises.
Explore our detailed guide on how to reduce technical debt
Better vendor and third-party management
Risk processes that extend to suppliers and partners close one of the most common blind spots in software delivery. If your tech vendor routinely follows the same risk management practices, it becomes easier to prevent or mitigate issues.
To prepare for the risks, your software engineering team should know the common risks it may encounter. Here are a few ones you can anticipate and prepare for.

Types of risks in software engineering
Software projects are uniquely risk-prone: the output is intangible, requirements evolve as stakeholders learn, and technology dependencies introduce failure points outside the team's control. Moreover, modern delivery increasingly involves AI workflows and distributed teams across geographies and organizations, further complicating the picture.
A useful model for categorizing what you're dealing with:
- Known knowns: Risks the team has identified and documented (e.g., a tight delivery deadline with no contingency buffer);
- Known unknowns: Risks the team is aware of in principle but cannot fully quantify (e.g., a third-party API that may introduce breaking changes);
- Unknown unknowns: Risks that don't appear on anyone's radar until they materialize, often as incidents.
A mature risk management in software engineering systematically reduces the unknown-unknown surface area by building institutional memory, structured review cadences, and cross-functional visibility into every stage of delivery.
The risks in software development also vary by project, team, and context, but they typically fall into several categories:
- Schedule and timeline risks: Delays caused by underestimated complexity, shifting priorities, or unplanned dependencies that push delivery beyond agreed deadlines;
- Budget and cost risks: Financial overruns driven by scope creep, inaccurate estimation, or unplanned rework that erodes project margins and stakeholder confidence;
- Technical risks: Vulnerabilities in architecture, technology choices, or integration points that can compromise system performance, scalability, or stability;
- Operational risks: Failures in day-to-day processes, including deployment pipelines, incident response, or change management, that disrupt delivery or production systems;
- Security and data risks: Exposure to cyberattacks, data breaches, or compliance violations that carry financial, legal, and reputational consequences;
- People and team risks: Skill gaps, key-person dependencies, team turnover, or misaligned responsibilities that quietly undermine delivery capacity;
- Stakeholder and requirement risks: Unclear, incomplete, or frequently changing requirements driven by misaligned expectations between business and technical teams;
- External vendor and supplier risks: Factors outside the team's control, such as regulatory changes, vendor failures, market shifts, or geopolitical events that may affect project viability.
With the rise of AI-assisted development, AI-related risks deserve a special mention as they affect quality and security.
AI-related risks in software development
AI-assisted development is now standard practice. According to the 2025 Developer Survey by Stack Overflow, 51% of professional developers use AI development tools daily [2]. That adoption rate brings a distinct class of software development risks that most risk registers still do not adequately address. Without proper management and AI usage policies, AI may boost developer productivity but also introduce new risks at scale.
Risks of AI-assisted software development in 2026:
- Hallucinated or insecure code: AI tools generate plausible but incorrect or vulnerable code that passes casual review.
- IP and copyright exposure: There's still unresolved legal uncertainty around ownership of AI-generated output.
- Skill erosion: Over-reliance on AI generation may reduce engineers' ability to reason through complex problems independently.
- Agentic AI projects stall: As Gartner predicts, 40% of agentic AI projects will be cancelled by 2027 due to increasing costs, uncalculated business value, or inadequate risk controls [3].
- Compliance blind spots: AI tools are trained on data that may not meet organizational or regulatory standards, including those under the EU AI Act.
- AI use for cyberattacks: In November, 2025, Anthropic reported on disrupting an AI-orchestrated espionage campaign in which a threat actor used AI to execute up to 90% of tactical operations independently [4].
Understanding the risk management types in software engineering is a prerequisite for managing them effectively and building a working risk management process. You should also determine whether you’re taking a reactive or proactive approach to deal with those risks.
Proactive risk management in software engineering vs reactive risk management in software engineering
Reactive risk management refers to dealing with the incidents that have already happened. They may not always be a development team's failure: unknown unknowns will always materialize as incidents regardless of how rigorous the upfront process is.
Proactive risk management in software engineering focuses on predicting potential issues and preventing them from occurring or minimizing their impact, so that when reactive responses are required, they don’t consume the entire engineering team and derail delivery.
|
Proactive |
Reactive |
|
|
Timing |
Before risk materializes |
After risk has become an issue |
|
Cost |
Lower (prevention is cheaper) |
Higher (dealing with materialized issues is expensive and disruptive) |
|
Primary tools |
Risk register, threat modeling, sprint reviews |
Incident response plans, hotfixes, emergency escalations |
|
Culture signal |
Risk-aware by default |
Crisis-driven |
The most effective teams run both in parallel: disciplined proactive planning to handle everything predictable, and a well-rehearsed incident response process for everything that isn't.
Step-by-step risk management process in software engineering
The risk management steps in software engineering typically follow four phases. They should be repeated continuously throughout delivery.
1. Risk identification
The goal is to surface everything that could plausibly threaten the project. Key techniques include:
- Structured brainstorming with the full project team (developers, architects, security leads, QA, etc.);
- Expert interviews with domain specialists and past-project retrospectives;
- Historical data review from similar previous projects;
- SWOT analysis at the project and component level;
- Checklist review against a standard software development risks list updated for the current threat context.
The output is a risk register, a living document with an entry for each identified risk. It contains ID, description, probability rating, impact rating, assigned owner, planned response, and current status. This is not a spreadsheet filed at kickoff; it’s the operational backbone of the risk management process.
One dimension that no template captures is culture. If raising a concern feels risky, engineers will self-censor, and the register will look clean while the project accumulates hidden exposure. The most valuable risks to surface are often the most uncomfortable to name: a vendor relationship that depends on one contact, an architectural decision nobody is confident in, or a stakeholder who approved the scope but has not truly bought into it. In this case, you should use structured sessions, anonymous input mechanisms, and cross-functional reviews to surface issues that individuals might not raise in open meetings.
2. Risk analysis and assessment
Not every identified risk deserves the same attention. Assessment involves evaluating each risk on two dimensions: the likelihood it will occur and the impact it will have if it does. The combination of these two factors determines a risk's priority.
A simple risk matrix plotting likelihood against impact gives teams a visual, shared understanding of where to focus. High-likelihood, high-impact risks demand immediate planning. Low-likelihood, low-impact risks can be monitored without active intervention.
For high-stakes or safety-critical projects in fintech or healthtech, or those involving embedded systems, quantitative methods such as Monte Carlo simulation or decision tree analysis are applicable when timeline or cost variances require numerical modeling.
Three additional methodologies are worth knowing for specific contexts:
- Failure Mode and Effects Analysis (FMEA) assigns each potential failure a severity, probability, and detectability score to produce a Risk Priority Number. It’s the standard approach for safety-critical software in medical devices, automotive, and industrial control systems.
- Corrective and Preventive Action (CAPA) is a structured process for addressing root causes of issues that have occurred and conditions that could cause future ones. In regulated industries like healthcare, manufacturing, finance, and others, it’s an audit requirement; elsewhere, it’s an alternative to informal post-incident learning.
- Risk Breakdown Structure (RBS) is a hierarchical decomposition of risk categories used primarily to ensure nothing is missed during identification.
Most software teams outside regulated domains will not need all three. But teams building systems where failure carries physical or legal consequences should integrate FMEA and CAPA from the start.
3. Risk management planning
For each prioritized risk, the team defines a specific response strategy. There are several risk management strategies in software engineering:
- Avoid: Change the plan to eliminate the risk source entirely (e.g., swap an unproven third-party dependency for a mature alternative);
- Mitigate: Reduce the probability of occurrence, the impact if it occurs, or both (e.g., add automated integration testing to catch API breakage early);
- Transfer: Shift the risk to a third party through insurance, contract terms, or formal outsourcing arrangements;
- Accept: Document the risk, assign an owner, and monitor it (appropriate for low-priority items where mitigation cost exceeds the potential impact).
The output of this step is a risk management plan in software engineering, a documented set of response actions, owners, triggers, and escalation criteria for every significant risk on the register.
A risk plan is only useful if it stays connected to the project as it evolves. Risk traceability means linking each significant risk to the requirements, components, or test cases it affects. This way, when scope changes, relevant risk owners are notified automatically rather than discovering the connection after deployment. In regulated industries such as healthcare and fintech, traceability is an audit requirement under standards including ISO 14971 and IEC 62304.
4. Risk monitoring and control
Risks are reviewed at every sprint review and tracked on a dashboard visible to the full team and relevant stakeholders. Escalation thresholds are defined upfront: if a risk's probability or impact rating changes, it triggers an automatic escalation to the project manager or other designated person.
Effective risk management in software engineering requires observable signals, not just status updates. Performance risks should have latency thresholds configured in your monitoring system. Security risks tied to dependencies should be tracked through automated scanning in the CI/CD pipeline.
At the project level, a risk burndown chart (i.e., a sprint-by-sprint plot of aggregate risk exposure) shows whether mitigation is actually working. If the curve is not declining, decisions need to be made before the project is locked into a bad trajectory.
You may also embed a release revert policy. It's a pre-agreed protocol to roll back a deployment if a defined error rate threshold is breached post-release, before customers are affected at scale. It helps the team react to the incident without delays.
Following the risk management steps in software engineering helps achieve the abovementioned benefits. Let's explore an example of how it may look in practice.
Risk management in software engineering example
Consider a mid-size fintech company beginning a twelve-month core banking system migration. At the risk identification session, the team agreed to the following:
|
Risk ID |
Description |
Likelihood |
Impact |
Owner |
Response |
|
R-01 |
Legacy data schema incompatibility with a new platform |
High |
High |
Lead Architect |
Mitigate: Run a data audit and schema mapping sprint before migration begins |
|
R-02 |
Key integration vendor may deprecate API mid-project |
Medium |
High |
Tech Lead |
Transfer: Negotiate contractual SLA with penalty clause; identify fallback vendor |
|
R-03 |
Regulatory approval for the new system delayed |
Low |
High |
Project Manager |
Accept: Build a two-week contingency buffer into the go-live schedule |
|
R-04 |
Single senior engineer owns all legacy codebase knowledge |
High; |
Medium |
Engineering Manager |
Mitigate: Initiate knowledge transfer sessions and pair programming in sprint one |
By sprint three, R-04 has been partially mitigated through documentation and cross-training. R-02 has escalated—the vendor confirmed a deprecation timeline that falls within the project window. Because the risk was already on the register with a named owner and a fallback plan, the response is activated within 48 hours rather than triggering a two-week triage cycle.
This is what a functioning risk management process looks like in practice: not the absence of surprises, but the organizational readiness to respond to them without losing delivery momentum.
This example of risk management in software engineering will not fit all the projects, which is why it's important to follow the best practices to create a risk management strategy that works for a specific case. Here are a few tips for making one.
N-iX tips for effective risk management in software engineering
With over 23 years of experience in software development and delivering custom solutions to global enterprises, N-iX, as an outsourcing company with a pragmatic approach to AI, knows a few things about risk management. The following are the higher-level lessons that do not fit neatly into any single process step but consistently determine whether your risk management in software engineering will work.
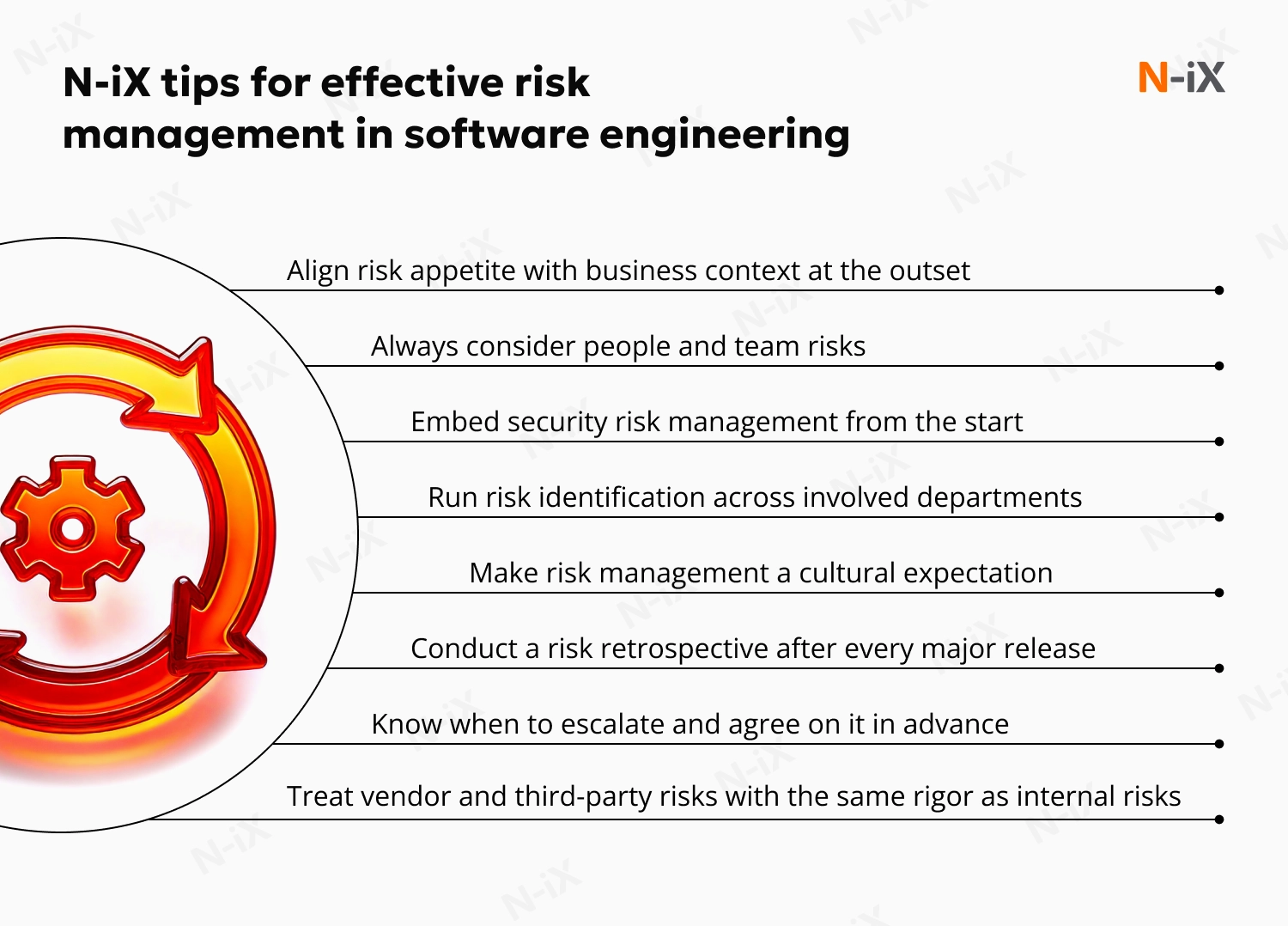
Align risk appetite with business context at the outset
Not every project carries the same acceptable level of risk. A fast-moving MVP for an internal tool and a regulated financial system have fundamentally different tolerances. Risk appetite, i.e., how much uncertainty the business is willing to absorb in pursuit of its goals, should be explicitly agreed with business stakeholders before the project begins. Without that alignment, delivery teams either over-engineer risk controls for low-stakes work or under-protect high-stakes systems, both of which are costly.
Always consider people and team risks
Technical risks get documented. People risks get avoided. Key-person dependencies, skill gaps, and unclear accountability structures are among the most common sources of project failure. They're also among the least likely to appear on a risk register. If your project depends on one senior engineer who cannot be replaced in the near term, that is a risk. If a critical module is owned by someone who has already handed in their notice, that is a risk. Leaving them unregistered doesn’t make them go away.
Consider these 11 tech companies that outsource software engineering teams
Embed security risk management from the start
Security is consistently treated as a final-phase concern and can be addressed after the core functionality is built. Security risks identified during architecture review cost a fraction of what they cost during penetration testing, and a fraction again compared to what they cost after a breach. Threat modeling, dependency scanning, and access control design should be part of the build process from day one.
Run risk identification across involved departments
Engineers will identify technical risks. Project managers will flag timeline and dependency risks. But security vulnerabilities, compliance exposures, and vendor concentration risks are often only visible to people outside the immediate delivery team. The risks that cause the most damage are rarely the ones the delivery team was already watching. Usually, they're the ones nobody thought to include in the room.
Make risk management a cultural expectation
When risk management in software engineering is perceived as a PM's administrative duty rather than a team-wide responsibility, engineers stop raising concerns early and risks escalate only after they have already caused damage. The teams that manage risk most effectively are the ones where surfacing a concern early is treated as a contribution, not a disruption. That tone is set by leadership, and it has to be consistent.
Conduct a risk retrospective after every major release
Most teams run retrospectives on what went wrong in delivery. Few run them specifically on what their risk management process missed, caught too late, or handled well. A risk retrospective asks different questions: which risks on the register actually materialized, which ones were not on the register but should have been, and which response plans worked as intended? Without this feedback loop, teams repeat the same mistakes on every project.
Know when to escalate and agree on it in advance
One of the most consistent failure patterns we see is a risk known at the team level that never surfaced to leadership until it was too late to respond effectively. Teams default to hoping a risk will resolve itself because escalating feels like admitting failure or unnecessarily alarming leadership. Define thresholds at the start, but also make it explicit that using them is expected and valued. A risk escalated early is a problem solved cheaply. A risk escalated late turns into a crisis.
Treat vendor and third-party risks with the same rigor as internal risks
Most risk registers focus on what the team controls. Vendor delays, third-party API instability, and supply chain dependencies sit outside that boundary. However, they impact your delivery timeline and system reliability. In July 2024, CrowdStrike’s customers had not identified a single security vendor as a risk. The organizations that recovered fastest were the ones that had contingency plans for exactly that scenario.
Related: Software engineering outsourcing: How to make the most of it?
Final thoughts: Managing software risk is a leadership decision
In any project, the question is not whether risks exist but whether your organization has the structure, process, and discipline to manage them effectively. That becomes significantly harder when projects involve industry regulations, distributed teams, complex vendor ecosystems, or technology decisions with long-term consequences. Getting the risk management in software engineering right requires development experience, domain knowledge, and the organizational maturity to apply both consistently. N-iX brings all three.
With over 2,400 tech experts across development centers in Poland, Colombia, Romania, Bulgaria, Ukraine, and India, we build custom software solutions for global enterprises and account for project-specific risks from the start. Our compliance certifications, including PCI DSS, SOC 2, ISO 27001, ISO/IEC 27701:2019, FSQS, and GDPR are the operational foundation that makes risk management credible in industries where the cost of getting it wrong is high.
Whether you are starting a new project or pressure-testing an existing delivery, our software development consulting, DevSecOps, and cybersecurity teams have the experience and resources to build it right—and keep it that way.

Sources:
- What the 2024 CrowdStrike Glitch Can Teach Us About Cyber Risk | Harvard Business Review
- AI | 2025 Stack Overflow Developer Survey | Stack Overflow
- Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 | Gartner
- Disrupting the first reported AI-orchestrated cyber espionage campaign | Anthropic
- Cost of a Data Breach Report 2025 | IBM
FAQ
What are the main steps in risk management in software engineering?
The core steps are: risk identification, risk assessment and prioritization, risk planning and response, and risk monitoring and control. The process repeats throughout delivery as the project evolves and new risks emerge.
What are the most common types of risks in software engineering?
The most common risk categories are schedule and timeline risks, budget and cost risks, technical risks, operational risks, security and data risks, people and team risks, stakeholder and requirement risks, and external or vendor-related risks. AI-related risks, including insecure code generation, compliance blind spots, and skill erosion, are an increasingly significant category in 2026.
What is the difference between reactive and proactive risk management in software engineering?
Proactive risk management focuses on identifying and addressing risks before they materialize, using tools like risk registers, threat modeling, and structured review cadences. Reactive risk management deals with incidents after they occur, using hotfixes, emergency escalations, and incident response plans. Effective teams run both in parallel: proactive planning for predictable risks, and a well-rehearsed response process for everything else.
What is a risk register in software engineering, and why does it matter?
A risk register is a living document that records every identified risk along with its probability rating, potential impact, assigned owner, planned response, and current status.
What are the seven principles of risk management in software engineering?
The seven principles of risk management in software engineering are:
- Global perspective: Evaluating risk in the context of the full system;
- Forward thinking: Anticipating problems before they occur;
- Open communication: Making risks visible across the team and to stakeholders;
- Integrated management: Embedding risk management into the broader project process;
- Continuous monitoring: Tracking risks throughout the entire lifecycle;
- Shared responsibility: Making risk ownership a team-wide expectation;
- Risk-informed decision making: Using risk data to guide prioritization and resource allocation.
How does security risk management in software engineering differ from general risk management?
Security risk management in software engineering specifically addresses threats to data confidentiality, system integrity, and availability, such as cyberattacks, data breaches, insecure code, third-party vulnerabilities, and compliance violations. While general risk management covers the full spectrum of project risks, security risk management requires dedicated practices such as threat modeling, dependency scanning, penetration testing, and access control design embedded from the start of the project rather than applied as a final-phase check.
Why is risk management planning in software engineering important?
Risk management planning in software engineering is important because it converts identified risks into role-based action: who owns it, what the response is, and when to escalate. Teams that skip this step know what can go wrong but have no agreed plan for when it does, increasing the incident response time.


