
Ecommerce is a $4.4T global market, where speed, personalization, and accuracy directly impact revenue [2]. A well-architected ecommerce data warehouse helps to meet these requirements by consolidating data from multiple systems into a single source of truth. With fast, reliable access to unified data, ecommerce businesses can personalize offers, forecast demand, reduce reporting delays, and make data-backed decisions at scale.
However, implementing that foundation requires both technical precision and business alignment, which is often a difficult task for internal teams. To meet these requirements, organizations often rely on data warehouse consulting and ecommerce software development services from an experienced tech partner.
Which use cases can such a partner help you implement? What does a modern ecommerce data warehouse architecture look like? Which platforms offer the scalability, performance, and integrations that ecommerce businesses need? Let’s find out!
Key benefits of an ecommerce data warehouse
A well-designed ecommerce data warehouse allows for faster reporting, more accurate targeting, and better analytics. Let’s review the benefits an ecommerce business gets from building a data warehouse:
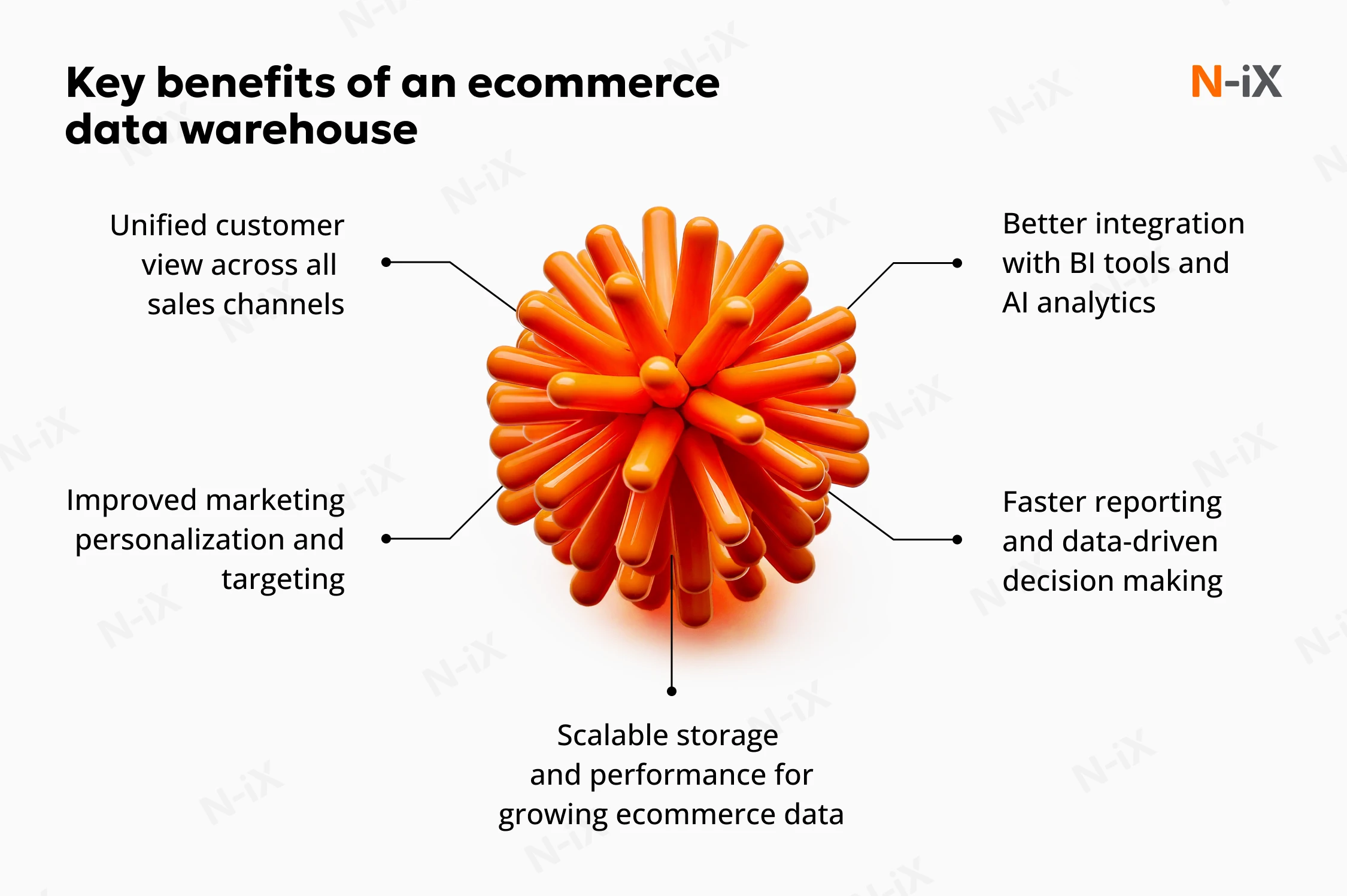
- Unified customer view across all sales channels
Combining data from online, mobile, and in-store systems, the warehouse enables 360-degree customer profiles. - Improved marketing personalization and targeting
Centralized customer and engagement data allows marketing teams to build precise segments, trigger contextual campaigns, and improve conversion efficiency. - Faster reporting and data-driven decision making
Automated aggregation and real-time data access reduce reporting cycles, helping business units respond quickly to trends, risks, and opportunities. - Scalable storage and performance for growing ecommerce data
Cloud-native infrastructure supports rapid data growth and peak-season demand without compromising performance, uptime, or cost efficiency. - Better integration with BI tools and AI analytics
Clean, structured warehouse data powers dashboards, predictive analytics, and automated decisions.
Common use cases for ecommerce data warehouses
Segmentation and personalization
According to McKinsey, firms leading in personalization generate 40% more revenue than their peers [1]. Achieving this level of performance depends on precise customer segmentation supported by unified, high-quality data. Ecommerce data warehouses combine behavioral signals, transaction history, and engagement metrics into centralized customer profiles. With this foundation, businesses can group customers in real time, tailor messages to specific needs, and predict lifetime value (LTV) more accurately.
When combined with AI-powered recommendation engines and campaign automation, these insights help marketing teams respond to each customer’s behavior in the moment. Personalized offers drive better conversion rates and long-term loyalty.
Inventory and supply chain optimization
Ecommerce success depends on the ability to align stock levels with real-time demand while avoiding overstock, delays, or missed sales. Achieving this balance requires timely, unified data from order systems, warehouses, suppliers, and logistics providers.
A well-architected data warehouse brings these fragmented sources together into a centralized environment. This allows companies to automate replenishment, run predictive models for inventory-related costs, and simulate different supply scenarios with full visibility into constraints.
One example is a platform developed by N‑iX for a Fortune 500 industrial supplier. The solution integrated data from over 100 internal and external sources and consolidated it into a scalable Snowflake-based architecture. With this visibility, the client’s finance and operations teams gained more accurate inventory forecasts, optimized stock levels, and freed up working capital.
Campaign performance analysis and ROAS tracking
Omnichannel marketing spreads ecommerce data across ad platforms, email systems, and on-site engines, making unified attribution difficult. Without a centralized data warehouse, calculating return on ad spend (ROAS) or comparing campaign effectiveness involves tedious reconciliation and incomplete visibility.
Data warehouse in ecommerce consolidates impression, click, conversion, and order data into a single analytics layer. In such a way, it enables a clear view of which campaigns drive sales, how each channel performs, and where ad spend delivers the highest return.
McKinsey estimates that moving to top-quartile personalization can unlock over $1T in value across US industries, which makes precise targeting and budget optimization strategically important [1]. With unified campaign data, marketers can shift budget toward better-performing channels, automate retargeting, and continuously refine audience segments based on behavior and performance.
Sales forecasting and seasonal demand planning
Seasonal peaks, flash promotions, and market volatility make accurate demand forecasting essential for ecommerce. Warehoused data enables ML-powered time-series models that analyze historical patterns, promo calendars, and external factors like market trends or weather fluctuations.
Retailers can use these models to simulate high-traffic events, plan inventory procurement, and align staffing or order fulfillment capacity, avoiding both stockouts and excess inventory. Forecasting that runs on clean, centralized warehouse data improves operational readiness and helps capture revenue during peak sales windows without overcommitting resources.
Explore the top 5 price monitoring tools for ecommerce and retail!

Success!
Fraud detection and order anomaly flagging
In 2024, global losses to online payment fraud reached $44B [2]. Beyond direct losses, merchants incur additional costs from chargebacks, investigations, and customer support, making fraud prevention a high-impact area for ecommerce operations.
Detecting fraud at scale requires pattern recognition across disparate signals: customer behavior, transaction data, geographic inconsistencies, and system anomalies. A robust data warehouse aggregates these inputs into a single environment where anomaly detection models can operate effectively.
ML algorithms trained on this unified data can flag suspicious activity in real time, such as high-risk orders or repeated payment failures. A mature data platform also supports regulatory compliance by maintaining audit trails, automating fraud reports, and embedding governance into detection workflows.
Discover more: Enterprise data warehouse: From raw data to unified analytics
How to implement a data warehouse for ecommerce
Implementing a data warehouse for ecommerce requires precise sequencing, technical depth, and business alignment at every stage. Based on our experience delivering complex ecommerce data solutions, here are the key considerations to guide decision-making at each stage.
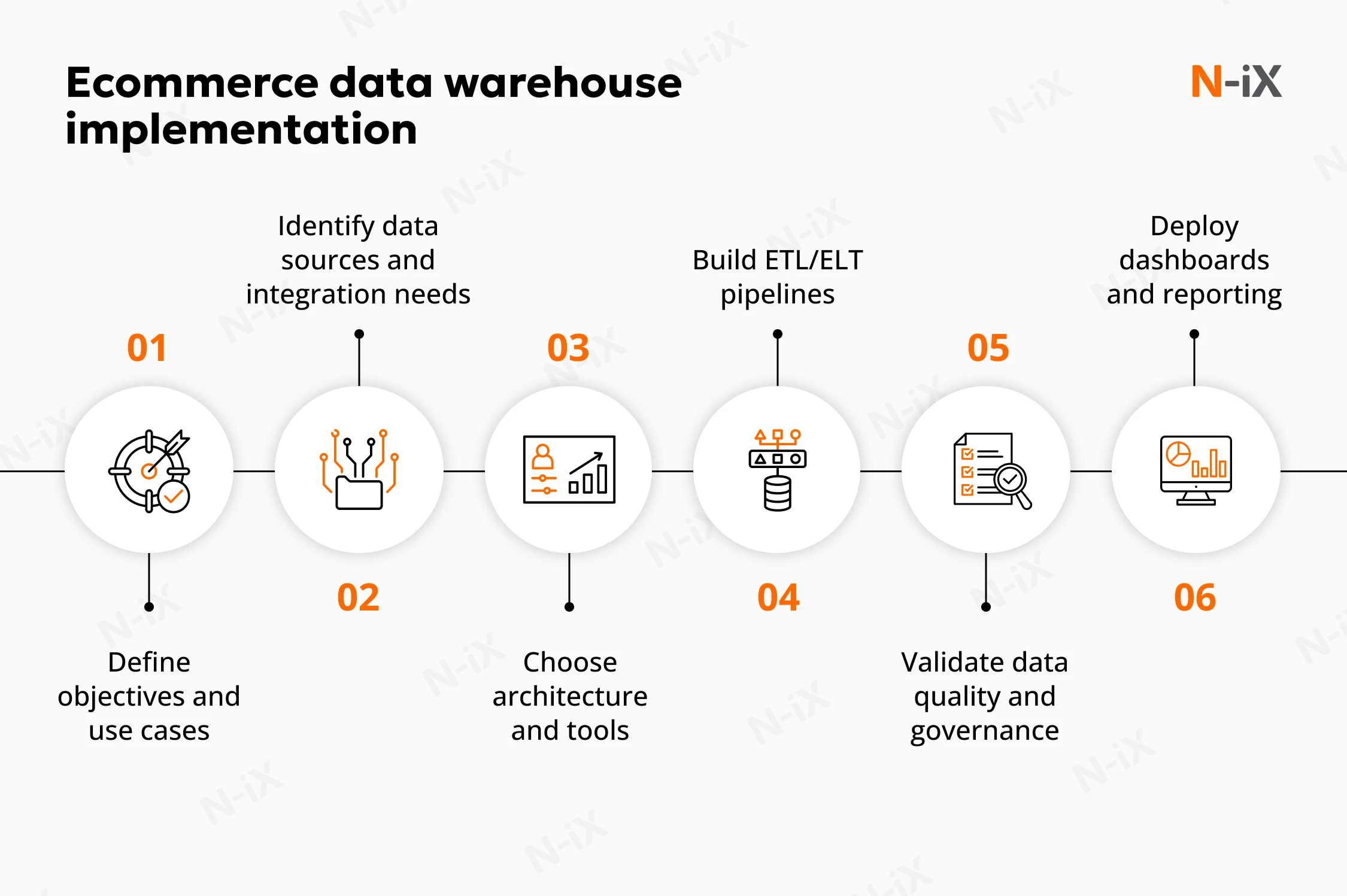
1. Define objectives and use cases
Every implementation should begin with clear, measurable business goals. Ecommerce companies prioritize faster reporting, customer data unification, campaign performance visibility, and supply chain optimization. N‑iX recommends identifying and prioritizing the highest-value use cases early to prevent scope creep and ensure that architectural choices align with business outcomes.
2. Identify data sources and integration needs
Data integration planning leads from strategy to execution. Ecommerce platforms generate data across numerous systems, such as order management, CRM, ERP, marketing tools, payment gateways, and logistics providers.
Data owners and technical leads must audit available systems, prioritize relevant datasets, and define connection methods based on business requirements and technical constraints. N‑iX works with stakeholders to create a comprehensive integration map that minimizes redundancy and sets up scalable ingestion from the outset.
3. Choose architecture and tools
Platform architecture shapes long-term scalability and cost efficiency. For fast-changing ecommerce environments, N‑iX favors modular, cloud-native designs. They separate compute and storage, support ELT patterns, and allow for flexible transformations when combined with tools like dbt or Azure Data Factory. This architecture accelerates iteration, supports vendor neutrality, and adapts to changing data volumes and analytics requirements.
However, for simpler reporting needs or tighter budgets, more consolidated architectures may offer better cost control or faster time-to-value. The optimal design depends on data volumes, latency expectations, and internal team capabilities.
4. Build ETL/ELT pipelines
Effective data pipelines are critical for consistent, accurate, and timely analytics. At this stage, it is important to define how data will move through the system and to select the right tools for orchestration, monitoring, and scaling. Well-structured pipelines should handle different data formats and update intervals while minimizing complexity and manual effort.
N‑iX builds ELT and ETL workflows that deliver reliable data movement, optimize transformation steps, and automate recurring tasks. This practice reduces operational overhead, shortens time to insight, and enables continuous analytics across ecommerce business functions.
5. Validate data quality and governance
Reliable data fuels trust, compliance, and monitoring. At this stage of data warehouse automation, teams should implement validation rules, enforce data ownership policies, and establish clear governance workflows to prevent errors and inconsistencies. N‑iX embeds quality and governance controls at the pipeline level, validating schemas, managing access, and ensuring data integrity at each stage.
In the same project, N-iX integrated customer and partner data systems, addressed recurring data quality issues, and established a long-term maintenance process to prevent regressions and data loss. As a result, we stabilized platform performance and reduced risk across reporting workflows.
6. Deploy dashboards and reporting
The final layer should support clear, role-specific decisions. Teams need well-defined metrics, functional reporting views, and tools that fit how they work. N‑iX delivers curated business views that let marketing, finance, and operations access trusted insights without relying on engineers. Pre-built data marts, governed KPIs, and integrations with Power BI, Tableau, or Looker ensure consistency and ease of use.
When the reporting layer is done right, the data warehouse becomes a useful tool for daily execution.
Read more: Data warehouse strategy: design in 6 steps
Ecommerce data warehouse architecture: Core components
A modern ecommerce data warehouse is a system composed of interoperable layers, each designed to collect, process, store, and deliver data for business use. Understanding these core components enables decision-makers to evaluate vendor proposals, align infrastructure with business goals, and avoid costly architectural mistakes.
Data sources
The foundation of any data warehouse is the set of data sources it integrates. In ecommerce, this typically includes:
- Sales platforms (Shopify, Magento, Salesforce Commerce)
- CRM systems (Salesforce, HubSpot)
- ERP platforms (SAP, Oracle NetSuite)
- Marketing and analytics tools (Google Analytics, Meta Ads, Klaviyo)
Aggregating these sources into one warehouse creates a single source of truth for customer, product, order, inventory, and campaign data. It replaces fragmented exports with consistent reporting and supports unified customer views across departments.
ETL/ELT pipelines
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines are the mechanisms that move data from source systems into the warehouse and prepare it for analysis.
- ETL involves cleaning and restructuring the data before loading it.
- ELT loads raw data first, then transforms it within the warehouse, which is more common in modern, cloud-based ecosystems.
These pipelines are often automated using orchestration tools, and their quality directly impacts data freshness, reliability, and scalability. Well-designed pipelines reduce manual data wrangling, shorten reporting cycles, and ensure that dashboards reflect up-to-date information.
Data models
Once data is loaded, it must be structured in a way that supports efficient querying and business logic. Two common approaches include:
- Star schema: A simplified, denormalized model optimized for reporting and BI tools. Ideal for speed and ease of use.
- Snowflake schema: A normalized model that improves data integrity and reduces duplication. Suitable for more complex analytics needs.
Choosing the right model affects the model's performance as well as how easily analysts and business users can extract insights. A poorly designed model leads to slow queries, misaligned KPIs, and high maintenance overhead.
Storage layer
The storage layer determines how data is physically stored, accessed, and scaled. It impacts query performance, cost, and resilience during peak periods.
Cloud-based storage layers typically offer:
- Elastic scalability to handle growing datasets without performance degradation;
- Separation of storage and compute, allowing independent scaling;
- Security and compliance features such as encryption, auditing, and access control.
At this layer, the choice of platform will determine factors such as pricing models, vendor lock-in risk, and compatibility with downstream tools.
Access layer
This is the interface between the warehouse and business users. It includes:
- BI and dashboard tools, such as Tableau, Power BI, Looker;
- Custom analytics applications;
- APIs and data exports for operational systems.
A well-designed access layer ensures that stakeholders can access reliable data in the formats they need, without going through IT or data engineering teams for every request. It also enables integration with ecommerce Machine Learning models, personalization engines, and third-party automation tools.
Read also: Use cases of retail data warehouse
Choosing the right data warehouse platform
Platform selection shapes cost, performance, and long-term flexibility. For ecommerce companies, the right choice depends on business scale, real-time demands, cloud strategy, and the broader data stack. Let’s compare the four leading data warehouse platforms.
Amazon Redshift
Amazon Redshift is a mature, fully managed cloud data warehouse built for the AWS ecosystem. It supports traditional SQL workflows and integrates natively with AWS services like S3, Glue, and SageMaker.
Strengths: Redshift is cost-effective at moderate data volumes and supports familiar tooling for teams already in the AWS ecosystem. Performance can be optimized with materialized views and data distribution strategies.
Trade-offs: Its scalability is not as elastic as more modern decoupled architectures. While Redshift Spectrum supports querying external data in S3, overall flexibility is lower compared to Snowflake or BigQuery. Reserved-instance pricing adds complexity in cost management.
Best fit: Mid-sized ecommerce platforms, which are already on AWS, with stable reporting workloads and limited real-time requirements.
Google BigQuery
BigQuery is a serverless, fully managed data warehouse designed for elastic scalability. It decouples storage from compute and charges based on usage, not capacity.
Strengths: BigQuery offers near-unlimited scale, automatic performance tuning, and native integration with Google Marketing Platform, making it attractive for ecommerce companies reliant on digital advertising. Pricing is usage-based, which benefits teams with variable workloads.
Trade-offs: Cold-start latency and per-query costs can be unpredictable without cost controls. Operational transparency is lower than some alternatives, and long-term lock-in to GCP can limit flexibility for multicloud strategies.
Best fit: Ecommerce businesses with significant marketing analytics workloads or deep Google Ads integration.
Snowflake
Snowflake is a cloud-native, platform-agnostic data warehouse designed for elasticity, multicloud flexibility, and separation of compute and storage.
Strengths: It offers automatic scaling, zero-maintenance infrastructure, and strong support for semi-structured data, for instance, JSON or Parquet. Its architecture enables multiple virtual warehouses to operate independently, allowing analytics, reporting, and Machine Learning to run in parallel without contention.
Trade-offs: Compute usage can be expensive without careful workload monitoring. Native integration with marketing platforms is weaker than in BigQuery. Requires additional orchestration tools to manage full data pipelines.
Best fit: Enterprise ecommerce companies with multicloud strategies, variable workloads, or strict requirements around concurrency, cost isolation, and platform neutrality.
Azure Synapse Analytics
Azure Synapse combines traditional data warehousing with big data processing. It offers tight integration with Microsoft products, including Dynamics 365, Power BI, and Azure ML.
Strengths: Best suited for companies already invested in the Microsoft ecosystem. Supports both on-demand and provisioned workloads, with granular control over performance and cost.
Trade-offs: Platform complexity is higher than competitors, especially for teams unfamiliar with the broader Azure stack. Performance tuning and orchestration require more hands-on effort.
Best fit: Ecommerce organizations standardized on Microsoft technology, particularly those using Power BI or Dynamics as core systems.
Final recommendation approach
N‑iX helps ecommerce businesses evaluate platform fit based on specific operational requirements, data volumes, partner ecosystems, and scalability goals. The best platform is not just the fastest or cheapest. It’s the one that aligns with the broader data strategy, workload patterns, and integration needs.

Why partner with N-iX for ecommerce data warehousing
- Over 23 years in business, including enterprise-scale data engineering and analytics;
- Certified expertise in AWS Redshift, Google BigQuery, Azure Synapse, and Snowflake;
- End-to-end delivery: from strategy and discovery to implementation, migration, and support;
- Deep ecommerce and retail analytics background with Fortune 500 clients;
- Strong experience with ELT pipelines, dbt, Azure Data Factory, and orchestration tools;
- Embedded governance and compliance support (GDPR, PCI DSS, ISO 27001);
- Access to a global pool of over 2,400 professionals with more than 200 data engineering professionals.
References
- McKinsey & Company. The value of getting personalization right—or wrong—is multiplying
- Statista. E-commerce fraud - statistics & facts
Have a question?
Speak to an expert


