
Why does every new data source, metric, or reporting change make your data warehouse harder to manage? Fresh data sources are added, reporting requirements expand, and transformation logic accumulates. What once felt manageable becomes fragile. Simple changes take longer than expected, dependencies are harder to trace, and senior data engineers spend most of their time maintaining existing pipelines rather than improving how data is used.
At this point, data warehouse automation (DWA) becomes a necessity. It is a way to reduce manual work, standardize recurring patterns, and make analytics delivery more predictable at scale. Automation replaces ad hoc fixes with repeatable behavior and provides teams with a shared operating model, reducing reliance on tribal knowledge. It's at this stage that organizations increasingly seek data warehouse consulting, not for tools, but for experienced guidance on stabilizing and scaling their data platforms.
What is data warehouse automation?
Data warehouse automation is an engineering approach to building and operating a data warehouse in which repeatable work is formalized and executed automatically, rather than being recreated manually with every change. Its purpose is control: making the data warehouse easier to evolve, easier to reason about, and less dependent on individual engineers as it grows.
DWA shifts the focus from how pipelines are built to what the warehouse is expected to do. Instead of repeatedly implementing similar logic, teams define intent once, schemas, transformations, dependencies, and quality rules, and let automation apply those definitions consistently across the platform.
In practice, this often shows up when an enterprise adds a new business system or expands analytics to another department. Instead of building new pipelines from scratch, teams apply existing ingestion, transformation, and validation patterns defined in metadata, allowing the latest data to flow through the warehouse with predictable behavior. Changes are absorbed systematically, documentation and lineage are updated automatically, and engineers focus on validating assumptions rather than reimplementing logic. Over time, the warehouse evolves as a controlled system rather than a collection of individually maintained pipelines.
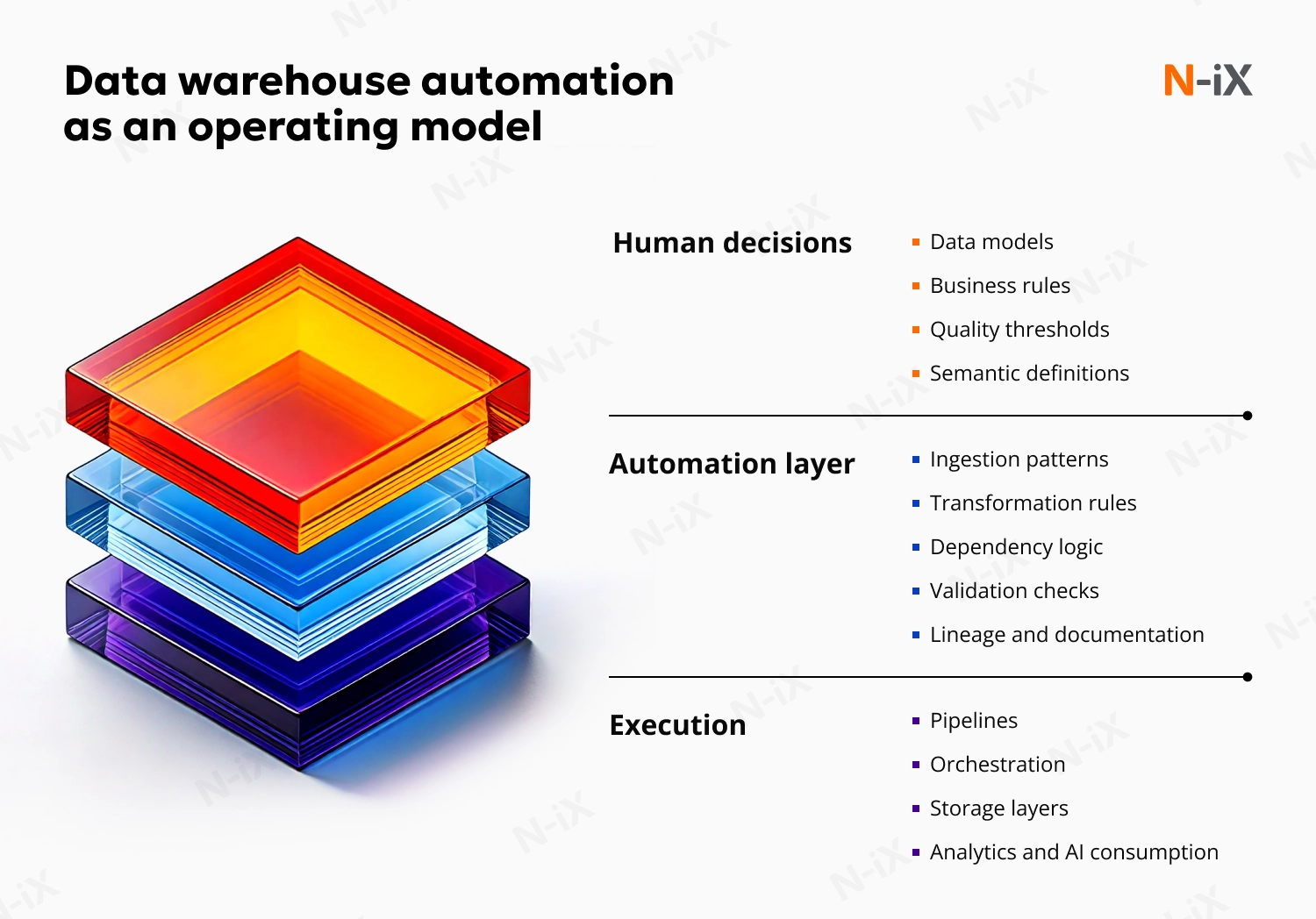
Where automation applies in a data warehouse
A common misconception is that data warehouse automation is only about ETL or ELT. In reality, it covers the entire data warehouse lifecycle, from early design decisions to day-to-day operations.
In a well-designed data warehouse, automation typically applies to:
- Standardizing how data is extracted, loaded, and incrementally updated from source systems, including handling schema changes and late-arriving data.
- Generating and maintaining transformation logic where patterns repeat across domains, layers, or data products, while enforcing consistent conventions and quality rules.
- Managing dependencies between datasets, scheduling execution, and ensuring that changes propagate in a controlled and observable way.
- Applying structural tests, freshness checks, and rule-based validations systematically, rather than relying on ad-hoc or manual verification.
- Keeping documentation, dependencies, and data lineage synchronized with the actual implementation so that the warehouse remains explainable as it evolves.
Modernize your data warehouse in 5 steps—get the guide!

Success!
What are the business objectives for data warehouse automation?
Accelerated delivery and predictable time-to-value
In manually built data warehouses, every meaningful change, new data source, new metric, or revised logic creates a long feedback loop. Requirements become custom development, cross-team coordination, testing, and carefully staged deployment. Over time, this can slow analytics delivery to the point where insights arrive too late to influence decisions.
DWA shortens these cycles by standardizing how recurring work is executed. Instead of repeatedly rebuilding similar ingestion, transformation, and orchestration logic, teams rely on predefined patterns that can be applied consistently. In practice, automation only accelerates delivery when it is grounded in a clear data warehouse strategy that defines what should be standardized and what must remain intentionally bespoke.
In practice, this approach is most evident in large-scale environments where manual processes are no longer feasible. In one global cloud services organization, N-iX helped consolidate dozens of data sources into a unified data warehouse and automate downstream reporting workflows that previously required extensive manual effort. By formalizing ingestion, transformation, and reporting patterns, the data platform became easier to scale, less costly to operate, and resilient to continuous change.

Cost control and sustainable use of engineering capacity
Automation improves ROI by changing how engineering time is spent. In manual environments, senior data engineers are often consumed by repetitive tasks: maintaining pipelines, fixing breakages, and reconciling inconsistencies introduced over time. This work is costly, difficult to scale, and largely invisible until it becomes a bottleneck.
By automating repeatable tasks, organizations reduce the volume of low-value manual work and slow the accumulation of technical debt. Maintenance becomes more systematic, onboarding new sources requires less bespoke effort, and the data warehouse can grow without a proportional increase in headcount. Over time, this stabilizes operating costs and makes capacity planning more predictable.
A similar pattern appears in large industrial and supply-chain environments where data volumes and cost pressure grow simultaneously. In a Fortune 500 industrial supply company, N-iX helped design and evolve a unified data platform that automated ingestion and processing across hundreds of sources while supporting continuous cloud migration. By standardizing data flows and reducing bespoke pipeline work, the platform scaled predictably without increasing operational overhead or locking the organization into a single cloud provider.
Read more how N-iX helped leading industrial supply company with a data warehouse
Improved data quality, consistency, and governance
As data warehouses expand, inconsistencies are almost inevitable in manual setups. Similar logic is implemented differently, assumptions are embedded in code, and documentation lags behind reality. These issues directly affect trust in analytics and increase the cost of audits, troubleshooting, and compliance reporting.
Data warehouse automation software addresses this by enforcing shared standards and integrating quality controls, lineage, and documentation into the execution model. Tests are applied consistently, dependencies are explicit, and changes are traceable. With data warehouse test automation, errors are detected earlier and handled in a controlled way. Governance lately shifts from reactive enforcement to built-in discipline.
Reduced operational risk as complexity grows
Manual data warehouses rely heavily on tacit knowledge: what certain pipelines do, which changes are risky, and where hidden dependencies exist. As teams change and systems evolve, this knowledge erodes, increasing the likelihood of hard-to-diagnose, hard-to-recover-from failures.
Automation reduces this risk by making behavior explicit and repeatable. Dependencies are managed systematically, failure conditions are anticipated, and recovery paths are clearer.
The strongest business case for DWA is strategic. It is more about doing the right work consistently at a scale that manual approaches cannot sustain.

How data warehouse automation works across the full lifecycle
Data warehouse automation architecture is built around a simple and powerful idea: encode intent once, execute it consistently everywhere. Instead of treating ingestion, transformation, testing, and deployment as separate technical tasks, DWA treats them as parts of a single, controlled lifecycle.
|
Area |
Manual operation |
Automated operation |
|
Data ingestion |
Pipelines are built per source and adjusted manually when schemas change |
Ingestion follows predefined patterns driven by metadata, with controlled handling of schema changes |
|
Transformations |
Logic is implemented repeatedly across pipelines |
Transformations are generated from shared rules and models |
|
Change management |
Impact is discovered after deployment |
Dependencies are explicit and assessed before deployment |
|
Failure detection |
Issues surface in reports or downstream systems |
Validation and freshness checks detect failures during execution |
|
Lineage and documentation |
Maintained separately and often outdated |
Generated and updated as part of execution |
|
Scaling analytics |
Growth increases manual workload and reliance on senior engineers |
Growth follows standardized patterns without proportional manual effort |
|
AI and ML data readiness |
Feature pipelines drift and become inconsistent |
Feature data is reproducible, traceable, and versioned |
At the core of effective DWA is a clear separation between intent and execution. Metadata-driven and model-driven architectures make this possible by moving the definition of structures, rules, and dependencies into a centralized layer rather than embedding them directly in SQL, ETL scripts, or orchestration code. Engineers define how data should be shaped, transformed, validated, and connected. At the same time, automation uses those definitions, together with established design patterns, to generate the underlying tables, transformations, workflows, tests, and documentation.
Just as importantly, this foundation decouples business logic from the underlying storage technology. Because intent is expressed independently of how data is physically stored or processed, the warehouse becomes more resilient to change, whether that change involves schema evolution, new data sources, or architectural shifts. Lineage and impact analysis become easier to reason about, failures are more traceable, and engineers can focus on improving models and rules instead of maintaining repetitive code.
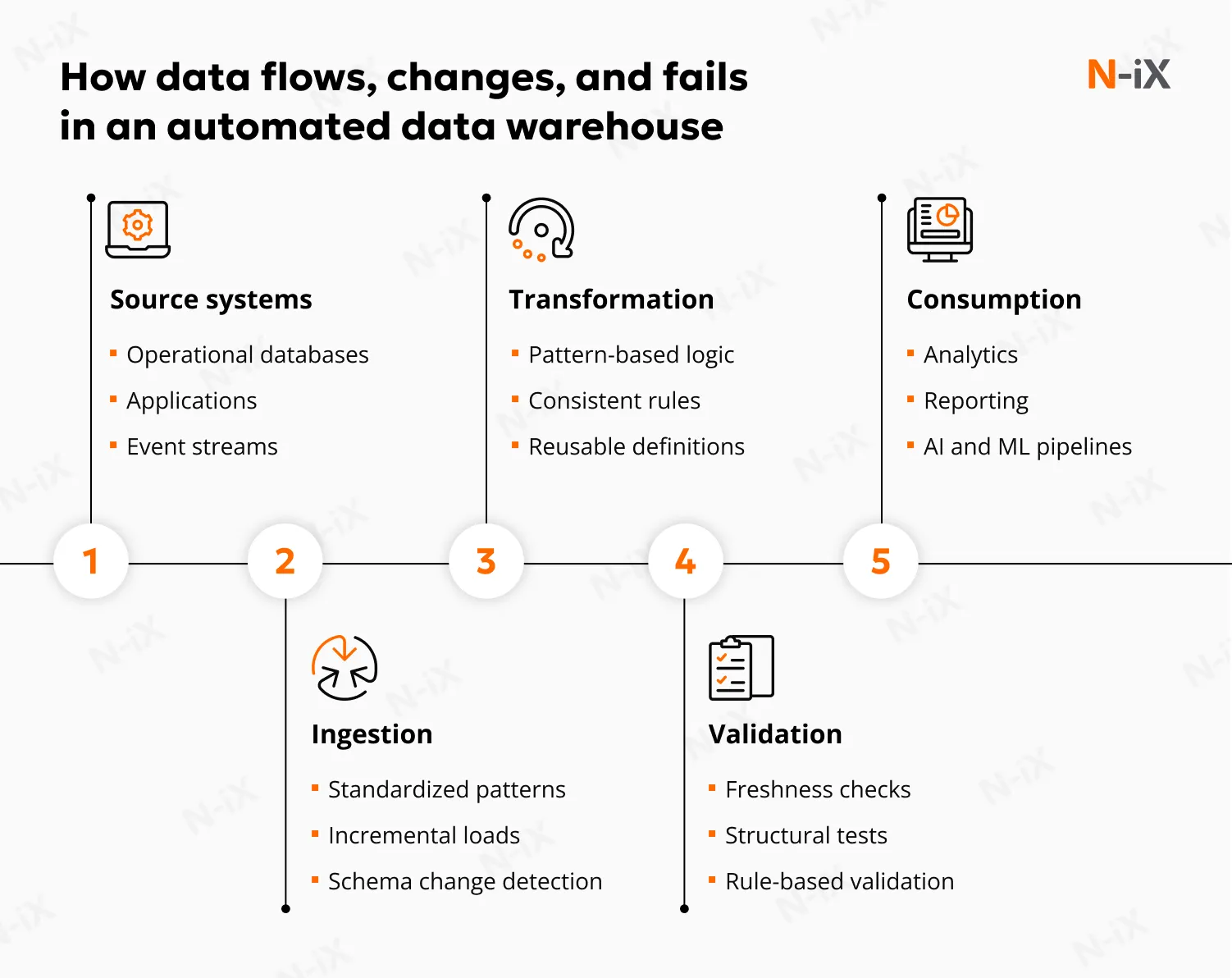
While implementations vary, the data warehouse automation lifecycle follows a consistent architectural flow:
1. Source integration and metadata capture
The lifecycle starts with connecting to source systems and understanding their structure. Instead of manually profiling schemas and documenting changes, DWA architectures automatically harvest source metadata: tables, columns, relationships, data types, and update patterns. As sources evolve, schema changes are detected and managed centrally rather than discovered downstream after breakages occur. Data warehouse automation vendors establish a reliable baseline for automation. By making the source structure explicit and version-controlled, the warehouse can absorb changes without requiring engineers to rewrite ingestion logic as the system evolves.
2. Model-driven design and structuring
Once source metadata is available, automation shifts to design. Engineers define how source data maps into analytical models, how entities relate, which attributes belong where, and how history should be handled. These decisions are captured at the model level. The architecture supports multiple modeling approaches, including normalized and denormalized patterns, as well as more adaptive patterns such as Data Vault-style structures. What matters is the explicitability and repeatability of modeling rules. Automation ensures that model changes propagate consistently across all affected layers.
Learn also the difference between a data mart vs data warehouse
3. Code generation and transformation execution
With intent and models defined, the enterprise data warehouse automation engine generates the physical implementation. The above example includes database structures, transformation logic, and orchestration dependencies. Rather than hand-writing SQL or ETL logic, engineers rely on governed templates that encode best-known patterns for loading, transforming, and validating data. Transformations follow consistent rules, incremental loading strategies are applied uniformly, and naming conventions remain stable. Importantly, engineers retain control over regulations and exceptions, but they are used systematically.
4. Orchestration, testing, and operational control
Automation architecture extends beyond building pipelines to operating them. Dependencies between datasets are managed explicitly, execution order is derived from metadata, and failures are detected early. Structural, freshness, and rule-based data warehouse automation testing is integrated into the lifecycle rather than bolted on afterward. Deployment and change management are also part of the architecture. Generated artifacts integrate with version control and CI/CD pipelines, ensuring that changes are traceable and reversible. Documentation and lineage are updated automatically as the system evolves, keeping operational understanding aligned with reality.
Read a comprehensive guide on data warehouse implementation
What are the enterprise use cases for automated data warehouse?
Enterprises are investing heavily in Machine Learning, generative AI, and agent-based systems, only to discover that their data warehouses built for reporting cannot reliably support continuous training, feature delivery, or real-time decision workflows. Automation becomes critical not because AI is complex, but because AI is unforgiving of unstable data foundations.
Building a data warehouse that AI systems can actually rely on
AI systems consume data differently from traditional analytics. They depend on consistent feature definitions, repeatable transformations, traceability to historical data, and predictable refresh behavior. Manual data warehouse practices struggle here. Features drift over time, training data differs subtly from inference data, and schema changes break pipelines in ways that are hard to detect before models degrade.
DWA addresses this by enforcing discipline at the data layer. Feature inputs are derived from governed transformation logic rather than ad-hoc SQL. Historical data is managed systematically, making retraining reproducible rather than interpretive. When automation is metadata-driven, changes to upstream data propagate in a controlled way, reducing the risk of silent model degradation.
Supporting continuous model development instead of one-off AI projects
Many AI initiatives stall after initial pilots because the underlying data pipelines cannot support continuous iteration. Each new model version requires manual data preparation, special-case transformations, and one-off validation. Automation changes this dynamic by turning data preparation into a reusable capability rather than a per-model effort. Standardized ingestion, transformation, and validation patterns enable onboarding new AI use cases without rebuilding the data foundation each time. Feature pipelines become part of the warehouse lifecycle instead of side projects maintained by individual teams.
Preventing data and feature drift before it degrades AI performance
In analytics, a delayed or incorrect report is usually noticed quickly. In AI systems, data drift can quietly degrade model performance long before anyone realizes there is a problem. Automation helps by embedding quality checks, freshness rules, and lineage tracking directly into the warehouse lifecycle.
When features change, the system knows where they are used. When assumptions break, failures surface early, before degraded predictions reach downstream applications. This makes AI behavior explainable and controllable, which is increasingly critical as models move closer to core business processes.
Secondary, but still critical enterprise use cases
While AI is now the primary driver, other use cases remain integral and are often strengthened by the same automation discipline.
- Scaling analytics across teams: Automation enables analytics adoption to grow without creating bespoke pipelines or conflicting definitions.
- Managing frequent schema and source changes: Metadata-driven automation absorbs upstream change without forcing constant rewrites.
- Supporting platform migrations and architectural shifts: Separating intent from execution reduces the cost and risk of moving between platforms. Data warehouse migration automation standardizes ingestion and transformation patterns and makes schema evolution explicit and traceable.
- Improving governance and audit readiness: Lineage, documentation, and impact analysis stay aligned with reality rather than lagging behind it.
- Integrating mergers and acquisitions (M&A): Automation provides a disciplined approach to onboarding new systems, reconciling keys, and applying shared transformation rules without creating bespoke implementations.
Read also: What is the role of a data warehouse in Business Intelligence?
Evaluate the readiness for automation
DWA can fail because organizations automate too late or automate the wrong things first. By the time automation is considered, manual patterns have already been reinforced through years of exceptions, workarounds, and implicit assumptions.
Evaluating readiness is less about maturity scores and more about asking uncomfortable questions. Do teams understand which parts of the warehouse are stable patterns and which are constant exceptions? Are data models and transformation rules explicit, or do they live in people's heads and undocumented scripts? Can the impact of a change be assessed before it is deployed, or only after something breaks? These signals matter far more than the number of pipelines or tools in place.
An organization that benefits of data warehouse automation typically shares a few characteristics: they recognize that manual scaling is already a liability; they are willing to standardize where variability adds no value; and they accept that automation is an operating model. In these environments, automation becomes a way to encode discipline into the warehouse.
This is also where experienced guidance makes a difference. Designing automation that survives real-world change requires more than selecting platforms or enabling features. It requires understanding where structure is needed, where flexibility must remain, and how engineering effort should be invested over time. At N-iX, we work with organizations at this decision point: helping them assess readiness, define what is worth automating, and design DWA that supports growth and AI initiatives without locking in today's constraints.
If you are considering DWA as part of scaling analytics, enabling AI, or stabilizing a growing data platform, the next step is understanding where automation will strengthen your system rather than merely speed it up. This is the point at which a focused, expert-led assessment can save months of rework and lay the foundation for automation under real enterprise pressure.

FAQ
Is data warehouse automation only relevant for large enterprises or complex environments?
Data warehouse automation becomes valuable as soon as manual processes begin to slow delivery or increase operational risk. While large enterprises feel this pressure first, any organization planning to scale analytics, AI, or regulatory reporting will face the same constraints over time.
How does DWA support AI and Machine Learning initiatives?
AI systems depend on consistent, reproducible data pipelines and feature definitions. DWA enforces discipline at the data layer, reducing feature drift, improving traceability, and making model training and inference pipelines easier to operate and explain.
When is the right time to adopt data warehouse automation?
The best time to adopt DWA is before manual complexity becomes entrenched. Organizations that introduce automation early can encode good patterns and governance into the platform, rather than trying to retrofit discipline after scale and technical debt have accumulated.
Have a question?
Speak to an expert


