
Robust data architecture has been a core enterprise concern for decades. Data warehouses were established to centralize analytics, and data marts emerged to accelerate delivery for specific teams. Both concepts exist to make data usable for decision-making, but they do so through fundamentally different structural choices.
The distinction between data warehouse vs data mart determines how metrics gain authority, how discrepancies are resolved, and how much analytical complexity the organization accepts over time. Data warehouse concentrates control to preserve consistency across the business. Data marts distribute control to optimize for speed and local relevance. Each model incurs costs, but those costs accumulate differently as scale, usage, and organizational complexity increase.
In this article, we will compare data warehouse vs data mart differences and how each works to influence decision authority and analytical complexity in enterprise environments.
What does a data warehouse represent?
A data warehouse is a centralized repository for data and analytics that supports reporting, analysis, and business intelligence across an organization. It consolidates data from multiple operational and external sources into a single, governed environment that is optimized for analytical workloads. Alongside operational databases built for transaction processing, a data warehouse is designed for read-intensive, complex queries that support historical analysis and cross-functional reporting.
Enterprise data warehouse forms the authoritative layer where business data is standardized, reconciled, and made comparable across domains. Its primary purpose is not speed of ingestion or flexibility of structure, but consistency of meaning. This consistency allows leadership teams to rely on shared metrics, trace results back to their origins, and make decisions based on aligned definitions rather than local interpretations.
Key characteristics of a data warehouse
A data warehouse is defined by a set of structural characteristics that distinguish it from other data storage systems:
- Subject-oriented: Data is organized around core business domains such as revenue, customers, products, or operations, rather than around individual applications.
- Integrated: Data from disparate sources is cleansed, standardized, and transformed into consistent formats, ensuring comparable results across teams.
- Non-volatile: Data is appended rather than overwritten, preserving stable historical records for analysis and auditability.
- Time-variant: Data is stored with an explicit time dimension, enabling trend analysis, period comparisons, and longitudinal reporting.
The cost of a data warehouse is visible upfront. The cost of not having one shows up later, in duplicated pipelines, reconciliations, and decisions delayed because no one trusts the output.

Technical context of data warehouses
Data warehouses are typically populated through structured data pipelines, most commonly using ETL or ELT processes. Data is extracted from source systems, transformed to align with enterprise definitions, and loaded into predefined schemas. While modern platforms can accommodate limited semi-structured data, data warehouses remain optimized for structured, schema-driven data that supports repeatable and reliable analysis.
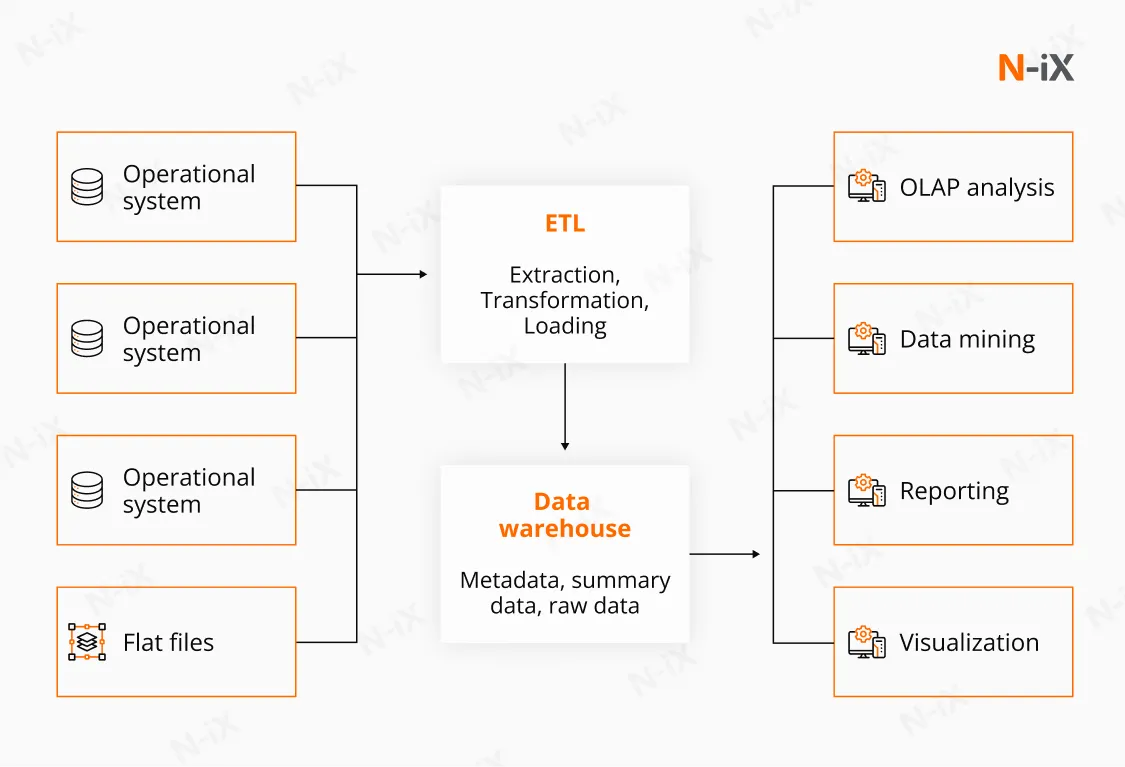
Real-world enterprise use cases
Enterprise data warehouses become the backbone for initiatives that require both scale and control. For example, in a large-scale cloud migration and cost optimization program delivered by N-iX, a centralized data warehouse enabled consistent visibility into infrastructure usage, cost drivers, and automation outcomes across multiple environments. Standardized metrics made it possible to identify inefficiencies, automate remediation, and track savings over time without conflicting interpretations between teams.
Data lake vs data warehouse—discover which option is right for you!

Success!
In another engagement focused on building a scalable analytics platform for an industrial supply company, the data warehouse functions as the integration layer for operational, sales, and supply chain data. By consolidating fragmented sources into a governed analytical model, the organization gained reliable cross-functional reporting and the ability to support advanced analytics without compromising data consistency or performance. In both cases, the warehouse was not just a reporting layer, but the mechanism that made enterprise-wide decisions defensible and repeatable.

What is a data mart?
A data mart is a subject-focused analytical store designed to serve the needs of a specific business unit, function, or team, such as sales, finance, or marketing. It contains a curated subset of enterprise data, structured to answer a narrow set of questions efficiently. In enterprise environments, data marts prioritize relevance and speed for a defined audience, even when that means narrowing definitions, reducing historical depth, or excluding data that falls outside a team's remit.
The primary goal of a data mart is to provide fast, direct access to information that is immediately relevant to a defined audience, without requiring navigation across a full enterprise data warehouse or a broad data lake.
Key characteristics of a data mart
These characteristics capture how data marts are designed, what they prioritize, and where their limitations begin.
- Subject-specific focus: A data mart is organized around a single business domain or analytical theme rather than spanning the full enterprise.
- Limited scope and scale: Its dataset is intentionally constrained, which simplifies models and reduces query overhead compared to an enterprise warehouse.
- Optimized access patterns: Schemas and aggregations are tailored to common departmental queries, resulting in faster and more predictable performance.
- Tactical orientation: Data marts primarily support operational and departmental decision-making rather than cross-functional or executive reporting.
Technical context: types of data marts
Data marts are commonly modeled using dimensional structures, most often star or snowflake schemas, to align with reporting and BI workloads. They may be populated in several ways, depending on enterprise maturity and governance posture:
- Dependent data marts: Built downstream from an existing enterprise data warehouse. This approach preserves consistency of definitions and data quality across the organization.
- Independent data marts: Standalone analytical stores sourced directly from operational or external systems. These are typically created to meet short-term or isolated business needs.
- Hybrid data marts: Combining curated warehouse data with additional operational sources to balance speed with broader context.
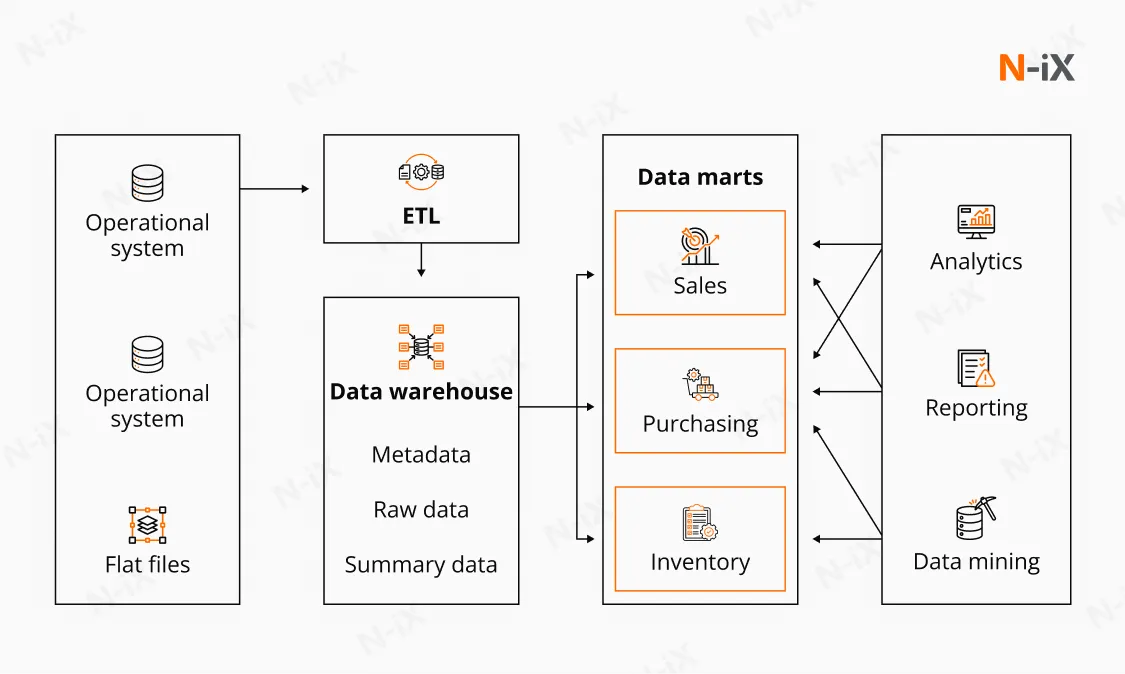
Because of their constrained scope, data marts are typically faster to implement and easier to modify than enterprise data warehouses. That speed is their primary advantage. The trade-off appears over time, as the number of marts grows and coordination across definitions, metrics, and ownership becomes harder to sustain without strong governance.
What is the difference between a data warehouse vs data mart?
Scope
The most consequential data mart vs data warehouse differences lie in how analytical scope and ownership are defined. A data warehouse is designed to serve the organization as a whole. Its scope is intentionally broad, covering multiple domains and supporting cross-functional analysis. Ownership of data definitions, transformations, and metrics is centralized, typically shared between data engineering, analytics, and governance functions.
A data mart operates under a narrower mandate. Its scope is limited to a specific business function or analytical theme, and ownership is localized. The team consuming the data often defines what is included, how it is modeled, and which metrics matter. This proximity enables faster iteration but also fragments ownership. When similar concepts appear across multiple marts, alignment becomes an explicit coordination effort rather than a structural guarantee.
Data volume and structure
Data warehouses retain detailed, historical data across multiple domains. This depth enables trend analysis, forecasting, and advanced modeling that depends on long time horizons and consistent granularity. Data marts typically work with a reduced dataset, often aggregated or filtered to match the analytical needs of a specific audience. The trade-off is intentional: less breadth in exchange for faster queries and simpler models.
Cost dynamics over time
Cost behavior differs markedly between the two models. Data warehouses require higher upfront investment in modeling, integration, and governance. These costs are visible early and often scrutinized. Over time, however, marginal cost per use case decreases as additional analyses reuse the same curated foundation.
Data marts invert this pattern. Initial costs are lower because the scope is limited and dependencies are minimal. Over time, costs compound through duplication of data pipelines, repeated transformations, and reconciliation work across overlapping marts. What begins as a cost-effective solution can become expensive to maintain once coordination and alignment efforts scale.
Usage patterns
Data warehouses serve a broad audience, including analysts, data scientists, and reporting teams who need access to consistent, enterprise-wide data. Data marts are designed for narrower consumption patterns, often supporting dashboards, reports, or models tied to a single function. Enterprise data warehouse vs data mart schemas and aggregations reflect known use cases rather than exploratory analysis.
Architectural implications
The choice between a data mart vs data warehouse shapes how analytics evolves. Warehouses favor long-term stability and comparability. Data marts favor speed and local optimization. Most enterprise environments use both, but problems arise when their roles overlap or remain undefined. Without clear boundaries, the organization accumulates multiple versions of key metrics and spends increasing effort reconciling results rather than acting on them.
Governance
Governance in a data warehouse is embedded into the architecture. Standardization, lineage tracking, and validation are treated as prerequisites rather than afterthoughts. This approach reduces ambiguity in reporting and supports auditability, especially in regulated environments. The trade-off is overhead: changes move more slowly because they must preserve consistency across a wide set of downstream consumers.
Data marts shift governance responsibility closer to the business. Controls are lighter, and enforcement depends on local discipline rather than centralized mechanisms. This works as long as the scope remains contained. As the number of data marts grows, risk exposure increases in less visible ways. Diverging definitions, undocumented logic, and inconsistent refresh cycles introduce uncertainty that surfaces only when results are compared or decisions are challenged.
|
Dimension |
Data warehouse |
Data mart |
|
Analytical scope |
Enterprise-wide, cross-functional |
Domain- or department-specific |
|
Primary purpose |
Consistent reporting and analysis across the business |
Fast access to insights for a specific function |
|
Data sources |
Many internal and external systems |
Few sources, often downstream of a warehouse |
|
Data volume |
Large-scale, often terabytes or more |
Limited and tightly scoped |
|
Decision horizon |
Strategic and longitudinal |
Tactical and operational |
|
Governance role |
Centralized definitions and controls |
Localized ownership with constrained governance |
|
Time to implement |
Longer, incremental build-out |
Faster to deliver and adjust |
When to choose data mart vs data warehouse?
The decision between a data warehouse vs mart is rarely binary. It depends on how analytical responsibility is distributed, how much inconsistency the organization can tolerate, and how decisions are expected to scale over time. In practice, the choice reflects priorities around authority, speed, and control rather than technology alone.
A useful way to approach this decision between data mart vs data warehouse is to start from intent: what problem the analytics layer is expected to solve now, and what it must continue to support as the organization grows.
When a data warehouse is the right choice
A data warehouse is appropriate when analytics must support cross-functional decisions that persist over time. Its value increases as the number of stakeholders, data sources, and regulatory constraints grows.
- Enterprise-wide consistency is required. When metrics must be comparable across departments and business units, a centralized structure becomes necessary. Without it, discrepancies turn into recurring reconciliation work rather than isolated exceptions.
- Decisions depend on historical continuity. Strategic planning, forecasting, and performance analysis rely on consistent historical data. Warehouses are designed to preserve this continuity and make changes traceable rather than implicit.
- Governance and auditability matter. Where reporting must withstand internal or external scrutiny, the ability to explain how numbers were produced becomes as important as the numbers themselves. Warehouses provide stable structures for lineage, validation, and control.
- Analytical complexity is expected to grow. As new use cases emerge, a warehouse reduces marginal effort by reusing existing integrations and definitions instead of rebuilding them for each initiative.
When a data mart makes sense
A data mart is appropriate when the scope of analysis is clearly bounded, and speed of delivery takes precedence over cross-functional alignment. Its effectiveness depends on how deliberately those boundaries are set.
- The analytical need is domain-specific. When a team requires focused insight within a single function, a narrowly scoped data mart avoids unnecessary complexity and accelerates access to relevant data.
- Change cycles are short. Teams operating with frequent iteration benefit from local control over models and logic, especially when requirements evolve faster than centralized processes can accommodate.
- Dependencies must be minimized. Data marts reduce reliance on shared pipelines and coordination with other teams, which can be valuable during early-stage initiatives or time-sensitive programs.
- Ownership is intentionally localized. A data mart works best when accountability for definitions and outputs is clear and contained within a single domain.
How data mart vs data warehouse coexist in mature enterprises
At this point, you may be asking whether data mart vs warehouse can complement each other without creating duplication or inconsistency. In mature enterprises, they can, but only when their roles are clearly separated and intentionally designed.
The data warehouse provides an integrated, governed foundation for establishing enterprise-wide definitions, historical continuity, and cross-domain relationships. Data marts build on top of that foundation, shaping subsets of data to meet the analytical needs of specific domains without redefining core meaning.
Data mart vs data warehouse coexistence works because responsibilities are separated with intent. The data warehouse absorbs integration complexity and governance overhead so that enterprise reporting remains comparable and defensible. Data marts reduce friction for operational teams by presenting data in forms aligned with how those teams work, query, and decide. Instead of competing for authority, the two structures reinforce each other: the warehouse protects consistency, while data marts protect momentum.
The model remains stable when boundaries are explicit and enforced. Enterprise metrics, reference data, and validation logic originate in the warehouse. Data marts consume and extend that foundation through domain-specific aggregations, calculations, and access controls. When those rules are followed, analytics can scale across teams without multiplying definitions or reconciliation work.
Mature coexistence of data warehouse vs data mart relies on a small set of principles:
- The data warehouse owns enterprise definitions and historical truth.
- Data marts inherit data from the warehouse and adapt it for focused use cases.
- Governance is centralized at the core and applied selectively at the edges.
- Data marts are reviewed regularly as the scope and priorities change.
With these constraints in place, data mart vs data warehouse function as a single system with distinct roles, enabling analytics to scale without eroding trust in the results.
Where data lakes fit in the data warehouse vs data mart system
Up to this point, the discussion has focused on data warehouses and data marts because they sit closest to business-facing analytics. Data lakes come into play for a different reason. In modern architectures, most enterprise data rarely arrives in a clean, structured form, nor does its value always become clear at ingestion time. Ignoring the role of the data lake creates an incomplete picture of how data marts and data warehouses are actually fed, constrained, and evolved in practice.
An enterprise data lake is not an alternative to a data warehouse or a data mart. It addresses a different stage of the data lifecycle and solves a different class of problems. Understanding where it fits clarifies why warehouses and marts behave the way they do, and why certain architectural tensions keep recurring.
Data lake as an option
A data lake is a centralized repository designed to store data in its native format, at scale, with minimal upfront transformation. Its defining feature is flexibility. Data can be ingested before a specific analytical use case is known, preserving raw detail that might be required later for new forms of analysis.
Several characteristics distinguish data lakes from warehouses and marts:
- Schema applied at use time: Data is stored without enforcing a rigid structure upfront, allowing different consumers to interpret it differently.
- Support for diverse data types: Data lakes support structured, semi-structured, and unstructured data within a single environment.
- Cost-efficient scale: Storage is optimized for volume over immediate query performance, making it suitable for large, growing datasets.
- Exploration and modeling focus: Data lakes support data preparation, experimentation, and advanced analytics workflows that require raw inputs.
Difference between data warehouse vs data lake vs data mart
Data warehouses, data lakes, and data marts often coexist in the same environment, yet they are expected to solve different problems. Comparing data mart vs data warehouse vs data lake is necessary to understand where analytical responsibility begins, where it is enforced, and where it is intentionally narrowed.
At a high level, the separation comes down to when data is prepared, how broadly it is governed, and who consumes it.
- A data lake captures data early and with minimal constraints. It stores raw, semi-structured, and unstructured data in native formats, preserving detail before specific use cases are known. This makes it suitable for exploration, experimentation, and advanced analytics, but unsuitable for consistent reporting without further processing.
- A data warehouse operates later in the pipeline. It integrates and standardizes data across domains, enforcing shared definitions and historical consistency. Its role is to support enterprise-wide analysis where comparability and traceability matter.
- A data mart narrows that scope further. It exposes a curated subset of warehouse data tailored to a specific domain or function, optimizing access and performance for focused analytical use cases without redefining core meaning.
|
Dimension |
Data lake |
Data warehouse |
Data mart |
|
Primary role |
Raw data capture and exploration |
Enterprise-wide analytical foundation |
Domain-specific analytical delivery |
|
Data state |
Raw, minimally processed |
Cleaned, standardized, modeled |
Filtered and aggregated |
|
Schema approach |
Applied at the time of use |
Defined and enforced |
Inherited and simplified |
|
Typical users |
Engineers, data scientists |
Analysts, reporting teams |
Departmental users |
|
Governance level |
Light at ingestion |
Strong and centralized |
Scoped and inherited |
|
Change tolerance |
High |
Controlled |
High within the defined scope |
Set up the right data architecture solution
The value of a data architecture decision becomes visible only over time. It shows up in how quickly teams can answer new questions, how often numbers need to be reconciled, and how confidently decisions can be defended when they matter most. This is where experience matters.
At N-iX, we help organizations assess their current data landscape, define the right balance between centralized and domain-level analytics, and translate that design into working systems. Our teams work across data lakes, enterprise data warehouses, and data marts as an integrated whole, covering architecture design, platform implementation, and governance that functions in a real environment. We help define the role of each layer, align it with business priorities, and implement it in a way that remains manageable as scale and complexity increase.
If you are reviewing your current data landscape or planning a new analytics initiative and want clarity on which architecture fits your business context, N-iX can help.

FAQ
What is a data mart vs data warehouse?
A data warehouse is a centralized analytical system that integrates data across the organization using shared definitions and governance. A data mart is a focused subset of that data, designed to support a specific business function or analytical use case. The warehouse establishes consistency at scale, while the data mart optimizes access and performance within a defined scope.
How do data lake vs data warehouse vs data mart differ?
A data lake stores raw data in its native format to preserve flexibility for future use and advanced analytics. A data warehouse standardizes and structures selected data to support consistent, enterprise-wide reporting. A data mart further narrows that data to serve focused, high-frequency analytical needs within a specific domain.
When should an organization use both a data warehouse and data marts?
Organizations typically use both when they need enterprise-wide consistency alongside fast, domain-specific analytics. The data warehouse provides standardized definitions and historical continuity, while data marts expose curated subsets tailored to specific operational needs. This setup works when data marts inherit definitions from the warehouse rather than redefining them independently.
Have a question?
Speak to an expert


