
In 2026, data is one of the most valuable assets organizations own, yet it’s one of the most difficult to manage. On one hand, data is spread across numerous systems, platforms, and domains (each with its own set of standards). On the other traditional centralized architectures (data lakes, data warehouses) are buckling under the weight of this complexity.
How to tackle these issues? We suggest going for data mesh. It offers a decentralized solution by distributing data ownership to business domains while maintaining centralized governance standards. Snowflake supports this model, providing a cloud platform with native capabilities to share governed data across domains and external partners, without duplication.
This article breaks down how Snowflake data mesh works, where it delivers the most value, and what a practical implementation looks like with N-iX as a Snowflake consulting partner.
What is a data mesh?
A data mesh is an architectural approach that organizes data around business domains (e.g. marketing, sales, customer service. Domain teams take ownership of their data and treat it as a product: reliable, well-documented, and ready for others across the organization to find and use.
This shift eliminates many of the bottlenecks that plague traditional architectures, where every data request flows through a central team. Importantly, it doesn't replace existing storage technologies such as data lakes or data warehouses; it reframes them. Instead of acting as a single shared repository, they become infrastructure that supports multiple independent domains, each operating on their own terms.
The closest analogy is microservices architecture, where a large application is broken into smaller, loosely coupled services, each with its own logic. Data mesh applies the same thinking to data: decentralized ownership, domain autonomy, and the ability to scale without everything depending on one central point.
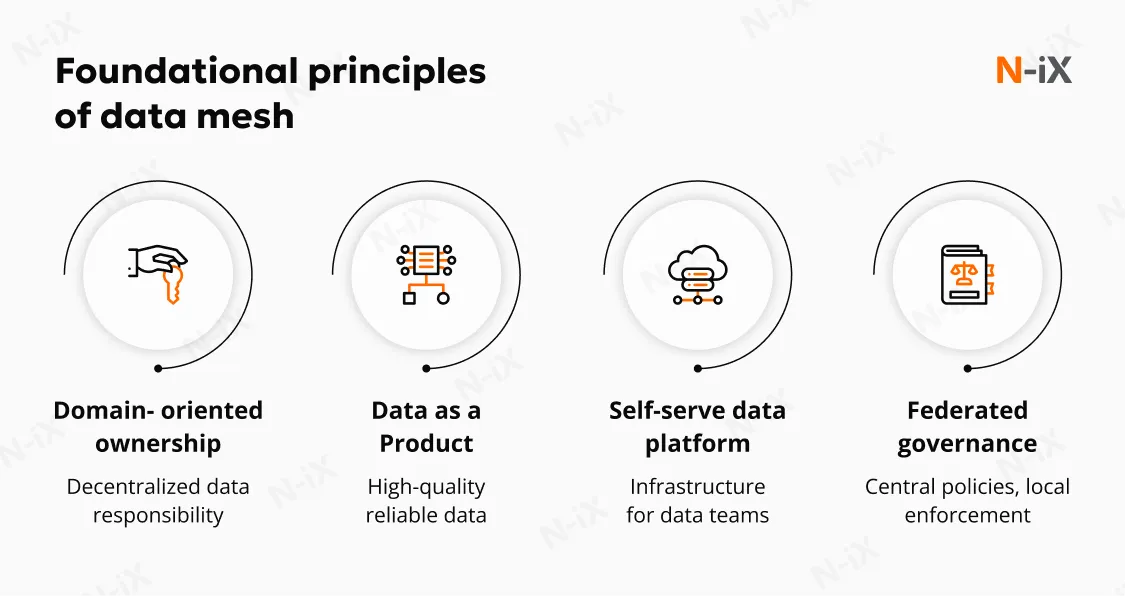
How a data mesh works
- Domain experts analyze existing data assets and identify how they are used across the organization, grouping them into clearly defined data domains.
- Each domain is enriched with relevant business context, ensuring the data reflects real operational processes and business priorities.
- Domain teams design and develop data products based on these domains and usage patterns, ensuring they are reliable, well-documented, and ready for consumption.
- These data products are then registered in a shared catalog and made discoverable, allowing other teams to easily access and reuse them according to their business needs.
Why do organizations need a data mesh?
As data volume and complexity grow, traditional architectures can struggle to keep up, creating bottlenecks, slowing down teams, and making reliable access to information harder to maintain. A data mesh solves this by:
- Giving business units autonomy to manage and govern their own data domains
- Reducing reliance on centralized data teams and eliminating bottlenecks
- Enabling faster and more reliable access to trusted data across the organization
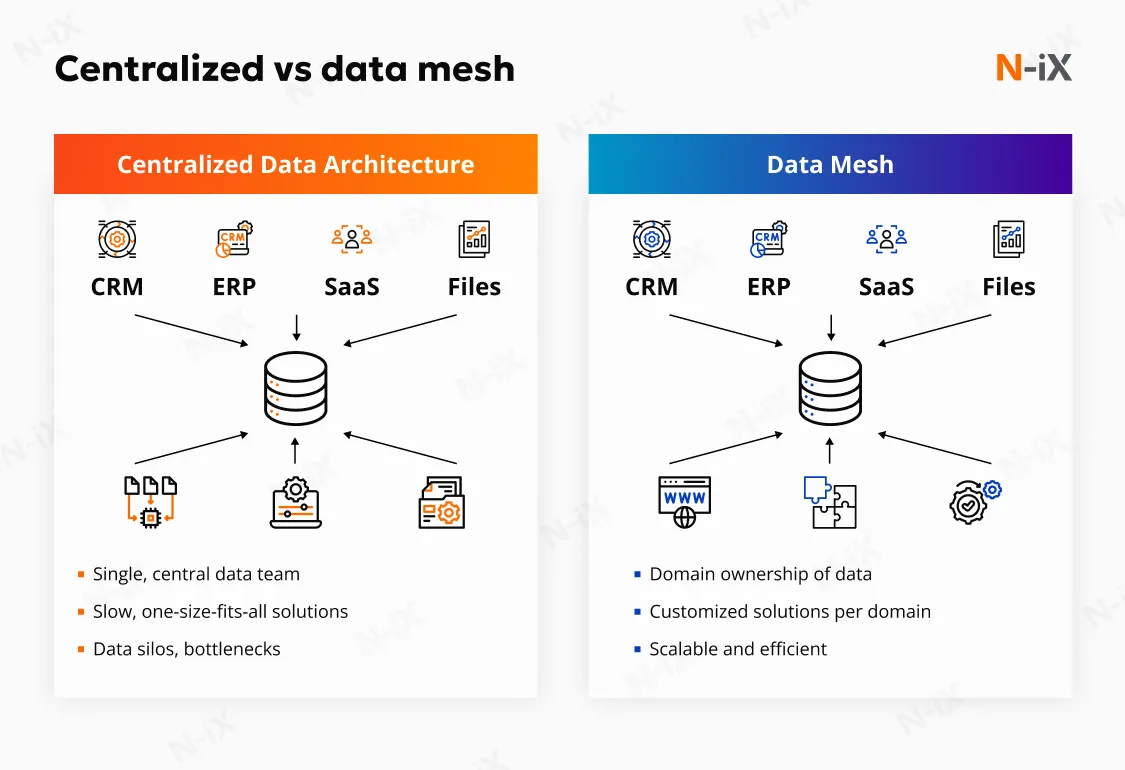
Why Snowflake is a strong platform for data mesh
Organizations can create multiple Snowflake accounts across different cloud regions and platforms, each hosting logically separate databases. This flexibility empowers domain teams to work autonomously with their own compute and storage resources while still using a centralized platform to securely share datasets.
This architecture consists of multiple domain-owned datasets shared via Snowflake’s secure data-sharing capabilities and governed by centralized policies, including RBAC, masking policies, and object tagging. Each domain team manages its own compute resources through virtual warehouses while sharing trusted data products across the organization. Snowflake’s unique design makes it a good solution for implementing a data mesh architecture for several reasons:
Decentralized ownership with centralized governance
Snowflake enables business domains to manage their own data while maintaining organization-wide governance. Features such as role-based access control (RBAC), dynamic data masking, and row-level policies ensure that data remains secure and compliant across all domains. For example, iovation used Snowflake to improve governance, reducing the overhead of managing security policies across multiple systems, and experienced a 214% ROI with a 0.5-year payback period.
Scalable and isolated compute
Snowflake's architecture separates compute from storage, meaning domain teams can scale their resources independently without competing for capacity. Virtual warehouses isolate workloads entirely; analytics queries, data pipelines, and machine learning jobs run in parallel without interfering with each other. Business teams get quicker access to insights, decisions get made on current data rather than yesterday's exports, and engineering teams stop firefighting performance issues caused by workloads stepping on each other.
Secure data sharing across domains
Teams can share live data across domains without duplicating it, ensuring everyone works from the same current source. This reduces both storage overhead and the risk of inconsistencies that arise when multiple copies of the same dataset circulate across the organization.
Centralized policy management
Snowflake enhances governance through dynamic data masking and row access policies, enforcing security at the column and row levels. These policies travel with the data, ensuring consistent security regardless of where or how the data is accessed. Additionally, tagging data products with sensitivity or ownership labels helps automate policy enforcement.
Maximized value from distributed data
This approach is particularly valuable for organizations running complex ecosystems across CRMs, ERPs, and SaaS platforms, where data is naturally scattered and duplication costs add up quickly
Cost-efficient scaling
Snowflake's consumption-based pricing means you only pay for what you actually use. Compute resources scale up or down on demand, giving teams the flexibility to support growing workloads without overprovisioning infrastructure or locking into fixed costs.
Snowflake capabilities for building and running a data mesh
|
Data mesh principle |
How Snowflake supports it |
|
Domain-oriented ownership |
Separate Snowflake accounts or databases for domains, internal data provider profiles, and a distributed architecture aligned with business domains |
|
Data as a product |
Snowflake Horizon Catalog listings, automated data pipelines, built-in data quality metrics, object tagging, and usage analytics for tracking data products |
|
Self-service data platform |
Instant resource scaling, highly available infrastructure across availability zones, Git integration and Snowflake CLI, cross-domain monitoring and cost attribution, integration with third-party tools |
|
Federated governance |
Snowflake Horizon Catalog for discovery, role-based access control (RBAC), fine-grained access policies, lineage tracking, and governance dashboards |
While Snowflake provides the technical foundation for data mesh, implementing this architecture still presents several organizational and technical challenges.
Challenges in implementing Snowflake data mesh and how N-iX addresses them
When organizations adopt a data mesh architecture in Snowflake, they often encounter both organizational and technical challenges. As a technology partner, N-iX helps address these complexities and supports successful implementation. Below are some of the key challenges and how they can be resolved.
Lack of domain data knowledge
While domain teams possess deep business expertise, they often lack technical skills in data management, such as quality control, schema design, and governance. N-iX bridges this gap by providing data literacy training for domain teams. We empower teams to manage and govern data products efficiently with Snowflake’s built-in tools, such as dynamic data masking and RBAC. Additionally, N-iX assists in designing data quality control frameworks that ensure high-quality, usable data products.
Balancing autonomy with accountability
Allowing domain teams autonomy over their data products requires clear guidelines to maintain accountability for data quality, security, and compliance. We implement Snowflake's governance features, such as data tagging, row access policies, and auditing, to ensure security while allowing each domain to manage its data independently.
Maintaining cross-domain consistency
Keeping formats, definitions, and quality standards aligned across independently managed domains is one of the organizational challenges in a distributed architecture. Our team addresses this through data contracts and consistent metadata management, using Snowflake's sharing capabilities to enforce alignment at the platform level. So standards travel with the data rather than depending on each team to apply them manually.
Implementing a unified governance framework
A federated model demands a careful balance: central oversight to ensure security and compliance, with enough domain-level autonomy to stay practical. We implement this balance using Snowflake's built-in capabilities: dynamic data masking, row access policies, and object tagging. These tools enforce organization-wide standards at the platform level while giving domain teams room to define rules specific to their own context.
Interoperability and data sharing
Managing stable cross-cloud and cross-region workflows without duplicating data is one of the more technically demanding aspects of a distributed architecture, particularly when remote queries and advanced security integrations are involved. Our engineers have deep experience with multi-cloud environments and cross-region interoperability on Snowflake. We handle the configuration, security protocols, and governance setup so that domain teams can collaborate across regions without added complexity.
Managing legacy migration complexity
Moving from on-premise systems to a distributed cloud architecture isn't just a technical lift, it requires rethinking how data is structured, owned, and moved through pipelines. N-iX's data engineers specialize in this transition, guiding organizations from monolithic setups to a domain-driven architecture on Snowflake with minimal disruption. We plan each migration step carefully, ensuring data integrity is preserved throughout and the resulting cloud environment is optimized for long-term performance.
How N-iX helps organizations implement Snowflake data mesh
Adopting this architecture involves both technical complexity and organizational change, which is where having an experienced partner makes a meaningful difference.
N-iX is a global Snowflake consulting partner with deep expertise in enterprise data engineering, cloud modernization, and large-scale analytics platforms. With over 23 of experience delivering complex data platforms for Fortune 500 companies, we help organizations transition from a fragmented data landscape to a governed, domain-driven architecture that scales with the business.
We help organizations move from concept to production-ready data mesh Snowflake platforms by combining expertise in:
- Snowflake architecture and platform design
- Enterprise data engineering
- Cloud data platform modernization
- Domain-driven data governance
- Large-scale data migration and integration
Our engineers work closely with enterprise stakeholders to design Snowflake environments that support domain ownership, scalable data sharing, and centralized governance, the key foundations of a successful data mesh strategy. Whether you're planning your first Snowflake deployment, modernizing legacy data platforms , or scaling an existing analytics environment, N-iX can help you implement a Snowflake data mesh architecture that delivers measurable business value.

FAQ
What is Snowflake data mesh?
A Snowflake data mesh is a decentralized data architecture that lets individual business domains own and manage their own datasets, while centralized governance and security policies apply consistently across all of them. The result is an organization that can scale analytics and improve data accessibility without the bottlenecks that come with relying on a single, central data team.
Why is Snowflake well-suited for data mesh architecture?
Snowflake is well-suited for data mesh architecture because it supports distributed data environments while maintaining centralized governance. It enables secure data sharing without duplicating datasets, allows domain teams to scale workloads independently through virtual warehouses, and provides built-in governance features such as RBAC and data masking. These capabilities help organizations implement domain-oriented data ownership while maintaining consistent security and compliance across the platform.
How do organizations implement data mesh in Snowflake?
Organizations implement data mesh in Snowflake by first identifying key business domains and assigning clear data ownership to domain teams. Each domain then develops its own data products that are well-documented, discoverable, and designed for reuse across the organization. At the same time, companies establish governance standards that define security, access control, and compliance policies to ensure consistent data management.
Because this transformation involves both technological and organizational change, many enterprises work with experienced partners like N-iX to design and implement Snowflake data mesh architectures, ensuring they scale reliably as data volumes and team complexity grow.
Have a question?
Speak to an expert


