
Many AI tools used in enterprises today behave in ways that feel strikingly similar. A conversational system produces fluent responses. A visual model turns a short description into an image. A coding assistant continues a function with minimal guidance. From the outside, these experiences blur together, which is why generative development AI and large language models (LLMs) are often treated as interchangeable terms in strategy discussions.
They are not the same thing, though. Generative AI is a broad category that covers systems capable of producing new artifacts across multiple modalities. At the same time, large language models represent a specialized class of generative models that generate and reason over tokenized language sequences, most commonly natural language and source code. Understanding how generative AI vs LLM concepts differ, and how they relate, is essential for enterprises that want to design reliable AI systems, set realistic expectations, and avoid building strategies around the wrong abstraction.
What does generative AI offer?
Generative AI refers to a class of artificial intelligence systems built to produce new content rather than analyse, classify, or label existing data. The defining characteristic lies in the creation of output. Instead of answering whether something fits a category or meets a threshold, generative systems construct artefacts that did not previously exist, drawing on patterns learned during training. That distinction matters because it determines how such systems behave, where they add value, and where limitations must be managed deliberately.
At a technical level, generative AI sits within Machine Learning and relies on deep neural networks trained on large, diverse datasets. Training focuses on learning the underlying structure of data: linguistic patterns in text, spatial relationships in images, acoustic properties in audio, or structural constraints in code and scientific representations. Once trained, a generative model produces output by navigating a learned probability space, assembling new sequences that align with the patterns it has internalised rather than retrieving stored examples.
Generative AI operates across multiple modalities, which explains its rapid expansion beyond text-based applications. Generative techniques already appear across enterprise environments, often embedded inside familiar tools rather than presented as standalone AI products.
Common output categories include:
- Text and language, covering documents, summaries, code, structured content, and conversational responses.
- Visual content, including images, illustrations, animations, and video frames derived from textual or visual prompts.
- Audio, such as synthetic speech, music, and sound effects, is generated with controllable characteristics.
- Technical and domain-specific artefacts, ranging from 3D models and design assets to synthetic datasets and molecular structures used in scientific research.
Automated document drafting, report generation, code scaffolding, synthetic data creation, and design assistance all rely on generative mechanisms, even when users do not explicitly label them as such. Multimodal generative AI models extend these capabilities by operating across multiple data types within a single system. Such models combine language, visual, and sometimes audio representations to generate outputs that cross traditional modality boundaries.
What defines generative AI in real-world use is not the model alone but the system built around it. Training data selection, prompt design, retrieval mechanisms, validation logic, and integration with existing software all shape output quality and reliability.


What is LLM?
Large language models are neural network models trained on large-scale textual data to model language as a sequence. The core function is straightforward but powerful: given a sequence of tokens, estimate what token is most likely to come next. Every capability an LLM exhibits emerges from repeating that operation across long contexts.
Within the broader landscape of Artificial Intelligence, LLMs sit at the intersection of Machine Learning and generative AI, with a narrow but powerful focus on language-based tasks, including natural language and source code.
An LLM begins with a statistical representation of language. Training exposes the model to extremely large text corpora, often spanning billions or trillions of tokens drawn from books, articles, documentation, and publicly available code. Through that process, the model learns how words, symbols, and structures tend to appear in relation to one another. Output generation follows the same principle. Given a sequence of tokens, the model estimates the probability of what should come next and produces a continuation that aligns with the patterns it has internalised.
Capabilities LLMs are strong at
In practice, LLMs support a wide range of capabilities that centre on language transformation and synthesis. Common applications include drafting and editing written content, summarising long documents, translating between languages, generating or refactoring source code, and powering conversational interfaces that can maintain context across interactions. Each of these use cases depends on the same underlying mechanism: probabilistic language generation constrained by prompt structure, system design, and external context.
- Natural language understanding: Parsing intent, extracting meaning, and mapping unstructured text into structured representations.
- Natural language generation: Producing coherent, context-aware text across documents, conversations, and reports.
- Reasoning patterns within constraints: Following chains of logic, applying rules expressed in language, and synthesising information, provided the task fits within the model’s context window.
- Code generation and explanation: Writing, refactoring, and explaining source code and configuration artefacts expressed as formal languages.
Read also: How Machine Learning differs from generative AI
How generative AI and large language models relate
The relationship between generative AI vs LLM is best understood as a structural hierarchy. Artificial Intelligence forms the outer layer. Machine learning sits within it. Deep learning narrows the scope further. Large language models occupy a specific position inside deep learning, while generative AI spans across multiple model families and modalities.
In that structure, generative AI describes a capability - the ability to produce new artefacts. LLMs describe a class of models - systems trained to generate and interpret language.
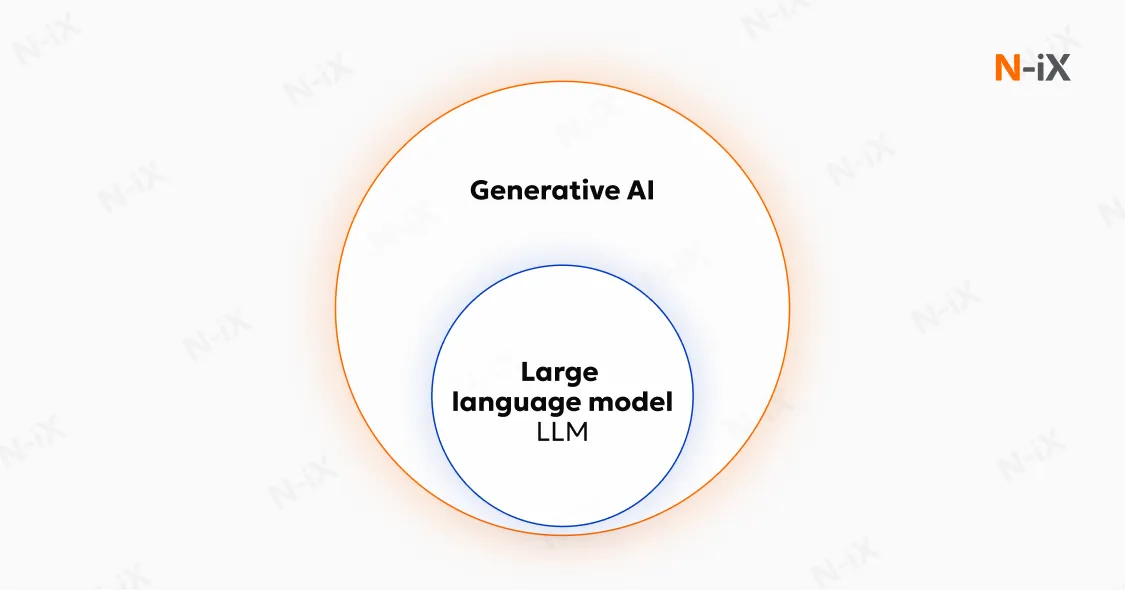
LLMs are a subset of generative AI
Generative AI refers to systems designed to create new outputs rather than classify, rank, or predict labels. Large language models represent a specialised subset within that category. Their scope is language, expressed as tokenised sequences. Natural language and source code both fit naturally into that framing. When an LLM generates text, it operates squarely within generative AI. When a diffusion model generates images or video, it also operates within generative AI, without involving language at all. At a structural level, the relationship can be summarised clearly:
- Generative AI represents the broader system layer responsible for content creation across modalities.
- LLMs represent one class of generative models, optimised for language understanding and generation.
- Overlap occurs when the generated artefact is textual or language-based.
That hierarchy matters because architectural decisions follow the capabilities they support. Treating LLMs as a universal generative layer obscures the fact that other generative tasks rely on different representations, training regimes, and evaluation criteria. Systems designed with that distinction in mind tend to separate concerns more cleanly and scale with fewer hidden dependencies.
A concise way to express the relationship remains accurate: every LLM is a generative AI system, but generative AI extends far beyond LLMs.
The generative AI vs LLM difference becomes clearer when separating scope from execution.
- Scope: Generative AI spans multiple modalities and output types. LLMs focus on language and language-like structures.
- Modality: Traditional LLMs operate over text and code. Generative AI includes visual, audio, spatial, and hybrid outputs, in addition to language.
- Mechanism: LLMs generate output through probabilistic token prediction, modelling how sequences of symbols evolve in context. Other generative systems apply similar statistical principles to different data structures, such as pixels, audio waveforms, or three-dimensional representations.
Recent multimodal architectures have blurred the boundary between generative AI vs LLM at the interface level. Language models now coordinate with visual and audio encoders, allowing a single system to accept and produce multiple data types. Despite that convergence, responsibilities remain distinct. The LLM handles language reasoning and instruction following, while perceptual fidelity and modality-specific coherence depend on specialised generative components.
From an architectural perspective, robust systems treat LLMs as one component within a broader generative AI pipeline:
- Language models interpret intent, structure output, and connect concepts across domains.
- Specialised generative models handle images, audio, or other non-text artefacts.
- Orchestration and validation layers enforce grounding, consistency, and control.
What generative AI can do that LLMs cannot
Generative AI extends well beyond language-centric generation. Non-text modalities rely on data structures and constraints that language models are not designed to handle natively. Image and video generation depend on spatial coherence. Audio synthesis depends on temporal and acoustic continuity. Three-dimensional artefact generation introduces geometric constraints that do not map cleanly to token sequences.
End-to-end multimodal generation often requires coordinated pipelines rather than a single model. Outputs may combine visuals, metadata, structured fields, and descriptive text into one artefact. Domain-specific systems further amplify this separation. Product design, medical imaging, and scientific simulation each rely on specialised generative mechanisms that cannot be substituted with language models without significant loss of fidelity.
What LLMs do better than other generative models
Language models excel at abstraction and synthesis. Text acts as a compression layer for knowledge, allowing complex ideas, rules, and relationships to be expressed compactly. LLMs exploit that property to generalise across domains without retraining for each specific subject.
Reasoning expressed through language allows LLMs to connect concepts that would remain isolated in modality-specific systems. Cross-domain synthesis, explanation, summarisation, and transformation all benefit from language as a unifying medium. Code generation extends that advantage by treating formal languages as structured text, enabling consistent reasoning across documentation and implementation.
The overlap between LLM AI vs generative AI occurs when language generation is the objective. Outside that boundary, generative AI continues without LLM involvement.
Where LLMs fit and where generative AI systems are required?
Treating LLM vs generative AI terms as interchangeable obscures an important design question. Enterprise value depends on whether the dominant requirement is language-centric reasoning or multimodal creation under control.
Where LLMs fit best: language-intensive workloads
Large language models are optimized for understanding, transforming, and generating language at scale. Training on vast text corpora allows them to capture grammar, semantics, structure, and contextual nuance. Output emerges from statistical sequence modeling, which makes LLMs particularly effective where meaning is encoded primarily in text.
Typical enterprise scenarios where LLMs fit naturally include:
- Conversational interfaces: Sustained dialogue handling, intent interpretation, and context preservation across multi-turn interactions in customer support or internal tools.
- Summarization and analysis of long-form text: Condensing large volumes of documentation, contracts, policies, or clinical notes into structured, actionable outputs.
- Translation and localization: Context-aware language conversion that preserves intent, tone, and domain-specific terminology rather than performing literal substitution.
- Knowledge extraction from unstructured sources: Identifying entities, clauses, or relationships embedded in documents, emails, or reports.
- Structured language output: Drafting reports, specifications, or formal documents that must follow defined templates and maintain logical consistency.
In each case, the core challenge is linguistic interpretation and synthesis. LLMs perform well because language itself provides the abstraction layer.
Where broader generative AI systems become necessary
Once generation extends beyond language, a different class of capability is required. Visual, auditory, spatial, and scientific artefacts rely on representations that do not map cleanly to token sequences. Broader generative AI systems address those needs by combining specialised models, orchestration logic, and validation layers.
Scenarios that typically require full generative AI systems include:
- Visual asset generation: Image creation, illustration, branding materials, and design artefacts where spatial coherence and visual fidelity matter.
- Video and three-dimensional content: Asset generation for media production, simulation, gaming, digital twins, or product design, often requiring temporal and geometric consistency.
- Audio and speech synthesis: Voice generation, sound design, and music composition based on acoustic and temporal patterns rather than symbolic language structure.
- Scientific and technical generation: Synthetic data creation, molecular simulation, or engineering design exploration where domain constraints are encoded mathematically or physically.
- Exploratory creative workflows: Use cases where variation, diversity, and iteration are more important than strict consistency or determinism.
In these contexts, language may still play a coordinating role, but it is not the primary medium of generation.
What are the limitations of LLM vs generative AI?
The relationship between generative AI vs LLM is hierarchical. Generative AI defines the broader category of systems that produce new artefacts, while LLMs represent a specialised subset focused on language. Because both rely on deep learning trained over large datasets, many of their limitations stem from the same structural properties. Differences appear primarily in how those limitations surface across text, visual, and multimodal outputs.
Shared fundamental limitations
Both generative AI systems and LLMs learn patterns rather than facts. Outputs reflect statistical regularities observed during training, not an understanding of reality or intent. That foundation introduces several persistent risks.
- Hallucinations: Outputs may be fluent and internally consistent while remaining factually incorrect or logically unsound. The behaviour is structural. Models optimise for plausibility within learned distributions rather than for alignment with external truth.
- Inherited bias: Training data reflects historical and societal imbalances. Without deliberate mitigation, generated outputs may reinforce biases related to gender, race, age, geography, income distribution, access to services, or historical power asymmetries. Such bias is often subtle, context-dependent, and difficult to detect at scale because it emerges from correlations learned across large populations rather than explicit labels.
- Security and privacy exposure: Models can inadvertently surface sensitive information encountered during training or interaction. Prompt-based attacks, data leakage, and indirect inference remain active concerns in operational settings.
- Intellectual property risk: Generated content may closely resemble protected material, exposing the company to legal and reputational risks. Questions around attribution, originality, and derivative content remain unresolved in many jurisdictions.
- Lack of semantic understanding: Models manipulate symbols based on learned syntax and probability, not meaning. Users often overestimate cognitive capability, a dynamic reinforced by fluent language and conversational interfaces. Apparent understanding does not equate to comprehension or judgment.
How limitations differ between LLMs and broader generative AI
While the foundational risks overlap, the output modality of generative AI vs LLM introduces distinct constraints that shape how limitations manifest.
|
Dimension |
Large language models |
Broader generative AI |
|
Primary limitation |
Boundaries in formal reasoning, arithmetic precision, and multi-step symbolic logic |
Difficulty maintaining visual or temporal consistency across complex scenes |
|
Knowledge constraints |
Dependence on training cutoffs and provided context for factual accuracy |
Sensitivity to dataset coverage and representativeness for visual realism |
|
Resource intensity |
High training and inference cost driven by parameter scale and context length |
Significantly higher energy and compute demands for video and 3D generation |
|
Output depth |
Strong linguistic coherence and abstraction |
Limited intentionality and emotional nuance compared to human-created artefacts |
Language models struggle where exactness and verification are required. Visual and multimodal systems struggle when continuity, spatial reasoning, or temporal coherence dominate. Neither class resolves the other’s weaknesses by scale alone.
System-level considerations introduce another layer of limitation. Production environments require specialised hardware, sustained compute capacity, and supporting infrastructure to manage heat, latency, and throughput. Cost profiles remain sensitive to usage growth and model choice.
More importantly, the reliability of generative AI vs LLM does not emerge automatically. Human oversight remains necessary for quality control, ethical validation, and escalation in high-impact workflows. Without explicit review paths and accountability, generative outputs can introduce misinformation, compliance breaches, or reputational harm at scale.
Bring generative AI and LLMs into your workflow
Moving from understanding to execution is where most initiatives either mature or stall. The distinction between generative AI as a system capability and LLMs as a specialised model class becomes operational only when embedded into real workflows with clear ownership, controls, and outcomes.
Effective adoption starts by anchoring AI use to concrete processes rather than isolated tools. Language models fit naturally where reasoning, synthesis, and interaction are required. Broader generative systems belong where creation spans multiple modalities or where outputs must be assembled, validated, and reused across steps. Designing workflows around those boundaries avoids overloading a single model and reduces downstream rework.
If the goal is to move beyond experimentation and into sustained value, partnering with teams that have designed, integrated, and governed such systems in enterprise environments shortens the path considerably. At N-iX, generative AI and LLMs are approached as components of larger workflows, aligned to business processes, risk profiles, and long-term platform strategy. Our approach is grounded in hands-on experience delivering AI, data, and software systems for large, regulated, and technology-driven organisations.

FAQ
What is generative AI vs LLM, and how do they differ?
Generative AI refers to a broad class of systems designed to create new content across multiple modalities, including text, images, audio, and video. Large language models are a specialised subset of generative AI focused specifically on language and language-like structures such as code. All LLMs are generative AI systems, but many generative AI systems do not involve language models at all.
Are large language models enough to build enterprise AI solutions?
LLMs are effective for language-centric tasks such as summarisation, conversational interfaces, and text analysis, but they are rarely sufficient on their own in production environments. Enterprise solutions typically require additional components such as retrieval, validation, orchestration, and deterministic logic. Without those layers, systems tend to suffer from reliability, cost, and governance issues as usage scales.
When should an enterprise use generative AI beyond LLMs?
Broader generative AI systems are required when outputs extend beyond text into images, video, audio, or complex structured artefacts. They are also necessary when workflows involve multiple steps, persistent state, or strict quality constraints. In such cases, language models may still play a coordinating role, but they are not the primary generator.
What are the main risks of using generative AI vs LLM in production?
Key risks include hallucinations, bias propagation, data privacy exposure, and inconsistent outputs due to probabilistic generation. Operational risks also arise from cost volatility, limited explainability, and reliance on the quality of training data. Mitigating these risks requires system-level design rather than relying solely on the model.
Have a question?
Speak to an expert


