
Data warehouse as a service (DWaaS) is not a new way to delegate control of data to a third party. It changes the operating contract for the warehouse: who takes on operational risk, who carries the burden of scale, and who is accountable when the system becomes a bottleneck rather than a foundation.
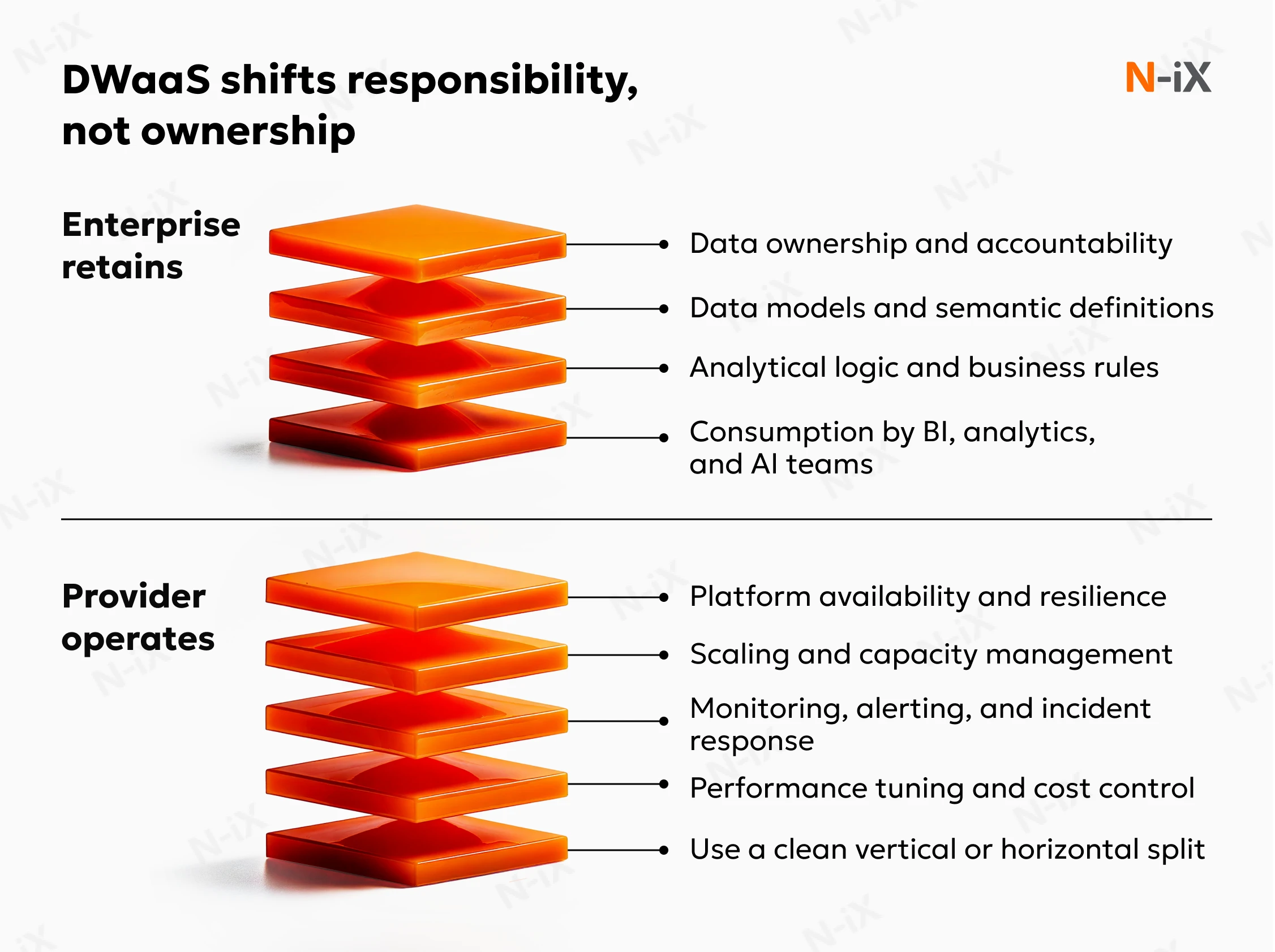
That distinction is often overlooked. Most enterprises already run their data warehouses in the cloud. Yet, many of the same dynamics remain: capacity planning still matters, operational incidents still require the attention of senior engineers, and every structural change carries risk. DWaaS changes the operating model rather than the technology stack. Ownership of data, models, and business logic remains within the organization, while day-to-day platform reliability and scaling are outsourced.
This is also why many organizations, before committing to a service-based model, are turning to data warehouse consulting to reassess how their current platforms are designed and whether the existing approach still aligns with business realities. Without further ado, let's outline what DWaaS is, how it works, and why enterprises are paying attention to this solution.
How does a data warehouse as a service work?
Data warehouse as a service should be evaluated as an operating model rather than a hosting decision. The defining change lies in how the warehouse is run, governed, and financed over time. Under DWaaS, the warehouse operates continuously and is explicitly responsible for availability, performance, and capacity.
In day-to-day operation, the warehouse is observed and adjusted continuously:
- Compute and storage scale in response to real workload behavior;
- Ingestion pipelines and transformations are monitored as part of normal operations, with controls that prevent isolated issues from cascading across the system;
- Performance targets are defined in advance and maintained through active workload management rather than periodic tuning;
- Access control, lineage, and audit trails are applied as part of standard workflows, not as separate compliance exercises.
For internal teams, the shift is beneficial. Infrastructure planning, platform patching, capacity management, and incident coordination no longer demand constant attention. Work is progressing toward data modeling, analytical enablement, and support for new use cases. Reliability, scalability, and performance are maintained through an operating structure designed to absorb growth and change predictably. This separation reduces operational exposure while preserving control over how data is defined and used.
When enterprise data warehouse as a service is executed correctly, the lifecycle is structured, repeatable, and deliberately uneventful. The enterprise provides data, defines priorities, and pays for the service. The provider assumes responsibility for designing, operating, and evolving the warehouse in line with agreed requirements. The value of DWaaS comes from how these steps are connected and governed over time, not from any single phase in isolation.
One example of this approach in practice is our cooperation with a Fortune 500 industrial supply company from the United States. N-IX designed and operates a cloud-based analytical platform that replaced a costly on-premises environment, while preserving data ownership and enabling elastic scale through Snowflake on AWS. It resulted in lower operational cost, unified access to more than 100 data sources, and a stable foundation for predictive analytics without locking the client into a single cloud provider.
To understand how this plays out, it helps to look at the lifecycle as a continuous operating loop.
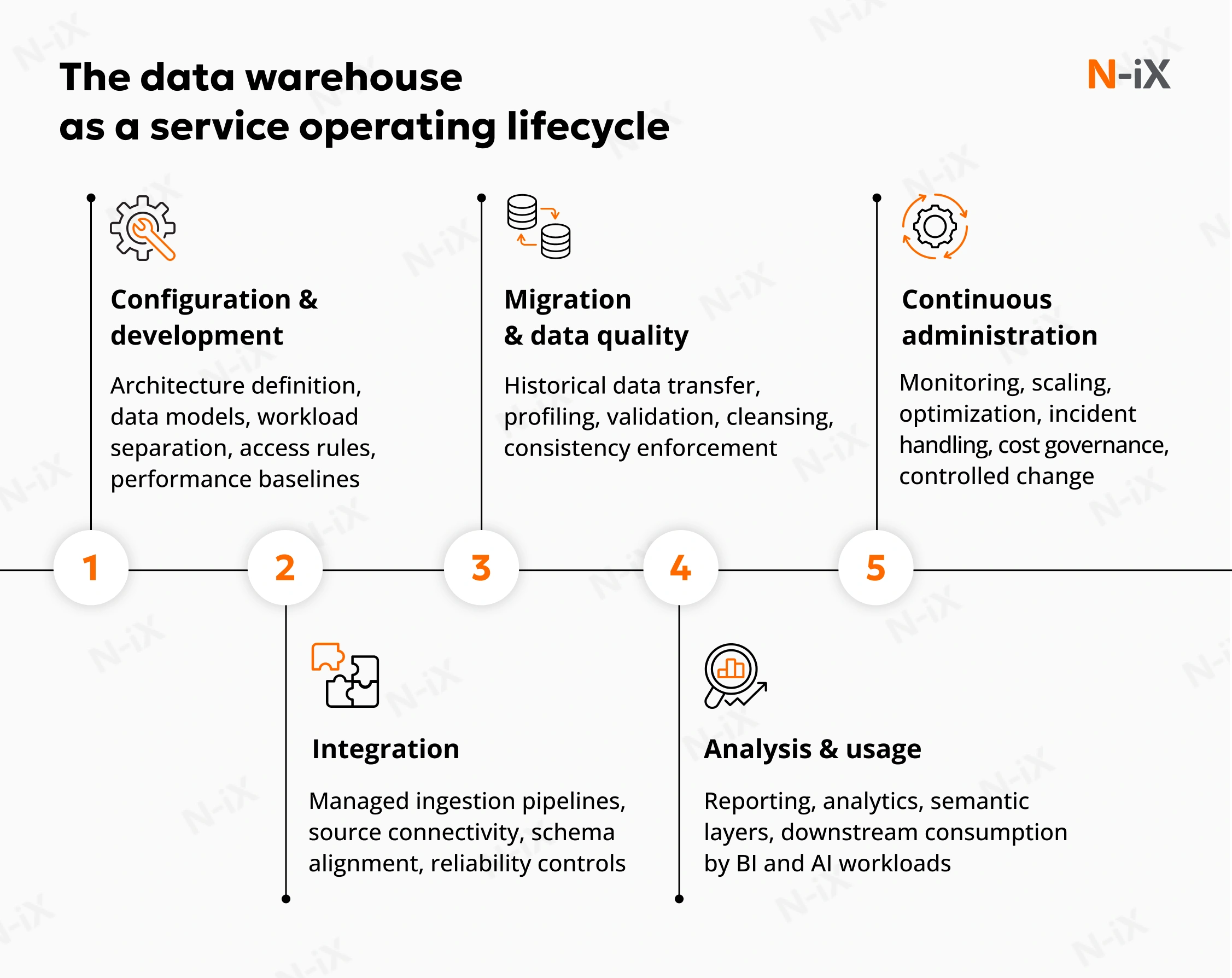
Configuration and development
The lifecycle starts with configuration, but not in the narrow sense of setting up infrastructure. The provider defines a warehouse design that aligns with business objectives, reporting needs, existing data sources, and data quality standards. Data warehouse strategy includes defining data models, transformation logic, workload separation, access rules, and performance expectations. The emphasis is on building a structure that can evolve without repeated redesign. Decisions made here determine how much friction the organization will face later when requirements change.
Data integration
Once the foundation is in place, data integration becomes a controlled, repeatable process. The provider connects the warehouse to operational systems, external sources, and existing analytical environments using managed ingestion pipelines. These pipelines pull data from databases, files, APIs, and data lakes according to defined schedules and reliability thresholds. The team continuously monitors integrations, detects failures early, and surfaces schema changes before they affect downstream consumers. Over time, this reduces the effort required to onboard new sources or adjust existing ones.
Read also: What you need to know about a data warehouse vs database difference
Data migration and cleansing
Data migration and cleansing are ongoing processes, not one-time events. Historical data is transferred using a defined migration strategy that prioritizes accuracy, traceability, and validation. During this phase, data is profiled, cleansed, and tested to ensure consistency and completeness. Importantly, this is not treated as a preparatory step that ends once migration is complete. Data quality checks remain active as new data arrives, which prevents gradual degradation of trust in analytical outputs.
Data analysis and usage
Once data is structured and validated, it becomes available through the warehouse's analytical layer. Users access it by leveraging reporting, BI, and analytical tools that connect directly to the managed platform. The warehouse supports analytical workloads, including aggregations, slicing, and complex queries, without requiring manual performance tuning. Since the underlying platform is operated as a service, users interact with a stable environment that behaves consistently as usage grows.
Continuous administration
The final stage never truly ends. Ongoing administration covers monitoring, security updates, backups, access management, and performance control. Scaling is handled dynamically based on observed demand rather than fixed capacity plans. Compute and storage expand or contract as data volumes, query complexity, and user concurrency change. This removes the need for periodic re-architecturing and reduces exposure to sudden cost or performance issues. The warehouse remains aligned with actual usage instead of theoretical peak scenarios.
Read also: Use cases of retail data warehouse
Data lake vs data warehouse—discover which solution is right for you!

Success!
How does DWaaS differ from a traditional data warehouse?
The distinction between a traditional data warehouse and DWaaS offering is not limited to technology choices or hosting location. It is a structural difference in how costs, responsibilities, and risks are distributed over time. Traditional data warehouses are owned and operated as internal systems. DWaaS is operated as a managed capability with explicit accountability assigned outside the organization.
|
Dimension |
Traditional data warehouse |
Data warehouse as a service |
|
Cost structure |
High upfront CapEx, fixed ongoing costs regardless of usage. |
Usage-based or subscription OpEx aligned with actual demand. |
|
Deployment speed |
Weeks or months due to procurement, setup, and tuning. |
Days or less using preconfigured, managed environments. |
|
Scalability |
Manual scaling via hardware purchase and reconfiguration. |
Elastic scaling handled automatically by the provider. |
|
Talent requirements |
Continuous in-house effort for operations, tuning, and maintenance. |
Internal teams focus on data and analytics, not platform upkeep. |
|
Governance responsibility |
Designed and enforced internally, often unevenly. |
Embedded and enforced through the service operating model. |
|
AI readiness |
Requires additional engineering to support variable and intensive workloads. |
Built to absorb fluctuating workloads and data growth by default. |
Under a traditional model, infrastructure ownership pulls operational responsibility inward. Capacity planning, performance issues, patch cycles, and scaling decisions accumulate as ongoing obligations. These obligations persist even when analytical demand fluctuates, and they often compete directly with higher-value work for engineering attention.
DWaaS changes this arrangement and shifts operational responsibility outward. Infrastructure, maintenance, and scaling are handled as a continuous service. The organization retains control over data, models, and access rules, but it no longer bears the full operational burden of keeping the platform stable and performant under changing conditions. This shift has specific consequences:
- Deployment timelines shorten because environments are not built from scratch;
- Elastic scaling without procurement cycles, removing delays caused by capacity planning and hardware approvals;
- Governance becomes more consistent because it is enforced through the operating model rather than manual oversight;
- Warehouse remains usable as demand grows or changes, instead of becoming progressively harder to adapt.

What are the key reasons to choose data warehouse as a service?
1. A predictable financial model and a lower total cost of ownership
DWaaS replaces capital-heavy investment and long depreciation cycles with an operating expense model that better reflects how analytics is actually consumed. Instead of buying capacity for peak demand and carrying underutilized resources, spend follows workload. The practical implication is fewer financial surprises.
A well-run DWaaS model also eliminates a set of ongoing cost centres that are easy to underestimate in traditional environments: patching, upgrades, operational tooling, platform administration, and the recurring rework required to keep aging pipelines stable. Those activities do not disappear; they become part of the service responsibility, which is what stabilises the total cost of ownership over time.
2. Faster time to value without compromising operational discipline
In many enterprises, the warehouse is "available" long before it is usable at scale. Data onboarding is slow, transformations are fragile, and reporting becomes dependent on a small set of people who understand how the system works.
DWaaS shortens time to value by using established delivery patterns for provisioning, source integration, and environment setup, while maintaining the controls that keep change safe. This difference is important, because speed comes from standardisation and automation. This allows analytics to expand incrementally, with fewer long implementation cycles and decreased delays caused by platform constraints.
3. Reduced operational risk and slower accumulation of technical debt
Traditional warehouses accumulate technical debt through bespoke configurations, one-off scripts, undocumented dependencies, and emergency fixes that become permanent. Over time, the system becomes harder to modify, and even simple changes carry risk. DWaaS reduces this by enforcing repeatable operational practices: standardised architectures, continuous monitoring, structured incident handling, and controlled change processes. The result is a warehouse that remains maintainable as it grows.
4. Higher data trust through consistent quality and governance controls
When ingestion and transformation logic are built inconsistently across teams, quality controls drift, definitions diverge, and reporting becomes contested. DWaaS raises the baseline by enforcing consistency in how data is integrated, validated, and modelled, and by embedding governance into daily workflows rather than relying on manual compliance. Access control, lineage, and auditability become part of how the platform runs, not additional work performed after problems appear. Over time, this reduces metric disputes and makes analytical outputs dependable enough for operational and financial decision-making.
5. Scalability that supports growth, analytics maturity, and AI workloads
DWaaS is designed to scale storage and compute as demand changes, without requiring repeated infrastructure planning cycles or re-architecture. This is also where DWaaS becomes relevant for advanced analytics and AI initiatives. AI workloads depend on governed, well-defined, accessible data and predictable performance under variable load. DWaaS provides that foundation by operating the platform in a way that can absorb shifting demand without destabilising the environment.
What does DWaaS enable in the modern data architecture?
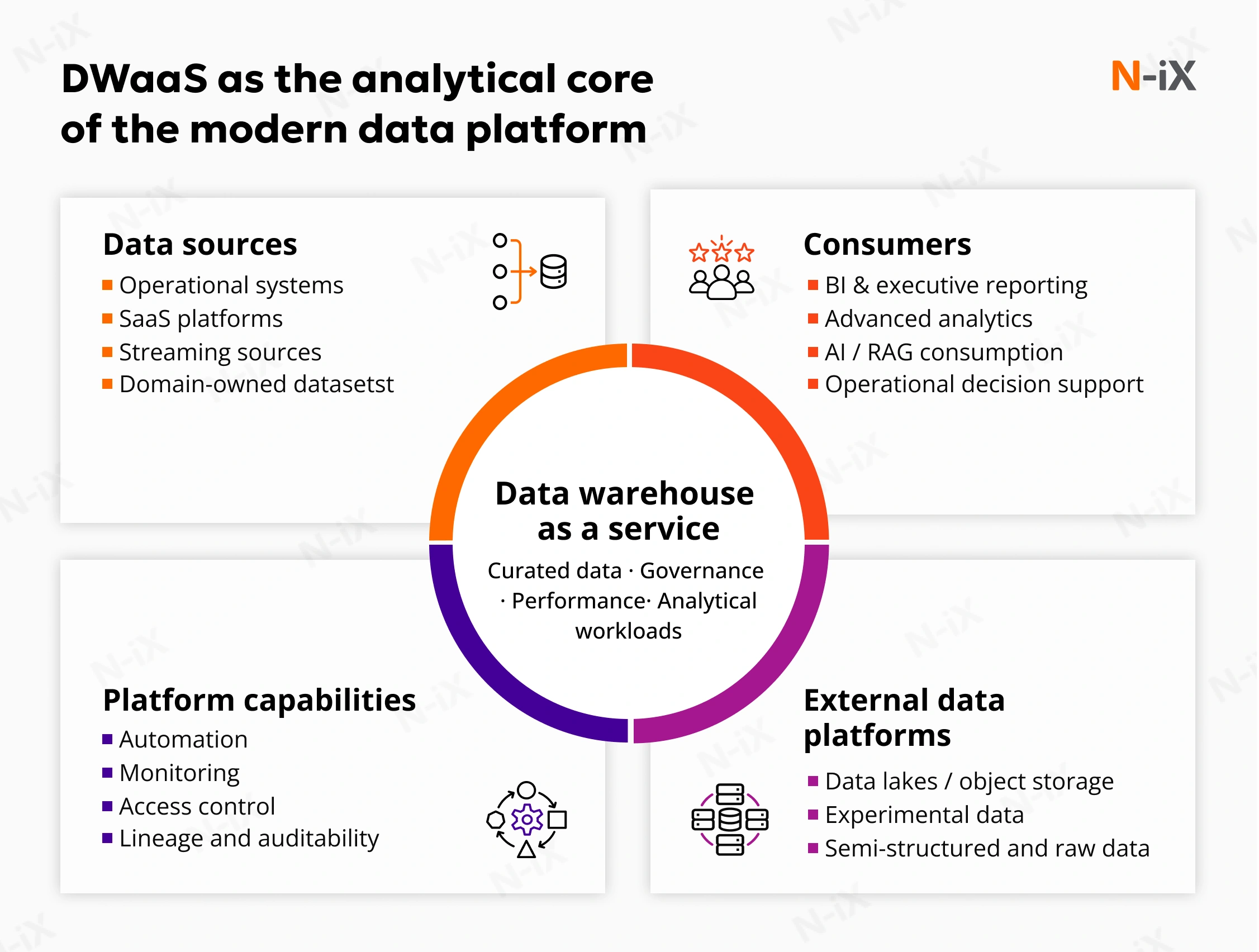
DWaaS as an analytical core within a broader data platform
Data warehouse platform as a service does not replace the surrounding data landscape. It operates as a stable analytical core within an architecture that also includes operational systems, object storage, and domain-level data assets. The value of DWaaS lies in its ability to remain dependable without becoming restrictive. It provides a governed environment for analytical workloads while allowing other parts of the platform to evolve independently.
This separation is deliberate. Raw, semi-structured, or exploratory data does not need to be forced into the warehouse prematurely. DWaaS focuses on curated, trusted datasets that support reporting, analytics, and downstream consumption. In doing so, it reduces pressure on the warehouse to serve conflicting purposes and avoids the architectural sprawl that often results when a single system is expected to handle everything.
A similar pattern emerged in our work with a global managed cloud services provider operating dozens of data centers worldwide. N-IX consolidated more than 70 operational data sources into a unified cloud data warehouse on Google Cloud and automated high-frequency ingestion and reporting workflows. By shifting the warehouse to a managed, scalable operating model, the client reduced infrastructure footprint, eliminated nearly 17,000 hours of manual reporting work per year. Moreover, they regained control over cost and data governance.
Integration with data lakes and federated access
A properly implemented DWaaS integrates natively with external data lakes and object storage. Building a data warehouse allows analytical queries to span warehouse-managed data and externally stored datasets through federated access patterns. Data can remain where it makes the most sense from a cost, performance, or compliance perspective, while still being accessible for analysis.
This capability becomes critical as data volumes grow and formats diversify. Instead of duplicating large datasets or introducing complex synchronization logic, DWaaS enables selective access and gradual promotion of data into governed models. The warehouse remains the place where data is refined and trusted, while the wider platform supports scale and flexibility.
Automation as a structural capability
Automation in DWaaS is not limited to infrastructure provisioning. It extends into ingestion, transformation, testing, and documentation through standardized, metadata-driven processes. Pipelines are built and maintained using consistent patterns rather than bespoke logic. Changes are validated and tracked as part of normal operation.
Data warehouse as a service providers can reduce dependency on individual expertise and lower the risk associated with change. As the number of data sources and consumers grows, automation ensures that consistency does not degrade and operational effort does not increase linearly. Over time, this becomes one of the main factors that keeps the warehouse maintainable.
Supporting advanced analytics and AI workloads
DWaaS workloads depend on data that is reliable, well-defined, and governed, rather than simply available. DWaaS provides that baseline by enforcing data quality, lineage, and access control as part of the operating model.
When retrieval-based approaches such as RAG are introduced, the warehouse becomes a source of trusted enterprise context. RAG development services don't attempt to replace experimental or model-specific data stores. Instead, it ensures that analytical and AI systems draw from consistent, auditable data definitions, reducing the risk of misleading outputs.
In practice, DWaaS delivers the most value in scenarios where ownership, responsibility, or trust is unclear:
- Executive reporting, where restoring confidence in numbers matters more than adding new dashboards;
- Finance and regulatory close, where consistency, lineage, and repeatability reduce cycle time and risk;
- Cross-domain analytics, where data spans teams without a single natural owner;
- AI initiatives, where data pipelines fail to keep pace with model development and deployment.
These are leverage points because they expose the limits of fragmented ownership and ad-hoc operations.
Can data warehouse as a service be a foundation for AI initiatives?
DWaaS can provide a strong foundation for AI when it functions as the system of record for curated, governed, reusable enterprise data. In other words, it supports AI not by being "AI-native," but by making data dependable enough to be used repeatedly across models, teams, and time. Most AI programs do not stall because the organization lacks model options. They stall because the data layer cannot produce consistent, auditable inputs fast enough, and because no one can confidently explain where training and retrieval data came from, how it was transformed, and whether it is permissible to use.
A properly implemented DWaaS helps solve that through three capabilities:
- First, it establishes a controlled environment for data standardization. The platform defines data structures, naming conventions, transformation logic, and refresh semantics upfront and applies them consistently across analytical and downstream workloads.
- Second, it enforces governance as an operating condition. Access control, lineage, retention rules, and auditability are implemented as part of how the platform runs, which reduces the likelihood that AI teams build on datasets that are poorly defined, inconsistently refreshed, or legally risky.
- Third, it supports predictable performance under changing demand. Training, evaluation, feature generation, batch scoring, and monitoring introduce variable workloads that tend to break fragile data platforms.
This is also where DWaaS becomes relevant for retrieval-heavy generative AI patterns. For RAG and similar approaches, the key requirement is not only data availability, but an enterprise context that is trusted and explainable.
DWaaS can serve as a controlled source of facts, metrics, reference data, and governed documents that can be retrieved and used as grounding context. This reduces the risk of outputs drifting from approved definitions, using stale data, or producing confident responses.
DWaaS is not a complete AI foundation on its own, and treating it as one creates avoidable disappointment. DWaaS does not replace feature engineering discipline, model governance, evaluation pipelines, or ML lifecycle controls. It will not automatically make unstructured data usable for training, and it cannot resolve unclear ownership of data definitions across domains. Many AI initiatives also require additional components adjacent to the warehouse, such as vector search layers, model-serving infrastructure, data-labeling workflows, and monitoring of model behaviour.
Taking the next step with DWaaS: How can N-iX support implementation
At scale, data warehouse as a service succeeds or fails not on architecture diagrams, but on execution over time. The difference is rarely the platform choice. It is whether the warehouse is designed, integrated, governed, and operated in a way that remains stable as data volumes grow, analytical demands evolve, and AI initiatives move from experimentation to production.
This is where N-IX typically engages. We help enterprises design, build, and run DWaaS as a long-term analytical capability, not a short-term platform rollout. Our work starts with clarifying how the data warehouse should function in your broader data architecture and what operational responsibilities should be externalized versus retained. From there, data warehouse as a service companies like N-iX take responsibility for the full DWaaS lifecycle, from configuration and development to continuous administration and optimization, with a focus on stability, predictability, and controlled change.
From a technology perspective, we are platform-agnostic by design. Our teams work across major cloud providers, including AWS, Microsoft Azure, and Google Cloud, and across a broad range of data warehouse technologies such as Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse, SQL Server, Oracle, Teradata, SAP IQ, ClickHouse, Apache Druid, Apache Pinot, Postgres, and DuckDB. This allows us to design DWaaS around requirements rather than forcing requirements to fit a preferred tool.

If you are evaluating DWaaS as a way to reduce operational burden, improve data trust, or prepare your data platform for advanced analytics and AI, the next step is a focused discussion about your current constraints and target outcomes. N-IX can help you assess fit, design the right DWaaS operating model, and run it reliably over time.

FAQ
Does DWaaS limit control over data or analytics?
No. In a well-structured DWaaS model, the organization maintains full control over data ownership, access policies, data models, and analytical use cases. The provider operates the platform and enforces agreed controls, but does not take ownership of business logic or decision-making.
What level of customization is realistic with DWaaS?
Customization is applied at the architecture, data model, governance, and workload level, not through one-off platform hacks. The constraint is intentional: standardized patterns improve reliability and change management without blocking business-specific analytics.
How predictable are costs with DWaaS over time?
DWaaS improves cost predictability by aligning spend with actual usage rather than fixed capacity, but predictability depends on how consumption is governed. Clear workload boundaries, cost monitoring, and usage policies are essential to prevent analytical growth from turning into uncontrolled spend.
Have a question?
Speak to an expert


