
Data is the proverbial new oil and the lifeblood of Industry 4.0. And like any other business asset, data should be protected, stored, and appropriately valued. Often, businesses have trouble understanding all the benefits that proper data management brings, thus losing their competitive advantage.
In this article, we are going to talk about the benefits and drawbacks of data warehouse and data lake, take a closer look at related concepts and pay attention to the specific use cases in different industries.
- Data warehouse: concept, related concepts, pros and cons
- Data lake: concept, related concepts, pros and cons
- Data lake vs data warehouse: recap
- Data lake vs data warehouse: examples of use by industry
Data warehouse
Data warehouse (DW) is a central repository of well-structured data gathered from diverse sources. In simple terms, the data has already been cleansed and categorized and is stored in complex tables. When DW is set up and loaded with both current and historical data, businesses can use it to create forecasting dashboards and trend reports, as well as gain valuable insight into the business processes.
A data warehouse has the following characteristics:
- integrated: data is always extracted and transformed in the same way, regardless of the original source;
- non-volatile: DW is never updated in real-time. It’s updated via scheduled and timed uploads of data, protecting it from the influence of momentary changes.
- scalable: DW is easily scalable to meet the increasing demand for storage space.

Other important concepts
- Relational database vs data warehouse. Databases are the real-time repositories of information. Data warehouses pull information from various sources (including databases) for further filtering, extraction, storage, and analysis of huge amounts of structured data.
- Data warehouse vs data mart. A data mart is a part of the data warehouse created to serve the needs of a specific team or business department. It is a dedicated space within your warehouse that is used to store only data related to a particular category, type of information, and/or business needs.
- Operational Data Store (ODS) is often used as an interim area for a data warehouse. An ODS performs simple queries or operations on small sets of data in real-time, while a data warehouse is designed to perform complex queries on large amounts of data. An ODS deals with current operational data and continuously overwrites it, while a DW aggregates data across historical views.
For an easier understanding, take a look at the chart below.

The pros and cons of data warehouses
The use of a data warehouse offers many advantages, such as:
- Accelerated business intelligence. A DW provides an analysis of relational data coming from both online transaction processing (OLTP) systems and business apps (e.g., ERP, CRM, and HRM systems).
- Enhanced data quality and consistency. Due to the extract, transform, load (ETL) procedure, a data warehouse stores data from numerous source systems in a common format. After each transaction, the integrity of the data is verified.
- Historical intelligence. DW compared new data to previously entered information, allowing end-users to see historical changes and quickly generate reports within the required amount of time.
- Improved decision-making process. Data warehousing provides better insights to decision-makers by maintaining a cohesive database of current and historical data.
- Integration with uniform data sources, making it a fit for small- to medium-sized businesses or parts of a larger structure for the enterprises.
Data warehouses have such disadvantages:
- The intricate structure of access levels to the results and reports;
- Higher chances of distorted BI analysis results, due to the premature or incorrect data cleansing (unclear requirements, different data sets, etc.);
- Complicated process of changes implementation.

As you can see, a data warehouse is an excellent choice for companies who know exactly what type of data they are working with, what results they expect, and value the benefits of this repository.
Data lake
Let’s take a look at the data lake concept. Unlike traditional databases, a data lake stores data in its raw format. It is usually a single depot for all the data, including raw copies of both source and transformed data. A data lake can hold structured data from relational databases (e.g. tables from a report), semi-structured data (CSV, JSON, logs, etc.), unstructured data (like emails, documents, and PDFs), and binary data (images, audio, and video).

While a data warehouse stores data in files or folders, a data lake uses a flat architecture to store data. Each element in a data is labelled with a set of extended metadata tags and has a unique identifier. When needed, the data lake can be queried for relevant data, and a smaller set of data can then be analyzed to help answer a specific business question.
A data lake has the following characteristics:
- a data lake accepts data from all sources. It allows you to receive and store any data in order to analyze or address it later;
- data is collected from multiple sources in real-time and loaded into the data lake in its original format;
- it relies on low-cost storage options to store the raw data;
- data can be updated in real-time or in batches.
Before we move any further, let’s clarify some confusing aspects or answer the questions you might have.
Getting clear with other notions
- Data ocean vs data lake. A data lake is often used for the data specific to a certain part of the business. A data ocean, on the other hand, comprises unprocessed data from the entire scope of the business.
- Data reservoir vs data lake. Some businesses use a data reservoir to divide an unrefined data lake and a data reservoir that’s been partly filtered, secured, and made ready for analysis.
- Data lake vs data swamp: ‘swamps’ are data lakes containing low-quality, unrefined data. You can also hear about ‘data graveyards’, which are data lakes containing data that’s collected in large quantities but never used.
- Data lake vs relational database. A database, by design, is highly structured. This makes databases less flexible to the business needs than data lakes.
Data lake pros and cons
In general, data lakes are suitable for analyzing data from diverse sources, especially when the initial data cleansing can be problematic.
Here are some major benefits of using a data lake:
- Unlimited scalability. Data lake allows you to scale horizontally to fulfill any needs at a reasonable cost;
- Data from diverse sources is stored in its raw format.
- Flexibility. A DL allows you to create large heterogeneous, multiregional, and microservices environments;
- Excellent integration with Internet of Things (IoT), since data such as IoT device logs and telemetry can be collected and analyzed easily;
- Integration with machine learning, given the schemaless structure and ability to store large amounts of data.
- Support for advanced algorithms. DL allows you to apply complex queries and deep learning algorithms to recognize objects or patterns of interest.
However, data lakes are not always the perfect solution for every case. Among the risks of data lake usage are:
- Increased storage and computes costs;
- Lack of insights from the previous findings, as there is no way to track what has been extracted before;
- Data integrity loss. Even though you can store several versions of the same document, a lack of transaction control threatens the integrity of data stored.

Data lake vs data warehouse: recap
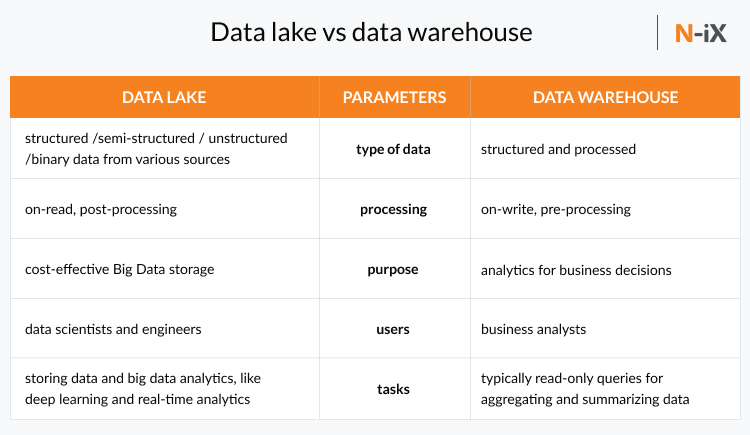
While both systems are used to store and process data, they use entirely different approaches to the process. Let’s take one more look at differences between a data lake and a data warehouse:
- Data lake stores all labelled data regardless of the format, whereas data warehouse stores data in quantitative metrics with their attributes.
- A data lake is a storage repository that stores huge structured, semi-structured, and unstructured data while data warehouse demands well-structured and refined information, allowing its users to achieve the strategic use of data.
- Data lake uses the ELT (Extract Load Transform) procedure - the data is processed after it is loaded into a data lake. The data warehouse uses the ETL (Extract Transform Load) procedure - the data is transformed and then loaded into the data storage.

- A data lake is ideal for those who want an in-depth analysis of broad-spectrum data that is gathered over a longer period of time, while a data warehouse is perfect for operational processes and day-to-day activities.
Data lake vs data warehouse: examples of use by industry
Let’s take a look at how data lakes and data warehouses are used by businesses in different industries.
Data lake use cases
- Healthcare. While data lakes are a better fit for handling large amounts of unstructured data like physicians' notes, the role of a data warehouse in healthcare remains critical for analyzing structured data from billing and patient administration systems.
- Education. Collecting the data about student grades, attendance, etc., can not only help students improve their track record, but can also help predict potential issues before they occur.
- Transportation. Data lakes are a great source of insights due to their ability to make predictions. In the transportation industry, the predictions can help companies reduce their costs, improve predictive maintenance.
Data warehouse use cases
- Banking and finance. A data warehouse is often the best storage model for these sectors, as they allow structured access by the entire company rather than a single data scientist.
- Public sector. It helps agencies to maintain and analyze tax records, health policies, etc., building both individual profiles and group records.
- Hospitality industry. This industry uses data warehouses to design advertising and promotion campaigns targeting clients based on their feedback and travel patterns. They also use DW to handle day-to-day operations.
Data lake vs data warehouse: Which is right for you?
It is a common assertion that data warehouses are a good fit for small- to medium-sized businesses, while data lake use cases are more common for larger enterprises. However, everything depends on the type of data you are dealing with and its sources. That said, there are few questions to help you make the right decision:
- Do you have a set-up structure?
If you use an SQL database, CRM, ERP, and/or HRM systems, a data warehouse will fit well into your business environment. If you need a from-scratch solution, proceed to the next question.
- How unified is your data?
For companies that are dealing with well-structured information or the one that can be structured, a data warehouse will work perfectly. If your data comes from diverse data sources (e.g., IoT logs and telemetry, binary data, analytics), data lakes are probably a better choice as the ETL (extract, transform, and load) will result in significant data loss if you opt for a data warehouse.
- Is data retention an issue for your business?
Storing huge volumes of data in a traditional database can be expensive. It can lead to various issues with retention, like limiting the period of historical data or eliminating specific fields of the data, in order to control costs.
- Are your business needs predictable?
If you can deal with reports that are generated by running a predetermined set of queries against the table(s) that is regularly updated, a DW will probably suffice. However, if you are working with more experimental cases, such as ML, IoT, or predictive analytics – it’s better to store raw data in its initial format.
Often, organizations need both a data lake and a data warehouse. Data warehouses are often used for daily and operational business decisions and processes, whereas lakes are used to harness big amounts of data and benefit from the raw data. Data lakes are often used as a part of machine learning or advanced analytics solutions. However, many companies are now using both storage options, especially when a data warehouse is built upon a data lake, and it uses the data from a DL that has been cleansed and structured.
Need help building a data warehouse or data lake? Take advantage of N-iX expertise
N-iX is an Eastern European IT service provider that has got a wide range of tech expertise including big data analytics, data science, AI & ML, cloud solutions, IoT, DevOps, and much more. N-iX software development teams help to build solutions for businesses in fintech, retail, telecom, media, automotive, healthcare, and other industries. We help many clients harness their warehouses and data lakes, tackle their Big Data, improve business intelligence, and gain the maximum value from all of it. Some of our notable clients are
- Gogo, a leading provider of in-flight connectivity and entertainment;
- A US industrial supply leader, Fortune 500 company (under NDA);
- A financial and banking services company (under NDA);
- Lebara, one of Europe's fastest-growing mobile companies with five million active customers, 1,400 employees worldwide, and operations in nine countries.
For example, as a part of cooperation with Gogo, the N-iX team has built the data warehouse system for storing and processing significant amounts of data. It allows the company to receive timely reports and provides the ground for operational processes. N-iX developers have also created an AWS-based data platform and built a data lake for collecting data from more than 20 different sources in one place. The DL also has a separate layer that provides information for the company's data warehouse, improving the reporting process (while some business applications can connect directly to the data lake to extract information). Data lake also provides historical data for Data Science and ML applications.
Another success story for N-iX is a partnership with Lebara, the company that needed to optimize their telecom analytics and BI development. In many situations, generating virtually real-time reports is important for making effective business decisions. For this purpose, Lebara and N-iX engineering teams have been working on building a data lake that allows storing both structured and unstructured data and real-time data streaming.
If you have any questions about data lake or data warehouse, or its potential value for your business, contact our experts.
Have a question?
Speak to an expert


