
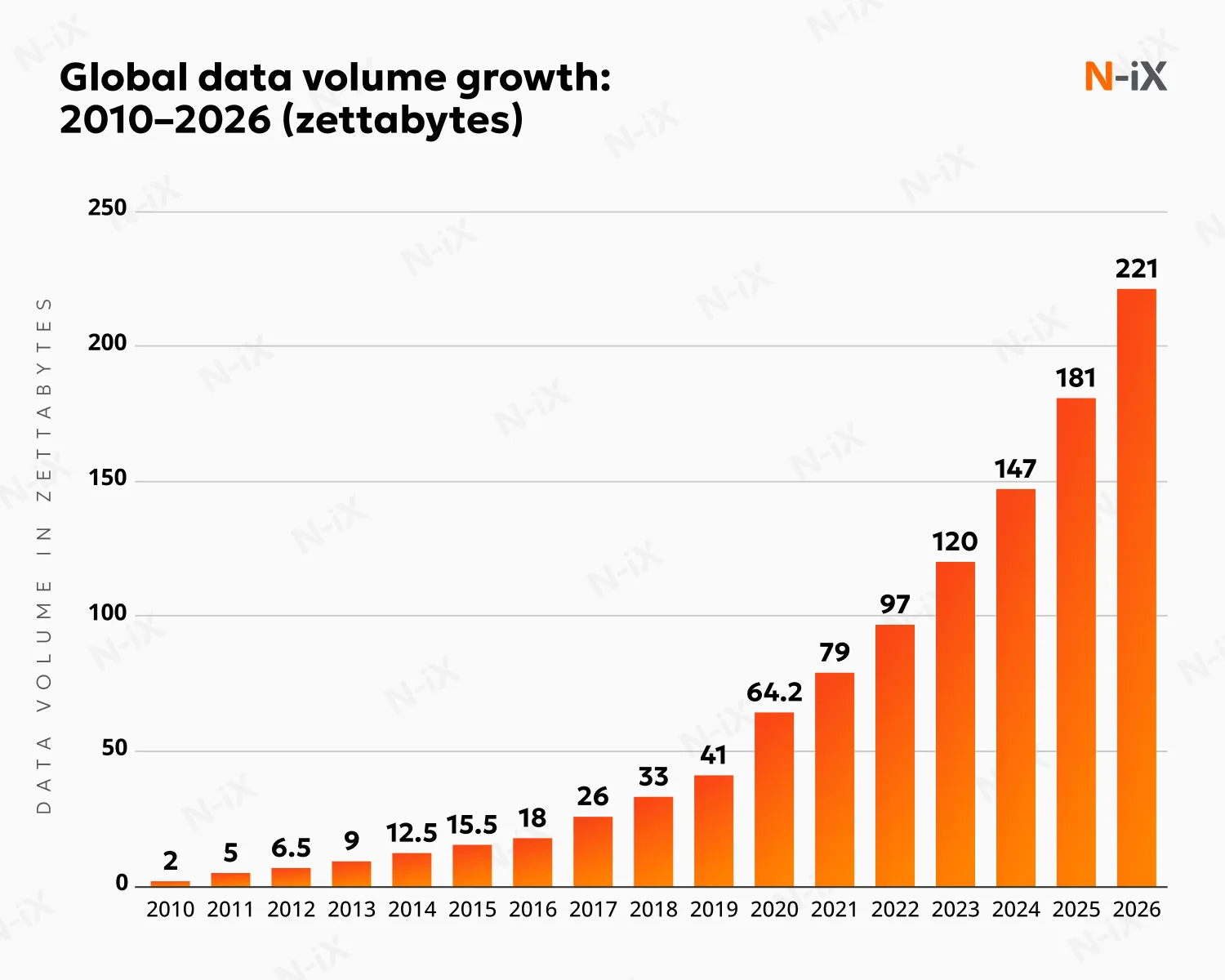
Data generation, capture, copying, and consumption will reach over 221 zettabytes in 2026, IDC predicts. While raw data holds potential, it needs transformation to bring insights. Data engineering services bridge the gap, crafting data engineering systems that collect, store, and deliver meaningful information.
"Data engineering is the make-or-break factor for AI success. The companies winning with AI aren't the ones with the biggest budgets. They're the ones who got their data organized first. Without good data engineering, AI is just expensive software that disappoints."

If you want to stay competitive in a data-driven economy, now is the time to explore how 2026's data engineering trends can transform your business operations.
7 data engineering trends of 2026
AI assistants are now automating database queries, while new data mesh systems let different teams manage their own data domains. These technologies are transforming how companies handle their information, making operations more efficient while keeping everything compliant with regulations. Here are six key trends shaping how enterprises work with data in 2026
1. AI copilots transition from assisted analytics to autonomous data operations
AI copilots and autonomous workflows will continue to transform data engineering in 2026. By democratizing analytics access across organizational departments, these LLM-powered platforms eliminate complex dashboard configurations. This enables natural language interactions that generate sophisticated database operations, visualizations, and actionable recommendations.
Advanced copilots autonomously monitor data streams, detect anomalies, and initiate performance optimizations. They, meanwhile, maintain comprehensive lineage tracking for regulatory compliance.
Gartner predicts that by 2027, AI assistants and AI-enhanced workflows will reduce manual intervention by 60% and enable self-service data management. Industry projections indicate that over 80% of organizations will adopt generative-AI APIs and copilot solutions in 2026. This represents explosive growth from under 5% adoption three years prior. Such acceleration stems from technological advancement and regulatory pressures, including the EU AI Act requirements for transparency and explainability.
The transformation enables routine reporting and complex analytics completion in minutes rather than weeks, freeing skilled engineers for strategic design and innovation. The intelligent agents understand contextual queries, trace data schemas, generate optimal queries, and create tailored interactive visualizations.
According to Gartner's prediction, by 2028, GenAI-powered narrative and visualization will replace 60% of existing dashboards. The shift from passive assistance to proactive monitoring and remediation marks a critical evolution in data operations.
Explore the AI landscape of 2026—get the guide with top trends!

Success!
Autonomous AI systems will be embedded within approximately one-third of business applications by 2027. Looking ahead to 2028, AI marketplaces will facilitate roughly four-fifths of all enterprise artificial intelligence acquisitions, resulting in cost reductions of at least 20% for data analytics and AI initiatives.

2. LLMs integrate as a foundational intelligence layer in the data engineering infrastructure
Large language models are becoming the foundational intelligence layer that powers entire data engineering infrastructures, moving far beyond user-facing applications to automate core technical operations.
In 2026, specialized LLMs will autonomously optimize database schemas, generate and maintain ETL pipelines, and perform predictive resource scaling across cloud environments. Gartner forecasts that by 2028, the fragmented data management markets will converge into a "single market" around data ecosystems enabled by data fabric and GenAI, reducing technology complexity and integration costs.
The emergence of domain-specific LLMs represents a critical evolution from generic models to specialized engines trained on industry-specific data patterns, compliance requirements, and technical vocabularies. Healthcare data platforms leverage models trained on HIPAA regulations and medical terminology, while financial systems deploy LLMs optimized for risk calculations and regulatory reporting. These specialized models deliver superior accuracy in code generation, anomaly detection, and automated documentation.
Gartner's research indicates that by 2028, AI-powered tools will automatically replatform or rebuild 50% of legacy applications, demonstrating the infrastructure-transforming power of LLMs. Cost optimization has become a primary LLM application, with models continuously analyzing infrastructure usage, identifying redundant processes, and automatically implementing efficiency improvements. Additionally, by 2027, AI will automate the optimization of 40% of D&A spending in cloud-based data ecosystems.
This comprehensive integration supports Gartner's projection that by 2028, 80% of GenAI business applications will be developed on organizations' existing data management platforms, reducing implementation complexity and time to delivery by 50%. Rather than isolated tools, LLMs are embedded throughout the entire data stack architecture, providing autonomous monitoring, code generation, and system optimization that enable engineering teams to focus on innovation and strategic platform development.
Keep reading: LLMOps vs MLOps: Differences, use cases, and success stories
3. Data mesh replaces centralized data systems with domain-specific data products
In 2026, large enterprises will largely move beyond the binary choice between centralized data lakes and warehouses, shifting to distributed, domain-oriented data mesh architectures that foster scalability, innovation, and agility. At the heart of this change is a simple idea: data should be treated like a product. Instead of having one central IT team manage everything, different business teams should own and be responsible for their data areas.
This approach empowers cross-functional teams to independently manage, govern, and evolve their data assets, tailoring solutions to their unique needs and driving faster, more targeted decision-making. The rise of composable platforms underpinned by federated, API-first design supports seamless integration across legacy systems, cloud services, and external partners, breaking down longstanding silos and ensuring real-time data accessibility.
Universal governance standards and robust data contracts provide framework-level structure: central teams oversee compliance, policy enforcement, and lineage, while domain experts maintain control, quality, and direct accountability for their data products. This balanced approach not only strengthens regulatory compliance amidst strict privacy rules but also fosters trust and reliability, as business units become stewards of the accuracy and usability of their information. Implementation strategies focus on creating quick wins through pilot data products, celebrating early successes, and scaling gradually via cross-domain steering units and centers of excellence. Educational initiatives and open communication are essential to address organizational resistance and build support for the paradigm shift, ensuring that technical and business stakeholders align with the mesh's value proposition.
Adopting data mesh and composable platforms unleashes exponential growth in new analytics use cases and applications. Teams iterate quickly, legacy bottlenecks fade, and enterprises achieve the flexibility to adapt their infrastructure and processes to ever-changing business demands. In this new era, data mesh is not a trend but the standard for resilient, transparent, and democratized enterprise data, delivering actionable intelligence and competitive advantage across the entire organization.
4. Synthetic data becomes a core tool in data engineering
Synthetic data will establish its role as a core enabler in data engineering strategies, particularly within highly regulated domains like healthcare and finance, where protecting personal information is critical and compliance with privacy laws such as GDPR, CCPA, and the EU AI Act is mandatory. The synthetic data generation market is projected to grow to $2.3B by 2030, exhibiting a CAGR of 31% during the forecast period.
Gartner projects that by 2028, 80% of data used by AIs will be synthetic, up from 20% in 2024, reflecting rapid enterprise adoption driven by data scarcity, privacy concerns, and the limitations of traditional anonymization techniques. This transformation is so significant that Gartner estimates by 2030, artificially generated datasets will become more valuable than authentic data for corporate decision-making processes.
In healthcare, the European Health Data Space (EHDS) entered into force in March 2025 and will enable secure cross-border health data sharing for research by 2029, creating new opportunities for privacy-preserving analytics through synthetic datasets that mimic real patient information relationships without exposing sensitive records. Financial organizations similarly leverage synthetic data to develop anti-fraud models and risk management strategies while maintaining compliance with strict privacy regulations like GDPR and PCI DSS.
Beyond regulatory compliance, synthetic data offers practical advantages: it's cost-effective and allows companies to create AI datasets customized for their specific operational needs, whether modeling particular sensors, lighting conditions, or equipment specifications. This capability addresses the growing challenge of data scarcity in specialized domains where real-world data collection is expensive, time-consuming, or ethically problematic.
The adoption of synthetic data reflects broader data engineering trends toward privacy-first methodologies that enable innovation while maintaining strict regulatory adherence. Organizations can use synthetic data to power analytics testing environments, compliance audits, and team collaboration. This lets business units from R&D to operations experiment safely and responsibly, making synthetic data essential for scaling AI projects without compromising privacy or breaking regulations.
5. Data observability merges governance, performance, and security into one platform
Data observability is evolving from operational monitoring into an indispensable enterprise capability. Gartner forecasts that 50% of organizations with distributed data architectures will adopt sophisticated observability platforms in 2026, up from less than 20% in 2024.
This transformation builds on OpenTelemetry standardization, which provides vendor-neutral telemetry collection and enables comprehensive platforms without lock-in. Modern solutions are advancing beyond traditional event-based monitoring toward AI-powered systems that deliver autonomous monitoring, predictive anomaly detection, and intelligent remediation across multi-cloud environments spanning an average of 12 platforms per organization.
In 2026, unified observability platforms will automatically monitor data content, flow, pipeline integrity, compute resources, user behavior, and cost allocation. These systems will proactively detect problems, identify silent failures, and catch inconsistent records before issues cascade. Integrating metrics, logs, traces, profiling data, and LLM monitoring capabilities will create unprecedented visibility into traditional and AI-driven operations.
Advanced cost optimization strategies, including intelligent data sampling and retention policies, will reduce storage expenses by 60-80%. Comprehensive data lineage tracking, automated governance enforcement, and real-time compliance validation for regulations like GDPR will create critical compliance layers with automated audit trails and centralized policy enforcement.
Cloud-native, usage-based pricing models will democratize enterprise-grade observability, making sophisticated monitoring accessible to organizations of all sizes while transforming reactive data management into proactive prevention strategies.
In 2026, robust observability will extend across the entire data lifecycle, providing standardized, organization-wide measures of quality, reliability, and usability. This comprehensive integration will be essential for performance optimization, regulatory compliance, operational resilience, and innovation enablement, solidifying data observability's position at the core of the modern data stack as a strategic business capability.
6. DataOps: From automation to autonomous intelligence
DataOps will evolve from streamlining data delivery to becoming the orchestral conductor of fully autonomous, AI-agent-driven data ecosystems across industries. Gartner predicts that data engineering teams guided by DataOps practices and tools will achieve 10x productivity gains compared to traditional approaches, as continuous feedback loops and agentic AI automation deliver end-to-end orchestration that seamlessly integrates data engineering, machine learning operations, and business intelligence. This transformation reflects DataOps' maturation beyond its DevOps origins into a comprehensive methodology supporting the entire data lifecycle, from ingestion through insight delivery.
Supporting this evolution, Gartner forecasts that by 2028, 70% of Project Management Office (PMO) leaders will use AI-enabled Project Portfolio Management (PPM) tools to predict project delays and overruns with great accuracy, enabling proactive mitigation strategies. The integration of DataOps and MLOps creates unified frameworks that enhance collaboration, reduce deployment friction, and automate time-consuming procedures across distributed, multi-cloud architectures.
Current data engineering trends emphasize the convergence of operational methodologies with artificial intelligence to create self-managing data infrastructures that require minimal human oversight. Central to 2026's change is the emergence of hybrid data professionals—MLOps engineers versed in both data architecture and AI model deployment, prompt engineers optimizing generative AI workflows, and domain-specific knowledge engineers who bridge technical implementation with business context and data semantics.
Cloud-native infrastructures now standardize real-time data streaming and microservices orchestration. At the same time, autonomous data quality monitoring powered by advanced observability detects anomalies, validates metrics, and self-heals pipeline failures without human intervention. DataGovOps (governance-as-code) has gained significant traction, automating compliance procedures and creating audit trails through integrated background processes. DataOps has become indispensable for maintaining auditability, security, and regulatory compliance in regulated sectors like finance and healthcare while supporting rapid innovation cycles.
7. AI agents emerge as the dominant consumers and orchestrators of data ecosystems
A new paradigm is emerging where AI agents, not human users, become the primary consumers and orchestrators of enterprise data systems. Gartner predicts that by 2028, 80% of organizations will report that AI agents consume the majority of their APIs, rather than developers. This shift affects how data engineering systems must be designed, optimized, and scaled.
By 2028, at least one-third of business decisions will be made semiautonomously or autonomously with the help of AI agents, up from less than 1% today, according to Gartner research. This transformation requires data engineering infrastructures to support machine-to-machine interactions at unprecedented scales, with APIs designed for agent consumption patterns rather than human workflows.
These AI agents operate across the entire data lifecycle, from automated data discovery and ingestion to real-time analytics and decision execution. They negotiate data access, perform quality assessments, optimize query performance, and coordinate complex multi-system transactions without human intervention. Such agent-driven automation is expanding beyond data engineering into other business areas. For example, Gartner forecasts that by 2028, 15% of day-to-day supply chain decisions will be made autonomously by AI agents, demonstrating how this technology is transforming decision-making across all business domains.
Related: AI agent use cases: Key applications
The implications for data engineering are extensive: systems must provide comprehensive APIs, maintain consistent data contracts, and support autonomous monitoring and healing. Traditional user interface design becomes secondary to API performance, data schema stability, and agent-friendly error handling. This trend aligns with Gartner's prediction that by 2027, there will be three times more open positions for AI engineers than data scientists, as pretrained AI solution development displaces custom-made machine learning training.

Wrap-up: The convergent future of enterprise data
The convergence of data observability, DataOps, AI copilots, foundational LLMs, data mesh architecture, and autonomous workflows represents interconnected components of unified intelligent data ecosystems by 2026. These technologies eliminate traditional bottlenecks between data collection, processing, and consumption. Organizations implementing integrated approaches gain competitive advantages through reduced time-to-insight, democratized analytics access, and rapid data product deployment across business domains.
These technologies collectively enable enterprises to transition from reactive data management to proactive, AI-driven operations that anticipate and resolve issues before they impact business performance. In 2026, data engineering trends will drive the convergence of data engineering, AI operations, and business analytics into intelligent systems that autonomously manage complete data lifecycles while enabling strategic innovation. Choosing the right data engineering partner will be crucial for innovation, growth, and informed decisions.
Have a question?
Speak to an expert


