
Most organizations that explored generative AI over the past year did so through text-based models. They experimented with summarization, drafting, data extraction, or internal chat assistants. These systems were helpful until some time, but they soon revealed a standard limitation: real work inside the enterprise isn't text-only.
A customer support case may include a screenshot of an error, a log extract, and a short recorded voice note from the field. A production line quality issue may depend on a temperature trend from a sensor and a maintenance report. Engineering teams make decisions based on version-control activity, test results, and specifications stored in PDFs. Leadership reviews dashboards, commentary, and market research, which combine numbers, visuals, structured data, and narrative explanations.
In every one of these workflows, the information needed to make a correct decision spans multiple formats. And today, people fill the gap in interpretation. A support agent visually checks the screenshot. A technician describes what they saw over the phone. A senior engineer recognizes a familiar failure pattern in a diagram. Human reasoning provides the connective tissue.
This is where text-only generative AI reaches its limit. It can respond to instructions, but it cannot truly interpret the situation. Multimodal generative AI is the next step: models that can understand and relate text, images, audio, video, and structured data in context. Companies exploring this direction often start with generative AI consulting to clarify use cases, define governance frameworks, and lay the right foundation. From here, we will break down the core mechanics of multimodal models, examine real enterprise use cases, clarify the risks to anticipate, and outline how organizations can move from experimentation to a stable, production-grade deployment.
What is multimodal generative AI?
Multimodal generative AI refers to models that can understand, reason across, and generate content in multiple data formats simultaneously, such as text, images, audio, video, and structured data. The key distinction is that a multimodal generative AI model does not treat each format as a separate input channel; it forms a shared internal representation that allows it to interpret how different types of information relate to one another.
There are two generative AI multimodal capabilities:
- Input side: The system can process multiple data types simultaneously and recognize patterns that emerge only when formats are examined together. For example, correlating spoken feedback with dashboard metrics or linking equipment noise recordings to known failure signatures.
- Output side: The system can generate new content in multiple formats, based on integrated understanding. Producing text explanations grounded in visuals or data, generating updated documentation, and training content paired with relevant imagery are all multimodal generative AI examples.
Multimodality differs from text-only LLMs, which operate primarily on written or transcribed language. Text-based models can summarize documents, answer questions, and generate written content, but they are constrained by the assumption that meaning resides solely in text. In reality, much of the information in operational environments is visual, spatial, auditory, or numerical. Multimodality is built to address this broader reality.
Discover differences between AI and generative AI—get the expert guide!

Success!
How multimodal differs from unimodal or text-only models?
Text-only models assume that all relevant context has already been translated into words. Multimodal models remove that requirement. They can interpret a graph directly without needing an analyst to describe its trends. They can analyze a diagram without converting it to prose. They can use audio tone and pacing as input rather than ignoring them.
|
Feature |
Text-only LLMs |
Multimodal generative AI |
|
Input types |
Text only |
Text, images, audio, video, structured data, sensor streams |
|
Core strength |
Language reasoning and generation |
Cross-modal reasoning and integrated understanding |
|
Output formats |
Text-based responses |
Text, images, audio, video, and multi-format outputs |
|
Context awareness |
Limited to written descriptions |
Grounded in visual, auditory, and numerical context |
How does multimodal generative AI work?
To handle, relate to, and generate content across multiple data forms, multimodal AI systems follow a structured architecture composed of three core stages: input processing, representation fusion, and content generation.
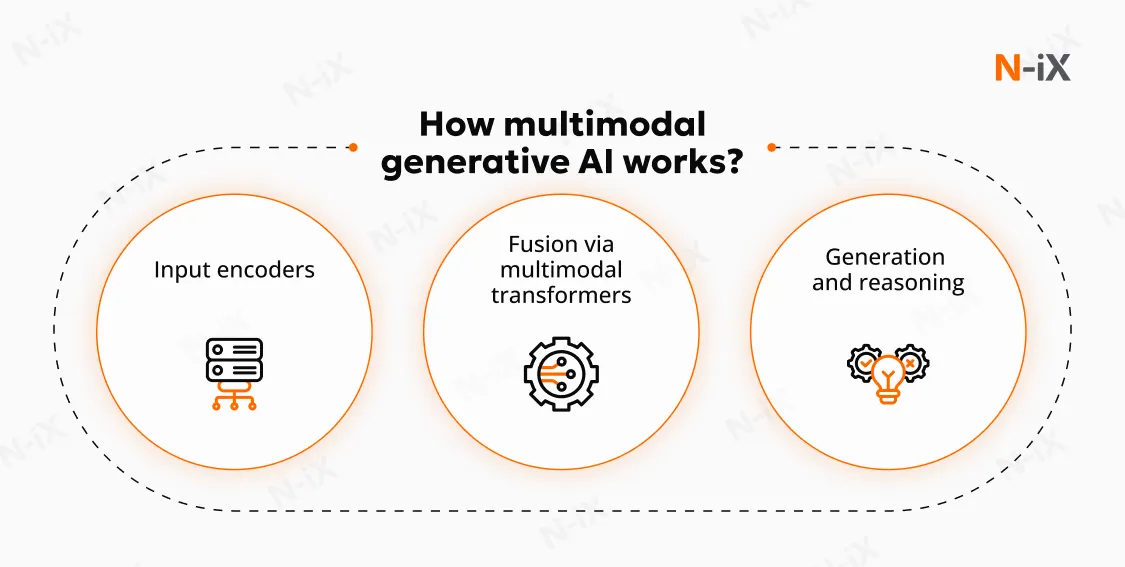
1. Input processing
The process begins when the multimodal generative AI systems receive inputs, such as text, images, audio recordings, video clips, documents, charts, or sensor readings. Each of these data types has distinct characteristics: text is discrete and symbolic; images are spatial and continuous; audio is temporal; and structured data often explicitly encodes relationships.
To manage this heterogeneity, the model uses modality-specific feature encoders, neural networks specialized for each form of data:
- Text is processed using language models, which convert words and sentences into semantic token embeddings.
- Images and video are processed by computer vision encoders, which learn patterns in pixel values and translate them into visual feature embeddings.
- Audio is processed by speech and acoustic models, which capture tone, rhythm, and spectral features.
Each modality is converted into a compressed numerical form that captures the most meaningful structure from the original data. The output of this step is a set of embeddings, dense numerical vectors that allow the system to compare and relate these forms of information in a common computational space. At this point, the model standardizes meaning into a format it can operate on.
2. Cross-modal fusion
Once individual representations are created, the system must determine how they relate to each other. Here, multimodal AI begins to differ sharply from unimodal LLMs. Instead of treating each data channel independently, the model aligns and integrates them within a shared semantic space.
This step, often referred to as cross-modal fusion, relies heavily on attention-based transformer architectures. It helps to determine how information in one modality influences interpretation in another. Fusion typically relies on attention-based integration layers that enable the model to identify the most relevant relationships between modalities. Depending on the architecture, this may occur at different depths:
- Early fusion integrates modalities at the feature extraction stage.
- Intermediate fusion aligns embeddings during representation learning.
- Late fusion aggregates outputs from separate processing streams.
- Cross-modal transformer fusion performs dynamic alignment at inference time.
These networks evaluate the relationships between tokens from each modality, identifying contextual dependencies such as:
- Equivalence ("this phrase refers to this part of the image")
- Dependency ("this telemetry spike corresponds to this physical change")
- Contradiction ("the spoken description diverges from visual or numeric evidence")
Through iterative attention operations, the model forms a joint representation, a unified internal context that reflects how the different inputs inform and constrain one another. This unified representation is the core of multimodal intelligence. It allows the system to "reason across formats" and understand how pieces of information relate in a broader situational frame.
3. Output generation
Once the shared representation is formed, the generative AI multimodal uses decoders to produce output. These outputs may be textual, visual, auditory, or mixed. The format depends on the task, but the underlying logic remains the same; the output reflects the contextual relationships learned during fusion.
- From text + image → produce a structured report.
- From a video demonstration → produce step-by-step written instructions.
- From a blueprint → produce a 3D model and explanatory narration.
- From internal enterprise data → produce forecast visualizations and recommendations.
For text generation, this typically occurs through autoregressive decoding, predicting one token at a time based on the evolving context. For images, videos, and audio, diffusion or generative modeling methods progressively convert noisy representations into detailed outputs.
Generation is effective because the model is not guessing or pattern-matching across modalities; it draws on a combined understanding, ensuring that the output remains internally consistent across formats. A key capability in this stage is the ability to convert meaning across modalities, known as transduction. For example, describing an image accurately in text requires contextual reasoning, relational inference, and domain knowledge.
Read also: In-depth guide on RAG evaluation
What are the multimodal generative AI use cases?
Multimodal generative AI starts with a single premise: meaning lives across formats. A paragraph, a blueprint, a dashboard screenshot, or a 20-second audio clip all carry parts of the same story. By converting each input into a shared semantic representation, the system can consistently compare, combine, and reason over them, then generate outputs in the format the workflow actually needs.
Interpret and analyze documents containing mixed modalities
Most operational documents aren't pure text. They mix tables, flow diagrams, stamps, signatures, and marginal notes. A multimodal system parses each element with the right encoder (OCR for text, layout-aware vision for tables, diagram parsers for schematics). It aligns them in a single representation, so relationships aren't lost. The payoff is precise extraction and validation: a purchase order number matched to a hand-annotated revision on a drawing; a tolerance band in a table checked against a symbol in a CAD snippet; a handwritten exception reconciled with policy text.
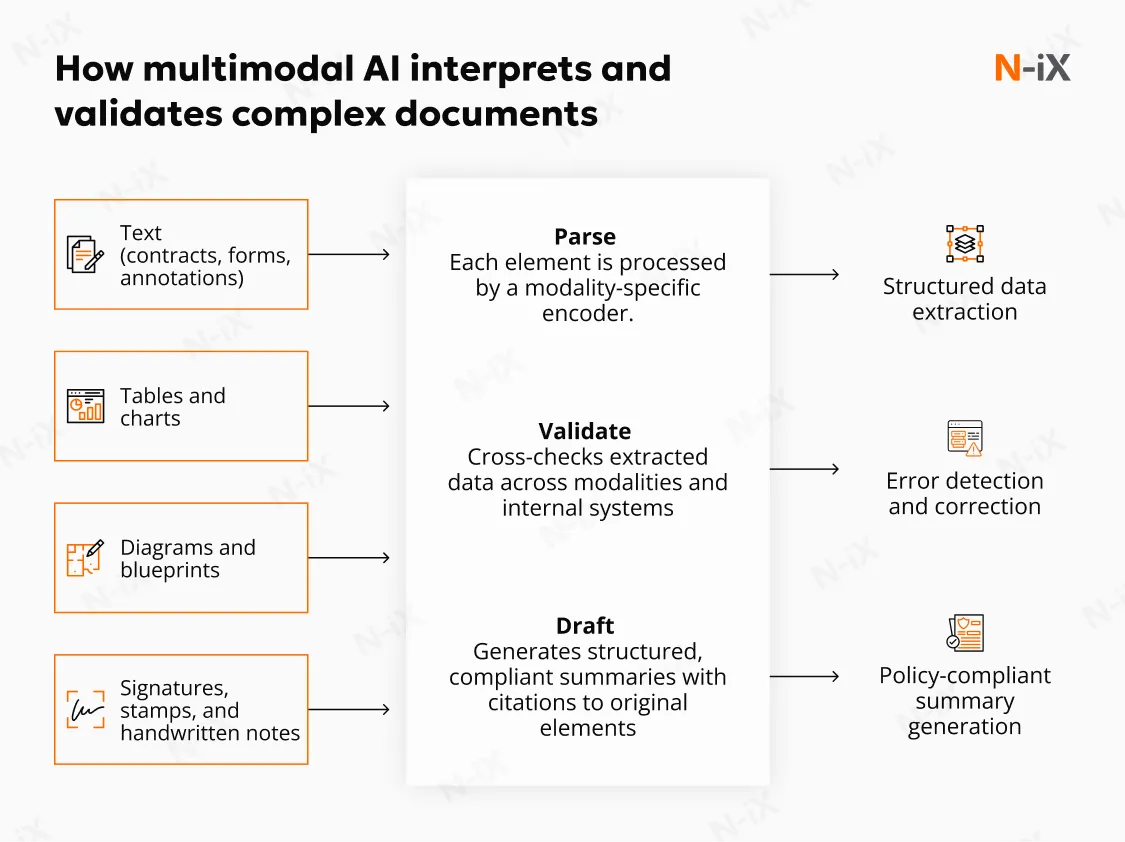
This enables workflows such as:
- Matching a product drawing against a specification and identifying whether the photographed component conforms.
- Extracting structured values from scanned forms and validating them against ERP records.
- Synthesizing product descriptions from product photos combined with structured metadata.
One practical pattern is "parse → validate → draft": extract fields, cross-check against policy or ERP, then draft a compliant summary with citations to the exact cells, shapes, and text spans it used. The question for teams is simple: which documents still require a human to stitch together visuals and text, and how much risk or delay does that create?

Assist customer support by analyzing screenshots, emails, and recorded calls
Tickets rarely arrive clean. A single case might include a screenshot with a cryptic error, a short email thread, and a call in which the user describes the steps verbally. Multimodal generative AI models align these inputs by:
- Detecting interface states from the screenshot
- Segmenting and attributing meaning to spoken phrases
- Matching the issue to a known fix or documentation entry
- Linking relevant call timestamps and visual elements as supporting evidence
The system can then propose a resolution with step-by-step instructions and a confidence score, while linking the call segment and the exact screenshot region used to make the decision. In practice, this shifts agents from manual triage to verification and exception handling.
Generate reports and summaries from meeting audio and shared screens
Meeting summaries that only rely on transcripts miss the point of most meetings: the screen. With multimodal capture, the model indexes both speech and what was shown and ties action items to the artefacts that justify them. A quarterly review, for instance, becomes a structured brief with the spoken decisions, the slide images or table ranges they reference, and links to the moments in the recording where they were discussed.
Teams receive a source-grounded narrative: what changed, why it changed, and which exhibits support the change. The immediate benefits from partnering with generative AI development companies are auditability and continuity; the downstream benefit is faster follow-through because "who does what by when" is anchored to exactly what participants saw.
Contextual reasoning over video, field inspection footage, or manufacturing streams
Video provides a direct record of real-world conditions: assembly steps, safety adherence, defect occurrence, and field conditions. Multimodal systems segment streams into meaningful events, align them with telemetry and SOPs, and reason over sequences rather than single frames.
In a line inspection scenario, the model can detect a micro-deviation in a motion path, compare it to prior runs where yield dipped, and surface an early warning with the relevant clip and sensor traces attached. In field operations, body-cam footage combined with GPS and checklists can be used to create verifiable records of task completion, with privacy filters applied on-device.
The key is cross-modal context: did the action happen, under the right conditions, within tolerance? Where anomalies are found, the system links to the exact frames and signals, so humans can make quick decisions without hunting through hours of footage.
Multi-step planning across multiple input formats
Real work spans systems: a spec in a document, parts in a PLM, schedules in a Gantt chart, risks in an email chain. Multimodal agents use the shared representation to plan across these assets, retrieve constraints from the spec, reconcile them with CAD notes, check inventory status, and generate a staged plan with dependencies and alternatives.
When a constraint changes (a tolerance tightens, a vendor slips), the agent re-plans and highlights the exact sources that forced the change. This point is where multimodal generation matters: the output isn't just a paragraph, but an updated checklist, a revised BOM comment, or a step-by-step runbook with inline citations to the visual or textual evidence used.
What risks are associated with multimodal generative AI systems?
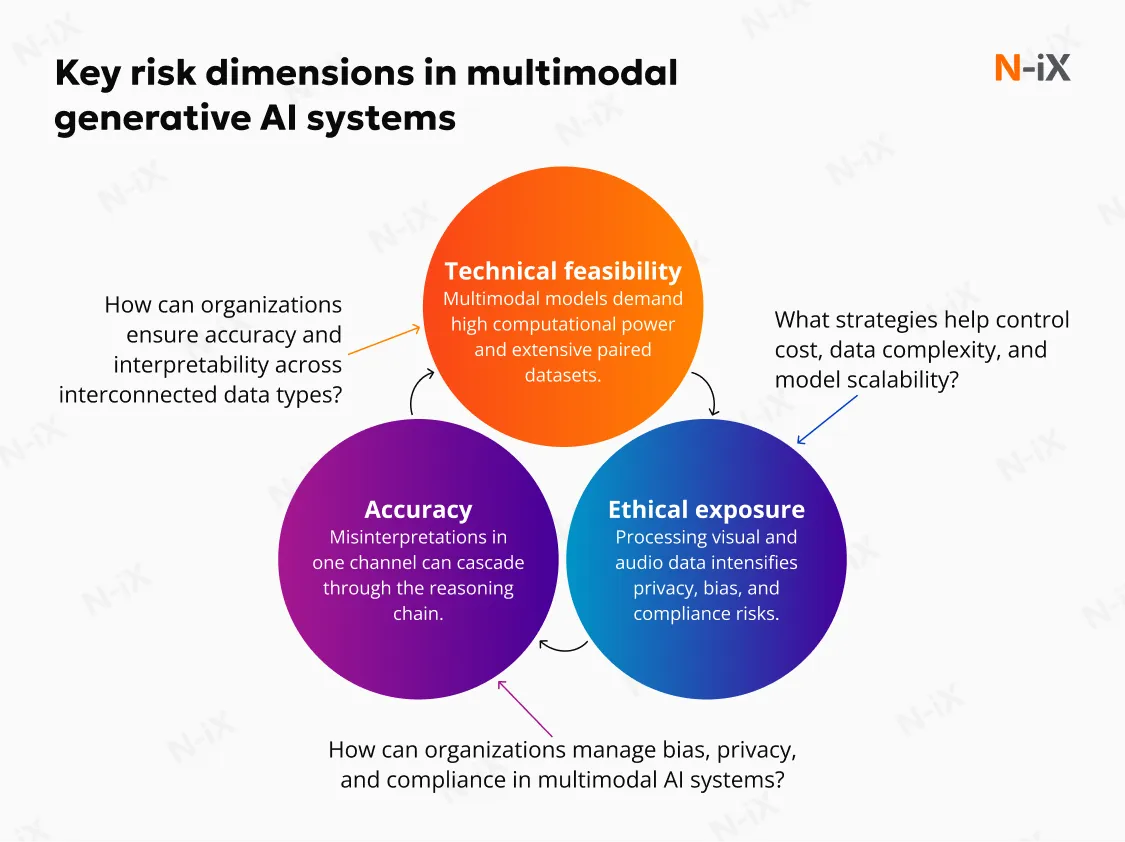
Multimodal generative AI features could introduce structural risks. The risks associated with multimodal AI can be understood across three strategic dimensions: accuracy and trust, technical and operational feasibility, and ethical and governance exposure.
Operational complexity
Multimodal models require significantly more computational power; on average, inference costs are around twice as expensive per token compared to text-only models. This limitation increases GPU demand, model hosting complexity, and total cost of ownership, which can materially impact scaling decisions.
Just as critical is the data layer. Multimodal systems require large volumes of paired, high-quality data: images labeled with the corresponding textual descriptions, transcripts aligned with video segments, and engineering drawings linked to revision histories. Many organizations possess this data, but not in a form that is immediately usable. Preparing them requires deliberate data engineering effort: normalization, pairing logic, version control, and domain-specific annotation. In other words, multimodal AI cannot be "plugged in"; it must be integrated.
Accuracy, reliability, and explainability
Multimodal reasoning increases complexity. Each modality has its own noise patterns, ambiguity, and failure modes. When these are combined, the model's reasoning chain becomes longer and inherently more fragile. Hallucination, already a well-documented risk in language models, is amplified in multimodal systems because a single misinterpretation in one modality can propagate through the output logic. An incorrect reading of a blueprint symbol, a transcription error from call audio, or a misaligned bounding box in a product image can lead to a confident but incorrect conclusion.
This failure is difficult to detect precisely because multimodal models are less interpretable. Their decision-making processes operate in dense shared latent spaces where representations of text, imagery, and sound converge. The result is a system that can produce highly fluent, visually coherent, and context-sounding outputs without a clear mechanism to trace how those outputs were formed. This opacity makes it challenging to certify correctness, audit decision paths, or justify outcomes in regulated workflows.
Ethical and privacy exposure
Multimodal systems process data that is far more personal and context-rich than text alone: facial expressions, tone of voice, location traces, and video of physical work environments. This increases the sensitivity of the data handled and the associated risk profile in the event of misuse. The potential to generate hyper-realistic synthetic media creates clear vectors for reputational harm, fraud, and disinformation.
Bias is also amplified. If a text-only system can reflect cultural bias, a multimodal system can visually reinforce it. Training corpora that underrepresent certain groups or environments can lead to subtly discriminatory model behavior that is harder to detect and correct. Meanwhile, organizations must navigate evolving regulatory frameworks across data privacy, model transparency, content provenance, and sector-specific compliance. A recent industry survey found that 91% of organizations with high-priority GenAI roadmaps do not yet consider themselves "very prepared" to deploy the technology responsibly at scale.
How to adopt multimodal generative AI: N-iX's best practices
In our experience with generative AI development at N-iX, the organizations that succeed are those that approach multimodality as an architectural and governance challenge. Below are the practices that consistently determine whether multimodal AI becomes a scalable capability or remains a stalled proof of concept.
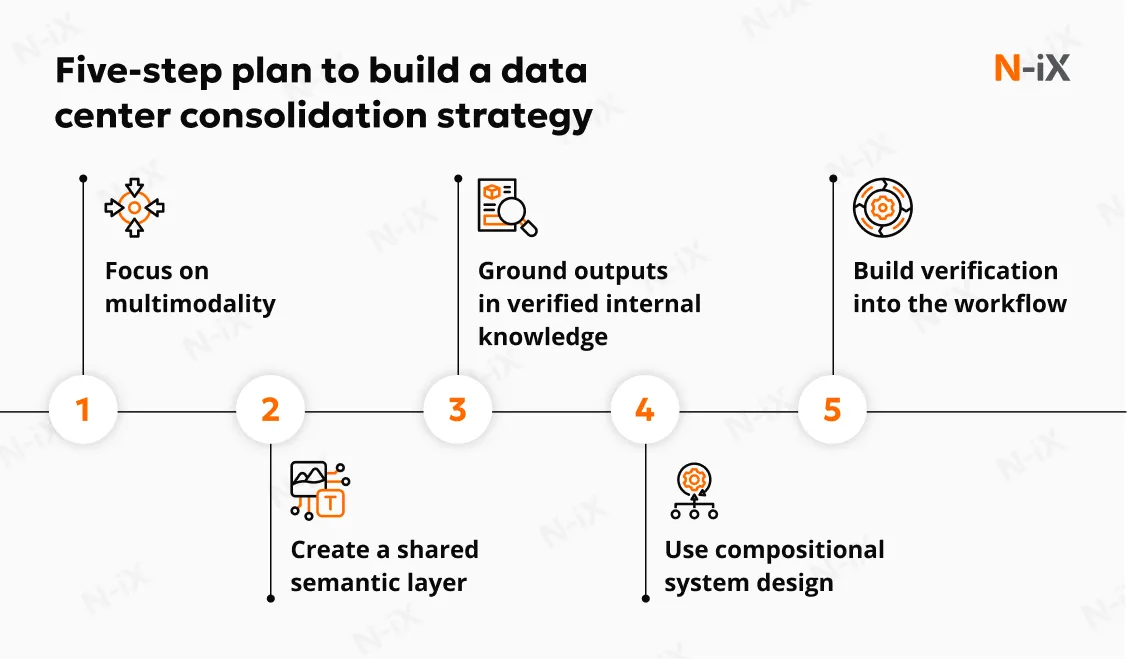
1. Focus on multimodality
Multimodal AI generates the highest return where teams already struggle to assemble context from different formats: screenshots paired with email chains, inspection footage linked to sensor data, and product documentation split across multiple platforms. Before building anything, we analyze where cognitive overhead is highest (where people lose time reconstructing what happened). Multimodal AI should first be deployed where it removes interpretation friction, not where it simply automates outputs.
2. Create a shared semantic layer
If timestamps, identifiers, terminology, and metadata do not align across systems, adding a generative AI multimodal will only amplify inconsistencies. We treat the semantic alignment layer as part of the core build: unifying naming conventions, mapping equivalent entities across systems, correlating visual and textual artifacts, and establishing reference schemas. Furthermore, it is the data foundation for generative AI reasoning capabilities for reliable system performance.
3. Ground outputs in verified internal knowledge
The system is only effective if it can interpret these inputs in relation to one another, which requires context-linked, well-structured, and consistently captured datasets. As a result, multimodal AI systems must be deployed within controlled data pipelines that enforce strict access rights, retention rules, and auditability. We consistently use retrieval-augmented and grounding pipelines to ensure that every generated statement or recommendation can be traced back to a verifiable internal reference. In production environments, LLMOps consulting services formalize these practices by introducing structured evaluation, monitoring, and prompt lifecycle management across multimodal AI systems.
4. Use compositional system design
In production environments, no single multimodal model performs optimally across all tasks. Organizations achieve long-term flexibility by composing systems from specialized components connected by shared representations. Our AI teams design systems in which models are interchangeable modules.
5. Build verification into the workflow
Even well-grounded multimodal systems will occasionally misinterpret context. The solution is to design verification into the workflow so that corrections are quick, contextual, and captured for continuous improvement. We create review surfaces that show which inputs were used, how they were interpreted, and the reasoning chain that led to the output
Endnote
The organizations that benefit most aren't those who deploy the largest models, but those who structure their data, governance, and validation loops so that insights derived across modalities can be trusted and acted on. Yet not every workflow is ready for multimodal automation. Before moving toward generative AI implementation, it is worth reflecting on a few questions:
- Does the workflow rely on information spanning text, images, audio, video, or diagrams, and does that fragmentation meaningfully slow decision-making?
- Are there clear, stable sources of truth that outputs can be verified against?
- Can the cost of error be managed through human verification loops?
- Do current governance practices (access control, data lineage, logging) support responsible deployment?
If the answer to these questions is uncertain, the model itself is rarely the starting point. The foundation is data readiness, institutional knowledge structure, and process clarity. At N-iX, we work with enterprises to build this structure. Our team designs and deploys reliable, explainable, and aligned multimodal AI that reflects how your business actually operates. If your workflows already span formats, your generative AI strategy should too.

FAQ
What is multimodal generative AI?
Multimodal generative AI refers to models that can understand and produce outputs across multiple data formats within a unified reasoning process. Instead of treating each format separately, these models create shared semantic representations that allow them to interpret and generate content coherently across modalities.
How does multimodal generative AI differ from traditional text-only LLMs?
Text-only LLMs are limited to processing and generating written language. Multimodal generative AI extends this capability by incorporating visual, audio, and other non-text inputs into the reasoning loop, enabling richer, context-dependent understanding and outputs aligned with real-world workflows.
What is the difference between unimodal and multimodal AI?
Unimodal AI models are trained to work with a single data type (e.g., only text or only images), optimized for narrow tasks. Multimodal AI models integrate multiple input types into a shared conceptual space, enabling them to reason across formats and support more complex workflows in which meaning spans various media.
What is an example of a multimodal AI model?
GPT-4o, Gemini, and Claude are prominent examples. They can accept text, images, and sometimes audio/video as input and generate outputs across these formats, enabling tasks such as interpreting screenshots, summarizing documents with diagrams, or generating visual responses to textual instructions.
How is multimodal used in generative AI?
Common use cases include document processing with tables and diagrams, customer support triage using screenshots and call recordings, automated reporting from meeting audio and shared screens, visual quality control, and sensor-video reasoning for equipment monitoring and anomaly detection.
Reference
- Implementing generative AI with speed and safety - McKinsey
- Multi-modal Generative AI: Multi-modal LLMs, Diffusions and the Unification
- The evolution of multimodal AI: Creating new possibilities - International Journal of Artificial Intelligence for Science
- Generalist multimodal AI: A review of architectures, challenges and opportunities
- Multimodal Generative AI: The Next Frontier in Precision Health - Microsoft Research
Have a question?
Speak to an expert


