
Business leaders adopting GenAI often encounter hallucinated answers and irrelevant outputs. These issues rarely stem from model performance. The root problem lies in data that is fragmented, outdated, or lacks context. According to McKinsey, 72% of leading organizations struggle to scale GenAI due to weak data management foundations [2].
Since traditional data architectures were designed for structured, repetitive processes, like billing or inventory management, they cannot handle real-time, unstructured, and cross-functional data, required for generative AI. To generate relevant and accurate outputs, GenAI needs data that is contextual, governed, and immediately accessible.
A modern data strategy for generative AI helps to achieve this goal. However, most organizations need targeted support through data strategy consulting and generative AI consulting to translate their ambitions into execution. That support includes designing future-ready data platforms, implementing governance frameworks, and creating pipelines that deliver the right data to the right model at the right time.
So how do you build a scalable GenAI foundation? To make generative AI work for them, enterprises must rethink how they structure, govern, and deliver data. Let’s start by reviewing the core pillars of a data strategy for generative AI, then examine key implementation challenges and best practices, and finally walk through a practical roadmap to execution.
Why generative AI calls for rethinking traditional data strategies
Most enterprise data strategies are built around systems of record: tools like ERP, CRM, or billing systems. These systems manage structured information like customer profiles, inventory counts, or transactions. They are designed for consistency, not flexibility. Data is typically siloed by department, stored in static formats, and optimized for historical reporting rather than dynamic decision-making.
Unlike those systems, GenAI consumes unstructured content like emails, documents, call transcripts, and sensor data. It responds to real-time inputs and draws insights across silos, such as marketing, sales, operations, and legal, and it often does so in a single interaction. Traditional architectures weren’t designed for this level of fluidity.
This mismatch reveals critical limitations. Transactional pipelines struggle to support dynamic GenAI prompts. Data lakes that collect everything lack the context GenAI needs to generate accurate outputs. Moreover, conventional governance, which is focused on compliance, cannot ensure traceability, auditability, and ethical use at the speed GenAI operates.
To deliver real business value, data must be curated, discoverable, and context-aware when GenAI generates a response. Meeting these demands requires a new approach: a data strategy for generative AI that prioritizes dynamic access, cross-domain relevance, and machine-readable context from the start.
Read more: Data modernization strategy: Rethink enterprise success
Core pillars of data strategy for generative AI
Effective generative AI implementation depends on access to trustworthy, well-structured, and business-relevant data. Instead of simply collecting information, enterprises must focus on shaping data into context-rich assets that GenAI systems can retrieve and interpret on demand. The following pillars outline the key capabilities required to make GenAI initiatives viable and scalable.
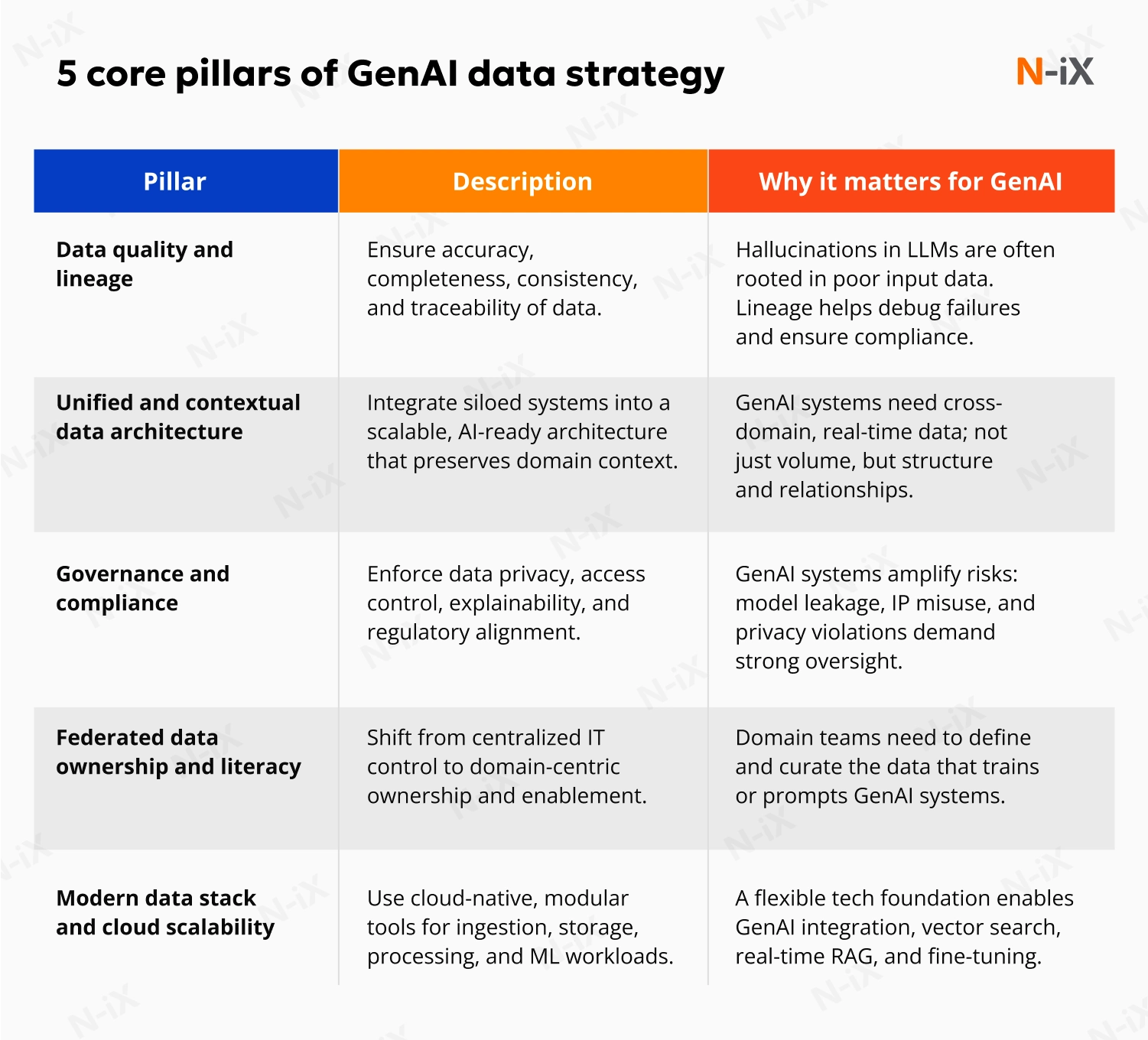
Data quality and lineage
GenAI models are only as reliable as the data they ingest. If training or prompt data is inconsistent, incomplete, or untraceable, LLMs tend to hallucinate facts or reinforce bias. According to Accenture, 75% of executives say good data quality is the most valuable ingredient for generative AI, but 48% admit their current data isn’t fit for purpose [1]. McKinsey also warns that organizations face scaling failures without clear lineage and validation steps [2]. High-performance GenAI needs consistent data pipelines, source traceability, and built-in quality checks across all lifecycle stages.
Mitigate critical generative AI security risks—download the white paper!

Success!
Unified and contextual data architecture
LLMs don’t understand business context unless data gives it to them. Connecting data from functions like HR, finance, supply chain, and customer service lets GenAI surface cross-domain insights that siloed systems miss. Yet Capgemini finds that only 51% of leaders have transparent integration processes across departments [3]. A unified architecture ensures that LLMs don’t just generate text, but respond with relevance.
The impact of a unified architecture can be illustrated through a success story by N-iX:
In a project for a peer-to-peer software review platform, N‑iX tackled the challenge of stylistic consistency across thousands of product categories. Engineers assigned fixed topic IDs and used BERTopic clustering to structure user feedback before feeding it into GPT‑4. That approach allowed the model to produce relevant summaries instead of generic responses, enhancing context alignment and content precision.
Governance and compliance
GenAI raises governance concerns that extend beyond traditional data management. Regulatory frameworks are still evolving, but enterprises must already manage risks such as biased outputs, privacy breaches, and unintended model behavior. According to Deloitte, 29% of organizations reported loss of trust due to incorrect or biased GenAI responses, underlining the compliance challenges at stake [4].
Responsible AI policies must include rules for model usage, human-in-the-loop validation, and mechanisms to prevent unauthorized use of sensitive data. Technical safeguards also play an important role. For example, retrieval-augmented generation (RAG) improves accuracy by grounding model responses in verified documents, while abstention logic helps GenAI avoid guessing when the confidence level is too low.
Federated data ownership and literacy
Data cannot remain locked within central teams if GenAI is to deliver value at scale. Business domains, such as marketing, operations, or product, hold critical knowledge about data context and usage. The essence of federated ownership is empowering these teams to own and maintain their data assets.
The AWS data mesh model has popularized this structure: domain teams publish and govern their data products, while shared platform teams provide the standards, tools, and compliance guardrails. Capgemini’s research shows that many organizations still struggle with siloed ownership and lack the infrastructure to operationalize such a model. Until those gaps are addressed, data access will remain a bottleneck [3].
Federation alone is not enough. Teams must also develop data literacy to understand, curate, and assess data readiness for GenAI use. Without that, even distributed ownership models risk producing noisy or non-actionable inputs for LLMs.
Modern data stack and cloud scalability
Scaling GenAI workloads requires a modular, cloud-native architecture for flexibility, speed, and cost control. Gartner projects that over 80% of enterprises will use GenAI APIs or models by 2026, a steep rise from under 5% in 2023 [5]. Infrastructure must adapt accordingly.
A typical modern stack includes four logical layers: data ingestion, curation, access, and orchestration. Tools such as vector databases, embedding pipelines, and prompt-routing layers support retrieval and grounding. Cloud platforms like AWS, Azure, and Google Cloud offer scalable compute, containerization, and native model integrations to manage LLM workflows securely and efficiently.
Enterprise teams should design their stacks to be cloud-agnostic where possible, using open standards and modular services that reduce vendor lock-in. Building for interoperability allows GenAI applications to evolve as models, tooling, and costs shift across cloud ecosystems.

Best practices for executing a GenAI data strategy
Balancing central control with domain autonomy
Many organizations struggle with bottlenecks when data control is centralized. However, decentralization without standards can lead to chaos. The solution is a federated model where domain teams own their data products, supported by shared policies and a central enablement team. Assigning clear roles within each function, such as data product owners, analysts, and stewards, increases speed while maintaining governance.
This structure promotes accountability and enables faster alignment between business goals and GenAI use cases. It mirrors AWS’s data mesh approach, which has been adopted in mature enterprises to scale LLM access without compromising trust or consistency.
Rolling out governance without slowing adoption
Attempting an enterprise-wide rollout of GenAI tooling too early often backfires. It exposes unresolved gaps in quality, security, and usability. A more resilient data strategy for generative AI begins with focused use cases with high data maturity and clear ROI. These pilots serve as governance sandboxes, helping organizations validate access controls, usage monitoring, and prompt engineering rules in production.
This incremental approach also helps surface hidden constraints like latency bottlenecks or excessive token costs before they become systemic. Use these learnings to refine the policy stack and unlock broader adoption across domains.
Making business context accessible at inference time
LLMs do not retain long-term knowledge of your business. They generate each response based on the data available at inference time, the moment a prompt is processed. If that data lacks structure or context, outputs tend to become generic or inaccurate. Hallucinations emerge not from model failure but from missing or misaligned information at the point of generation.
To mitigate this challenge, teams should build “data products” tailored for GenAI. These are curated datasets enriched with embeddings and stored in vector databases for efficient retrieval. Technologies such as RAG (retrieval-augmented generation) allow systems to pull the right content into a prompt when needed, improving response quality and traceability.
Unlike traditional datasets, these assets must be versioned, tested, and maintained like software components. Define ownership, monitor usage accuracy, and update them as business needs evolve.
Read more: A guide on data preparation for AI system
Implementing a data strategy for generative AI
GenAI success depends on strategy as well as disciplined execution. A phased implementation roadmap ensures data, infrastructure, and business value alignment.
1. Assess readiness and prioritize use cases
Start with a structured GenAI readiness assessment. Evaluate current data quality, architecture, ownership models, and regulatory exposure. Identify business areas with high-quality data, clear ROI potential, and operational maturity. These early use cases form the basis for controlled experimentation and fast feedback.
Explore the comprehensive guide on data readiness for AI
2. Build a modern data community
Define clear roles across the organization: domain data owners, product stewards, analysts, and a central enablement team. Empower business units to manage their own data products while enforcing shared standards and oversight. Invest in data literacy to ensure teams can evaluate and curate data effectively for GenAI.
3. Establish guardrails through governance
Develop lightweight but enforceable policies for model usage, data access, prompt engineering, and risk monitoring. Validate governance through limited-scale deployments before expanding. Include human-in-the-loop feedback mechanisms, confidence thresholds, and grounding techniques like RAG for sensitive use cases.
4. Operationalize contextual data
Build reusable, domain-specific data products enriched with metadata, embeddings, and vector indexing. Connect them to GenAI models using RAG pipelines to deliver relevant context at inference time. Maintain these assets and ensure they are versioned, tested, and tied to business outcomes.

How N-iX can help with the data strategy for generative AI
N‑iX enables enterprises to translate generative AI strategy into production-ready solutions by focusing on business value, operational readiness, and risk mitigation.
- Outcome-driven delivery: N‑iX has a proven track record of building data platforms that power AI/ML use cases, from real-time analytics to LLM-driven content generation and personalization.
- Modernization at scale: We help modernize legacy data estates across highly regulated and data-intensive industries, such as fintech, manufacturing, and telecom, ensuring compliance, performance, and scalability.
- Strong partner ecosystem: As a trusted partner of AWS, Azure, GCP, and SAP, N‑iX accelerates delivery using cloud-native services and provider-approved deployment blueprints.
- Full-spectrum capability: Our team of 2,400 professionals, including 200 data specialists, combines data engineering, master data management (MDM), AI integration, and governance design to ensure that generative AI initiatives are effective and sustainable.
Conclusion
Enterprises pursuing generative AI often invest heavily in models, but overlook the foundation required to make them operational at scale: the data. From unifying siloed systems to enabling real-time, contextual responses, success with GenAI starts with rethinking the data strategy itself. GenAI implementation requires moving beyond static architectures, building governance for dynamic workflows, and ensuring that data assets are not only accessible but optimized for machine interpretation.
Whether you're aligning cross-functional data for LLMs, building a modular GenAI pipeline, or rolling out governance for AI adoption, N‑iX delivers the technical depth and strategic oversight to make it work in your real-world environment.
References
- Accenture. Data readiness in the age of generative AI
- McKinsey & Company. The data dividend: Fueling generative AI
- Capgemini. Harnessing the value of generative AI
- Deloitte. Deloitte’s State of Generative AI in the Enterprise Quarter four report
- Gartner. Harness the Power of Democratized Generative AI to Transform Your Business
Have a question?
Speak to an expert


