
The more organizations rush to adopt AI and show progress, the more easily data becomes an afterthought. This happens because many enterprises approach AI as a layer added on top of existing data practices. Those practices were designed for reporting and optimization, not for systems that learn continuously and influence decisions in real time. Gaps that were tolerable in dashboards become critical in AI. Inconsistent definitions, delayed pipelines, and unclear ownership are minor but significant issues that directly shape model behaviour and business risk.
At N-iX, we see this pattern repeatedly when working with enterprise clients across AI development strategy implementation, data platforms integration, and production AI delivery. Data readiness for AI becomes the limiting factor long before model choice or tooling enters the conversation. It shapes how quickly AI can be delivered, how stable it remains, and whether the business trusts its outputs. Below, we break down where organizations typically lose control, which data conditions actually decide AI outcomes, and what to fix first if AI is expected to move beyond pilots and become part of day-to-day operations.
Why do AI initiatives fail without data readiness?
AI initiatives rarely fail visibly or decisively. More often, they lose momentum gradually. Pilots continue to run, teams stay occupied, and progress updates remain positive, yet little changes in how decisions are made or operations function. Beneath that surface activity, weak data foundations quietly determine how far AI can go.
Pilots that never scale
Early AI pilots often look promising because they run on curated datasets and controlled assumptions. The moment teams try to extend them into real operations, data issues surface. Source systems expose inconsistencies, historical gaps appear, and pipelines behave differently under production load. Each attempt to scale introduces new exceptions that require manual intervention. Over time, the organization stops pushing models further, not because the use case lacks value, but because scaling it becomes unpredictable and expensive.
Models no one fully trusts
As AI outputs reach business users, trust becomes fragile. Predictions shift without a clear explanation. Different teams see different results derived from the same underlying data. When stakeholders ask why a recommendation was made or why a forecast changed, the answer depends on which dataset or transformation logic was used. Faced with that uncertainty, business users fall back on familiar reports or manual judgment. AI continues to exist, but its influence on decisions steadily declines.
Data lacks the context AI systems need to act correctly
Data readiness depends entirely on how the data will be used. Many initiatives fail because organizations attempt to prepare data “in general,” without anchoring it to a specific decision, workflow, or AI technique. Predictive models, optimization systems, and generative AI all require different levels of semantic clarity, historical depth, and lineage.
When data lacks consistent definitions, clear ownership, or traceable transformations, models cannot reliably interpret what they are learning. Outputs may look reasonable, but they drift away from business reality, making them difficult to trust or explain.
Recurring data preparation cycles
Low data readiness pushes most of the effort into downstream preparation. Teams spend significant time cleaning data, rebuilding features, and revalidating datasets for each new model or use case. This work rarely appears on roadmaps, yet it consumes most of the delivery capacity. Instead of improving models or expanding AI adoption, teams cycle through remediation tasks that never fully resolve the underlying issues.
Governance that arrives after something breaks
Governance often enters the picture only once risk becomes visible, and questions around bias, explainability, or compliance trigger reviews and controls late in the process. By then, AI systems are already tied to fragmented data sources and undocumented pipelines. Adding governance at this stage slows delivery without restoring confidence, because the root causes remain untouched.
Why this gets mislabelled as “AI complexity”
These symptoms are frequently attributed to the inherent complexity of AI. Models are described as opaque, technologies as immature, and delivery as experimental. Data issues are harder to acknowledge because they span multiple teams, legacy systems, and long-standing practices. Framing the issue as AI complexity feels safer than confronting foundational data gaps that require organizational change.
Weak data foundations have direct, measurable consequences:
- Longer time to value as rework and validation cycles multiply;
- Higher operating costs as each AI initiative requires bespoke data preparation and ongoing fixes;
- Increased regulatory and reputational risk when AI decisions cannot be traced back to consistent, reliable data.
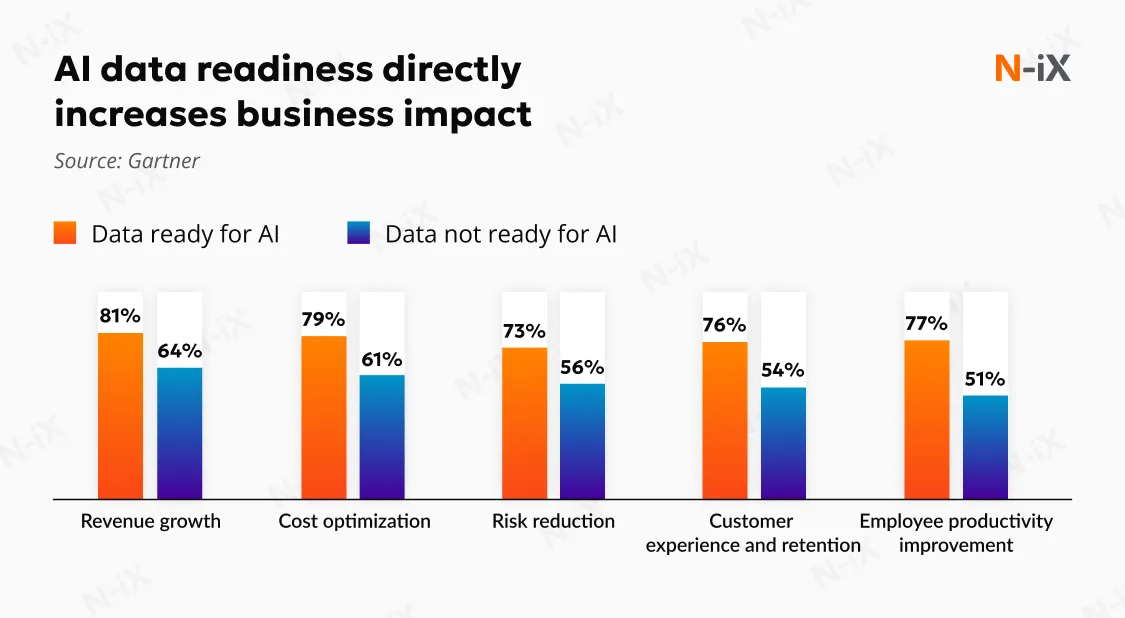
Data readiness determines whether AI becomes a controlled, scalable capability or remains a fragile set of experiments. Without it, AI does not fail outright; it becomes slower, more expensive, and harder to defend with every iteration.

What is data readiness for AI?
AI data readiness (AIDR) refers to a state in which data is deliberately prepared, tested, and governed so it can be used safely and effectively by AI systems in real operating conditions. It is often described as the foundation of AI, but in practice, it functions more like a constraint: when readiness is weak, outcomes become unstable regardless of model quality. Inaccurate, incomplete, or poorly governed inputs shape behaviour in ways that are difficult to predict or justify.
A critical distinction is that data cannot be made “ready” in the abstract. Data readiness is always contextual. It depends on how the data will be used, which decisions the AI system is expected to influence, and which techniques are applied. Data that is sufficient for reporting or exploratory analysis may be unsuitable for forecasting, optimisation, or generative systems. Organizations demonstrate readiness by explicitly aligning data to each use case, continuously validating it as conditions change, and governing it within the ethical, legal, and operational boundaries relevant to that context.

In practical terms, data readiness for AI exists when an organization can reliably do three things.
- First, it can train AI systems on signals that reflect how the business actually operates. Historical data is consistent enough to capture real patterns rather than artefacts of system changes, process exceptions, or one-off fixes. Feature engineering becomes a matter of refinement.
- Second, it can deploy AI into operational workflows without introducing hidden risk. Data pipelines are dependable, access is governed, lineage is understood, and outputs can be traced back to source assumptions when challenged. AI decisions are explainable in the context of the business.
- Third, it can maintain AI performance as conditions change. Data drift is detected early, remediation ownership is clear, and changes in upstream systems do not silently invalidate models. Stability is managed as an operational concern.
Seen this way, AIDR is not a one-time project or a maturity milestone. It is an operating condition that allows AI to function as a dependable capability.
What makes data AI-ready?
In enterprise environments, AI-ready data is defined less by abstract standards and more by whether it can support learning, deployment, and long-term reliability simultaneously. Several components determine that capability.
- Data quality: Whether models can learn from consistent business signals without constantly relearning the past? Stable patterns matter more than perfectly cleaned values. Data must preserve consistent meaning over time so models learn how the business actually behaves during a particular period. When outcomes change, teams need to distinguish between genuine behavioural shifts and artefacts introduced by the data itself.
- Structure and accessibility: Is the data available when decisions are made? AI systems often sit inside operational loops. Delayed refreshes, fragile pipelines, or manual extracts introduce uncertainty that directly affects model behaviour. Predictable access and delivery are what allow AI to move beyond experimentation.
- Interpretability: Whether the data carries a single, shared interpretation? AI systems infer meaning from data. When the same concept is defined differently across systems or teams, models absorb that ambiguity and reproduce it at scale. Consistent semantics are what make AI outputs explainable and defensible.
- Representative coverage: Whether the data reflects reality rather than an idealized version of it? Real operations include edge cases, exceptions, seasonal effects, and imperfect records. Removing these elements may improve surface-level quality, but it weakens models once they encounter real conditions. Representative coverage enables AI systems to remain robust outside controlled environments.
- Traceability: Where did the output come from, and why did it occur? Once AI influences decisions, traceability becomes non-negotiable. Lineage across sources and transformations allows organizations to explain behaviour, investigate issues, and meet regulatory or internal review requirements.
- Security: Who is accountable when something changes? AI-ready data has clear ownership, governed access, and embedded controls. When data shifts or behaviour drifts, responsibility is visible, and remediation is possible without slowing delivery.
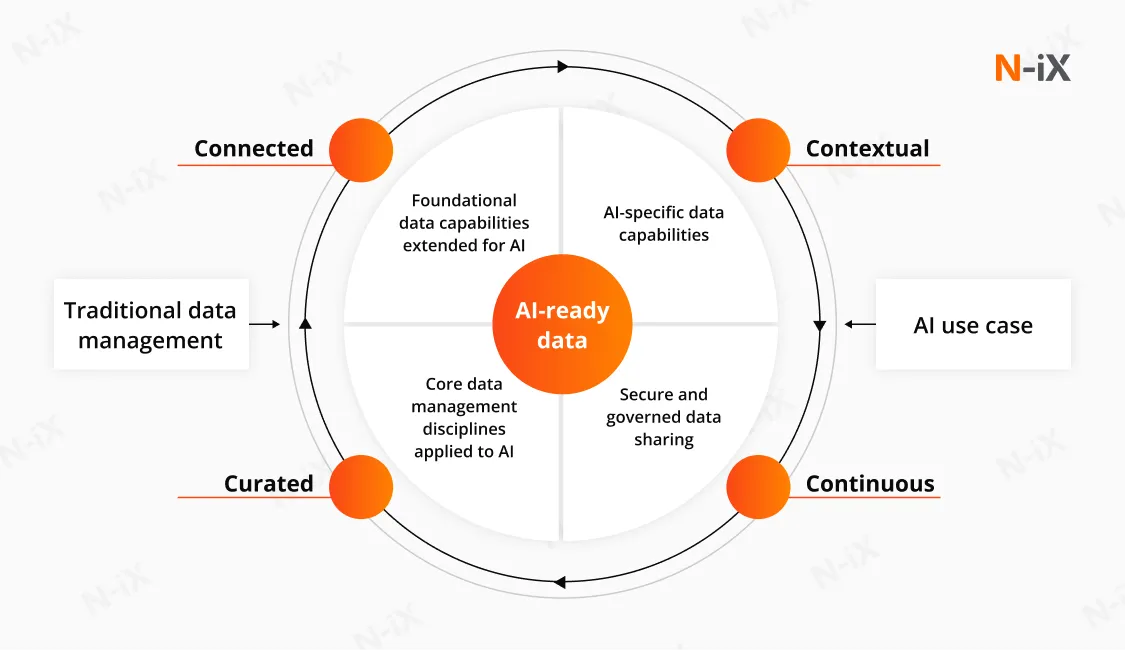
The core pillars of data readiness for AI
1. Data governance
Effective data governance is visible when questions about AI behaviour can be answered without escalation loops. Ownership of data domains is explicit, decision rights over definitions are agreed in advance, and accountability does not shift when models surface uncomfortable results. Governance works when AI teams know which data can be used, under which constraints, and who is responsible when outcomes are challenged. When governance is weak, controls appear late, usually after risk has already materialized.
2. Metadata management
Metadata matters once AI systems evolve faster than documentation can keep up. Active metadata enables teams to trace how data was transformed, where it is used, and which models depend on it. Practically, this means identifying which upstream change affected a prediction and assessing its impact before business users lose trust. Without this capability, incidents are investigated retrospectively, often after decisions have already been influenced.
3. Data processing
Data ready for AI processing is evident when new use cases do not require rebuilding datasets from scratch. Stable feature pipelines, consistent representations, and controlled transformations allow teams to iterate on models. Where processing is immature, most effort goes into re-engineering data for each initiative, extending timelines and inflating costs without improving outcomes.
4. DataOps
DataOps becomes relevant when data delivery is expected to be reliable. Automated pipelines, quality checks, and observability reduce dependency on manual intervention and individual expertise. This shows up as fewer production incidents, faster recovery from failures, and predictable delivery across environments. Without DataOps, AI delivery scales linearly with operational effort.
5. Unified data access
Unified access matters when AI systems need to combine signals across domains. Standardized interfaces and shared access patterns reduce duplication and data integration debt. In practice, new AI initiatives can reuse existing data access rather than negotiate permissions and pipelines from scratch. Fragmented access slows delivery and limits the scope of AI insights.
6. Continuous qualification
Continuous qualification is present when changes in data are detected before they affect AI behaviour. Monitoring for drift, semantic changes, and quality degradation allows teams to intervene early. Data readiness for AI avoids sudden performance drops and the need for emergency remediation after trust has already been lost.
Data readiness for different AI applications
One of the most common reasons AI initiatives stall is the assumption that “AI-ready data” is a single, universal state. In practice, data readiness for generative AI is tightly coupled to what the AI system is expected to do. The same dataset can be fit for one class of AI and completely inadequate for another.
Predictive and forecasting AI
Predictive systems rely on historical signals to extrapolate future behaviour. Here, readiness is less about volume and more about temporal integrity and stability. Data ready for AI predictive use cases must reflect consistent business logic; if definitions, policies, or systems changed mid-stream without clear documentation, the model will learn contradictions. Key variables must be sufficiently deep to capture seasonality, cyclical effects, and structural breaks; predictions become fragile in real-world conditions.
Under these conditions, data drift becomes a direct business risk. If upstream processes change but training assumptions remain frozen, the model may continue generating confident outputs that no longer reflect operational reality.
Operational AI (real-time routing/automated approvals)
Operational AI systems sit directly inside business processes. Their value depends less on aggregate accuracy metrics and more on freshness, reliability, and failure tolerance. Freshness, latency, and failure tolerance matter more than offline validation scores.
Data readiness in this context hinges on immediacy and resilience. Data must reflect the current state of operations at the point of decision, with a clearly defined tolerance for latency. When data arrives late, partially, or not at all, the system should degrade safely through confidence thresholds, fallbacks, or structured human-in-the-loop controls.
In operational settings, a highly accurate model trained on stale or intermittently unavailable data can cause more damage than a simpler model built on stable inputs. Readiness, therefore, extends beyond model quality into pipeline reliability, AI observability, and well-defined decision boundaries.
Generative AI and LLM systems (enterprise copilots, knowledge assistants, document automation)
Generative AI readiness is frequently overstated because unstructured data is abundant. Availability, however, does not guarantee suitability.
Enterprise generative systems depend on the integrity of knowledge. Information must be current, authoritative, and traceable to a clear source. Documents require version control and scoping to prevent outdated or conflicting guidance from being treated as fact. Access boundaries must be enforceable so that sensitive, regulated, or context-specific information cannot leak into responses.
The risk profile here differs from predictive or operational AI. Poorly governed knowledge leads to outdated recommendations presented with certainty and subtle exposure of internal information. In generative AI systems, semantic consistency and governance discipline outweigh raw document volume.
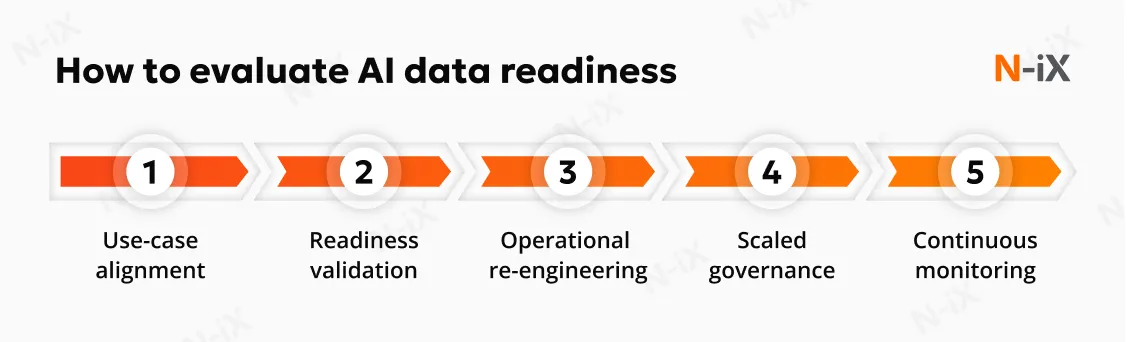
How to evaluate AI data readiness: Key stages on the roadmap
1. Start with the three core evaluation questions
Every AI initiative should be assessed against three questions. Together, they determine whether data can support AI beyond experimentation.
Does the data align with the use case?
Alignment assesses whether the data accurately reflects the problem the AI system is expected to solve. This goes beyond availability or basic quality checks. AI data readiness assessment focuses on:
- Representativeness of real-world patterns, including errors and outliers;
- Suitability of the chosen AI technique for the available data;
- Data volume relative to learning requirements;
- Semantic clarity, including labeling or annotation where required;
- Diversity and coverage to mitigate bias;
- Traceable lineage to establish trust in provenance.
Can data use be qualified to meet confidence requirements?
Qualification tests whether data can sustain expected confidence levels during training and production. Evaluation criteria are:
- Ongoing validation and verification processes;
- Performance and cost efficiency as data scales;
- Versioning to manage data and model drift;
- Continuous regression testing;
- Observability metrics that expose changes in data behaviour.
Is data governed in the context of the use case?
Governance must be assessed in relation to how data fuels a specific AI system. Key elements include:
- Clearly defined data stewardship;
- Compliance with applicable regulations such as GDPR or the EU AI Act;
- Embedded ethical constraints and bias management;
- Controlled inference, derivation, and secondary use of outputs.
Answering the three core evaluation questions gives a snapshot of where AI data readiness stands today. The next challenge is to turn that diagnosis into a structured change programme that can scale. The roadmap below breaks this into discrete steps that data and analytics leaders can drive, with clear outcomes and decision points at each stage.
2. Assess data management readiness against specific AI use cases
The starting point for data readiness for AI is a targeted review anchored in real AI initiatives that the organization intends to deliver. Readiness becomes visible only when current data practices are examined against specific techniques, decision scopes, and risk exposure.
At this stage, the objective of data management is to surface where alignment, qualification, or governance will break first. Gaps typically emerge around representativeness, semantic consistency, lineage, or the ability to monitor change once models are deployed. The outcome should be a prioritized view of constraints that will prevent selected AI use cases from moving beyond pilots. This assessment creates the factual basis for all subsequent decisions.
3. Develop data management practices for AI-specific demands
Traditional data management practices evolved to support reporting, compliance, and historical analysis. AI introduces fundamentally different requirements that those practices rarely address by default. Data must remain representative under change, behave predictably over time, and support continuous validation.
Evolving practices typically involve embedding DataOps principles into AI-critical pipelines, treating features and training datasets as managed assets, and shifting quality expectations away from cosmetic cleanliness toward behavioural stability. Fairness and bias considerations also move upstream, becoming part of data preparation. The goal is to replace ad-hoc preparation with repeatable practices that continuously produce data suitable for learning systems.
4. Scale and govern AI-ready data
Once foundational practices and platforms are in place, attention shifts to scale. The central risk at this stage is fragmentation: multiple teams solving the same readiness problems independently, with inconsistent controls and duplicated effort.
Scaling readiness requires standardising how alignment, qualification, and governance are applied across AI initiatives. Clear stewardship, consistent escalation paths, and embedded regulatory controls prevent AI systems from becoming isolated exceptions that are difficult to defend. Governance evolves from reactive oversight into a stabilising mechanism that allows faster, safer delivery.
5. Continuously validate data
From our experience at N-iX, the point at which many AI initiatives quietly lose momentum comes after deployment. Data does not stay still. Business rules change, customer behaviour shifts, upstream systems evolve, and assumptions that once held may no longer apply. AI systems absorb all of that immediately.
For this reason, data readiness cannot be treated as something achieved and then left behind. It has to operate as a continuous feedback loop. The organizations that sustain AI in production invest in continuous visibility into how data behaves over time. Active metadata, lineage tracking, and automated consistency checks become everyday instruments.
What makes this discipline effective is the early signal. Subtle drift in distributions, semantics, or data relationships is detected before it turns into unstable predictions or unexplained behaviour. Teams with data readiness for AI can distinguish real business change from data degradation and respond deliberately.
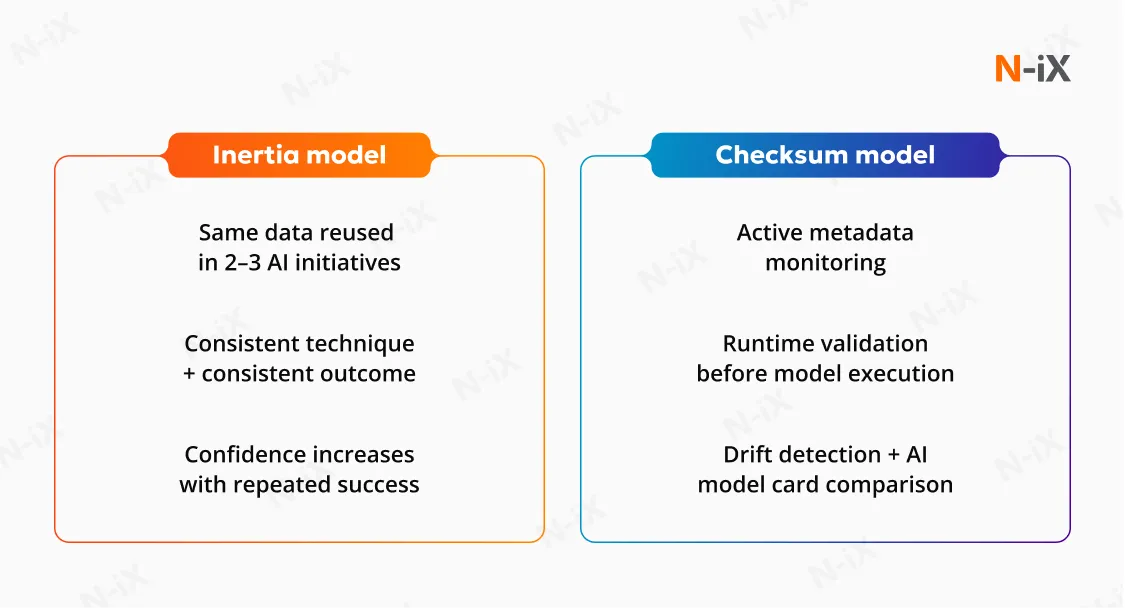
AI-ready data matures in two ways. First, through reuse. When the same data asset supports multiple AI initiatives successfully, it gains operational inertia, a form of earned trust based on consistent outcomes.
Second, through automation. Advanced organizations move from trust-by-history to trust-by-design. Automated “checksum” processes validate distribution, lineage, and semantic consistency before each model run.
Partner with N-iX: Make AI decisions defensible
AI data readiness is not binary. It accumulates across maturity stages. Early proof-of-concept readiness contributes only a small fraction toward full production trust. Even a “fully ready” POC may represent less than 20% of what is required for production-grade AI, according to Gartner. This explains why pilots succeed, but production fails. Without data readiness, every new use case feels riskier, more expensive, and harder to justify. With it, AI systems can be challenged, explained, and trusted even as business conditions change.
This is the work we do at N-iX. With over 23 years of experience, we have delivered more than 60 data initiatives for 160 enterprise clients. Our team of 200 data and AI experts has repeatedly seen the same pattern: AI innovation outpaces data discipline.
We evaluate the current data environment across five critical dimensions of readiness, examining how well data aligns with concrete AI use cases, how reliably it can be qualified over time, how governance applies in context, and whether existing practices can scale without introducing risk.
If your AI initiatives are slowing down, losing trust, or stalling at scale, reach out to N-iX to assess whether your data foundations are ready to support real decisions.

FAQ
What is AI-ready data?
Data readiness for AI refers to an organization’s data's ability to support AI systems in real operating conditions reliably. It goes beyond having data available and focuses on whether the data is aligned with a specific AI use case, continuously qualified over time, and appropriately governed.
Is data readiness the same as data quality?
Data readiness for AI encompasses data quality but is broader and more operational. High-quality data can still be unready for AI if it lacks representativeness, semantic consistency, lineage, or governance. AI systems require data that remains stable and interpretable over time.
Can data be made “AI-ready” in advance?
Data cannot be made AI-ready in general or prepared once for all future use cases. Readiness is context-dependent and depends on the AI technique, the decision scope, and the business risk of each initiative. As data, models, and business conditions change, readiness must be continuously re-evaluated.
What happens if AI data readiness is ignored?
When data readiness is ignored, AI initiatives rarely fail immediately but gradually lose credibility. Models become harder to explain, outputs are questioned, and decisions revert to manual processes. Delivery timelines extend as teams repeatedly fix the same data issues downstream. Over time, AI becomes perceived as risky.
References
- How to make data AI-ready: Essentials to capture AI value - Gartner
- AI-ready data: Driving your AI-enabled transformation - EY
- AI and GenAI demand a new approach to data management - Gartner
- Transforming AI outcomes with effective data readiness - Deloitte
- Why data readiness is a strategic imperative for businesses — World Economic Forum
- Harnessing the value of AI - Capgemini
Have a question?
Speak to an expert


