
Consider how people make sense of their surroundings. Before you form a decision, your brain resolves conflicting signals, filters noise, interprets context, and fills in gaps. If any of those signals are distorted, the quality of your conclusion suffers. AI follows similar logic: it can only perform well if the data it receives is clear, complete, and grounded in a real business context. When the inputs are unreliable, the outputs become unpredictable, and no amount of model tuning can compensate.
Therefore, data preparation is not a technical side task or a preliminary step that teams can "get to later"; it becomes the foundation of any successful AI initiative. Without it, prototypes look impressive, but production systems struggle with drift, rising costs, and decisions that stakeholders can't rely on with confidence. Organizations that invest in mature data pipelines in collaboration with an AI development company benefit from predictable deployments, lower error rates, and stronger model performance across environments. Let's break down what data preparation for AI involves, why it is a business-critical investment, and what you need to know before scaling AI across the organization.
Why does data preparation determine the success of your AI initiatives?
Even the most advanced models, LLMs, multimodal systems, and predictive engines, are only as reliable as the data pipelines behind them. When data is incomplete, inconsistent, siloed, or poorly governed, AI solutions don't just underperform; they become expensive to scale, difficult to trust, and nearly impossible to operationalize across the organization.
Gartner estimates that through 2026, organizations will abandon 60% of AI initiatives that are not supported by AI-ready data. Without rigorous preparation, AI may become expensive to build, difficult to operate, and hard to trust.
Data quality directly shapes prediction reliability
Every predictive, generative, or analytical system learns patterns embedded in the data. If the data contains inconsistencies, unresolved duplicates, unreliable attributes, shifting definitions, or omission of critical signals, the model learns those flaws as if they were facts. High-quality data increases the signal-to-noise ratio, improves model convergence, reduces the number of training cycles, and produces outputs that remain dependable across different operational conditions.
Reducing bias requires controlled, well-prepared datasets
Historical datasets carry the operational and human patterns that produced them. If those patterns include inequality, under-representation, or skew, a model will reproduce the same behavior at scale. Bias does not disappear through model tuning alone; it has to be identified and corrected during preparation. Addressing these issues during preparation is more effective and significantly less costly than repairing them after deployment.
Clean data lowers operational costs and accelerates delivery
Inefficient data pipelines create delays that extend through the entire AI lifecycle. When teams frequently clean inputs, correct mislabeled entries, reconcile inconsistent schemas, or manually align disparate datasets, the timeline stretches and compute costs rise. Data preparation for AI reduces the number of training iterations required, lowers infrastructure costs, minimizes errors in downstream workflows, and accelerates experimentation.
A recent N-iX engagement with a global stock photography platform demonstrates the practical value of this foundation. The team reorganized fragmented SQL-based datasets into a governed cloud architecture built on Snowflake, DBT, and Looker, reducing storage costs and improving processing speed. This made the data pipeline reliable enough for AI and analytics expansion. This shift shows how clean, structured, and well-managed data directly lowers TCO and accelerates the introduction of AI-driven initiatives.
Learn how we modernized a global stock image and media platform in the case study
Prepared data improves model performance and business applicability
AI systems fail in unexpected ways when they are trained on data that does not reflect the full breadth of real-world scenarios. AI-driven data preparation ensures that the dataset captures the necessary variability, aligns with actual business processes, and incorporates the contextual details that models rely on for accurate inference. A strong preparation practice supports:
- Repeatable ingestion and transformation;
- Standardized semantic definitions across the organization;
- Consistent metadata and lineage;
- Seamless integration of new data streams.
One real-world example comes from our engagement with a major media technology company: approached a library of over 1.5B multimedia assets, we engineered pipelines to extract metadata, convert content into embeddings, and enable vector-based similarity search. This led to a 100 times increase in asset access and made the data broadly usable across multiple AI/ML applications.
Learn more details: Optimizing content analysis with AI and data analytics for a leading media technology company
|
AI-ready data |
Not prepared data |
|
Consistent structure, unified semantics |
Conflicting schemas, inconsistent definitions |
|
Complete histories with reliable timestamps |
Missing periods, overwritten or partial logs |
|
Clean attributes with validated ranges |
Noise, errors, outliers, unverified values |
|
Documented lineage and metadata |
Unknown origin, undocumented transformations |
|
Governed access and controlled sensitivities |
PII/IP exposure, unclear ownership |
|
Balanced representation across segments |
Skewed populations, bias-prone samples |
Key steps of data preparation for AI
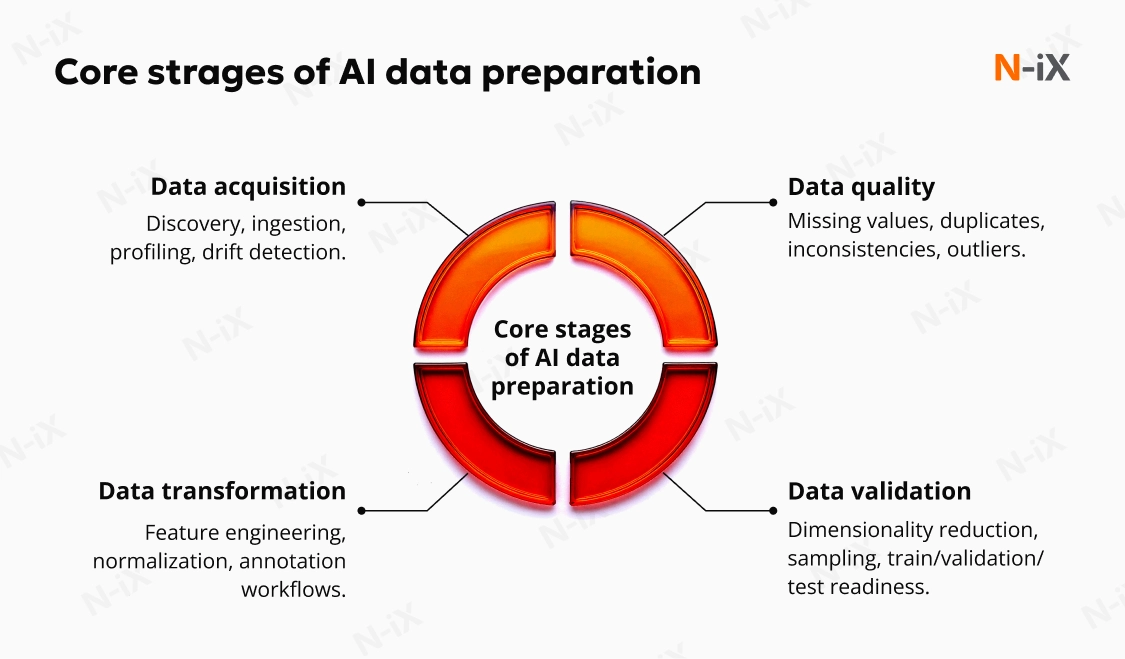
Step 1: Data collection
Data collection is often where AI initiatives surface the real structure, gaps, and inconsistencies within enterprise data. What initially looks like an extraction exercise usually becomes a discovery process, revealing gaps, inconsistencies, duplicate systems of record, and entire data sources that were never documented. The collection phase defines what the model can learn, how far it can scale, and whether downstream teams will spend their time refining insights or correcting foundational issues.

Data preparation for AI begins by mapping the information that actually exists across the organization. Rarely is it stored in one place. Operational systems capture transactions. Analytical environments, on the other hand, hold historical records. Cloud services may store user interaction data, while teams keep local extracts in SharePoint or Drive. Product, finance, and operations groups often maintain their own datasets. Bringing these together requires a deliberate strategy, because fragmented data is one of the leading causes of delayed timelines and misaligned models.
Once discovery is complete, ingestion consolidates this scattered information into a controlled preparation environment. In practice, ingestion requires resolving schema conflicts, aligning timestamp conventions, capturing lineage, and validating that the extracts represent a complete and chronological view of the business processes the model must learn. To make the data preparation for AI models more predictable, most teams rely on a structured intake checklist that includes:
- Verifying source connectivity and access permissions;
- Capturing metadata (origin, format, refresh cadence, sensitivity);
- Reconciling different schemas, encodings, and naming conventions;
- Checking if the extract reflects the full history or only recent snapshots.
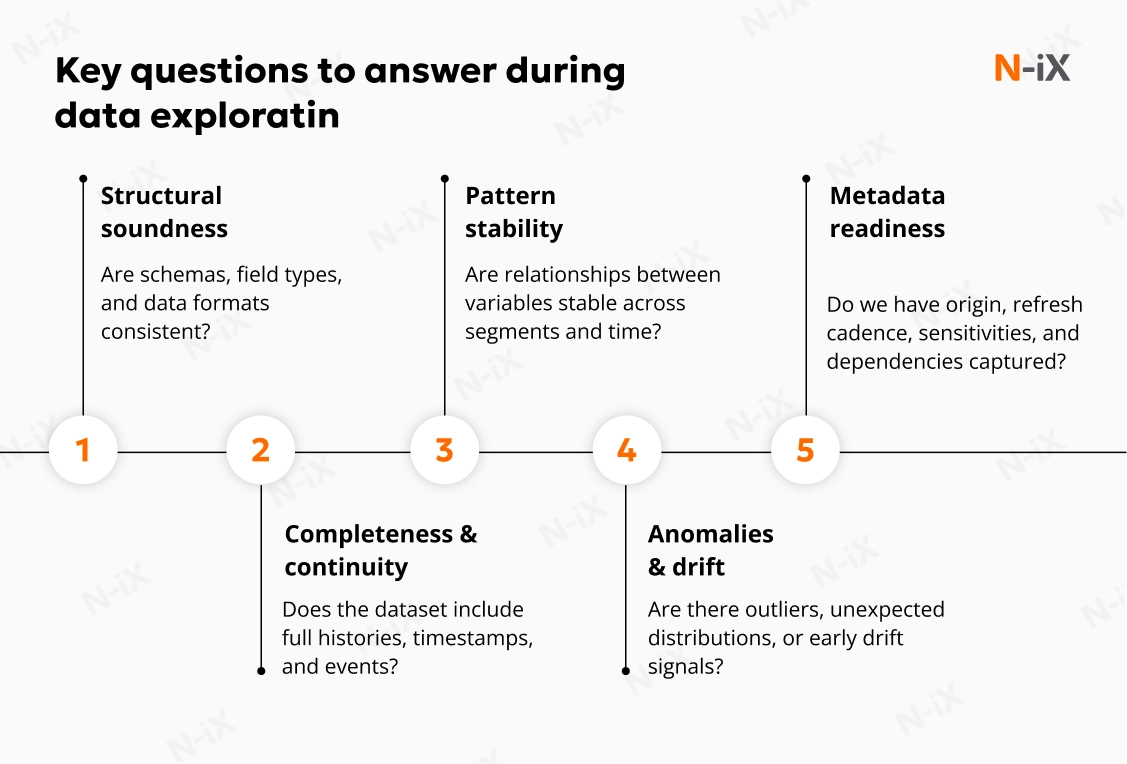
Step 2: Data exploration
Once the data is collected, exploration determines whether it is usable in its current form and what transformations will be required. Exploration involves scrutinizing distributions, identifying dominant patterns, and understanding whether relationships between variables are stable or vary by segment, geography, or time period.

Profiling complements exploration by exposing structural qualities: field cardinality, sparsity, category drift, range violations, and unexpected formatting differences. It helps uncover hidden issues such as inconsistent definitions of key business metrics, irregular logging intervals, incorrect category codes, or mismatches introduced during previous migrations.
This phase also produces essential metadata. Capturing information about data origin, refresh frequency, sensitivities, dependencies, and historical changes indicates that data can be governed, audited, and versioned correctly. Strong metadata maintains long-term model quality, supports future retraining cycles, and mitigates operational risk. To make this AI-driven data preparation step actionable, teams typically establish a metadata foundation that includes:
- Structural information (schemas, field types);
- Operational context (source system, owner, refresh cadence);
- Quality insights (missingness ratios, outlier density, data drift signals).
Step 3: Data cleaning
Cleaning is where raw data becomes trustworthy enough to support Machine Learning. It addresses the practical issues that accumulate in real systems: inconsistent values, outdated entries, mixed formats, missing records, and noise introduced by human or automated processes.
At this stage, the AI/ML data preparation work typically centers around three areas:
- Structural issues such as missing fields, incomplete histories, and sparse categories;
- Redundancies introduced by duplicated records or overlapping systems of record;
- Inconsistencies in formatting, naming conventions, units of measurement, and categorical labels.
Each issue requires careful handling. Some missing values can be imputed based on statistical relationships; others may indicate that the attribute is unsuitable for modeling. Duplicate records distort class distributions and must be resolved before feature engineering begins. Format standardization ensures that fields carry consistent meaning across all datasets, which is critical for reproducibility and downstream integration.
Outlier data management is another key component. Outliers may reflect meaningful extreme events or simple data entry errors. Distinguishing between the two prevents the model from learning patterns that do not align with reality. This work often uncovers issues that originate upstream in operational processes, prompting conversations about data entry practices, logging standards, or system configuration.
Secure, scale, and govern your AI— get the guide to AI data governance today!

Success!
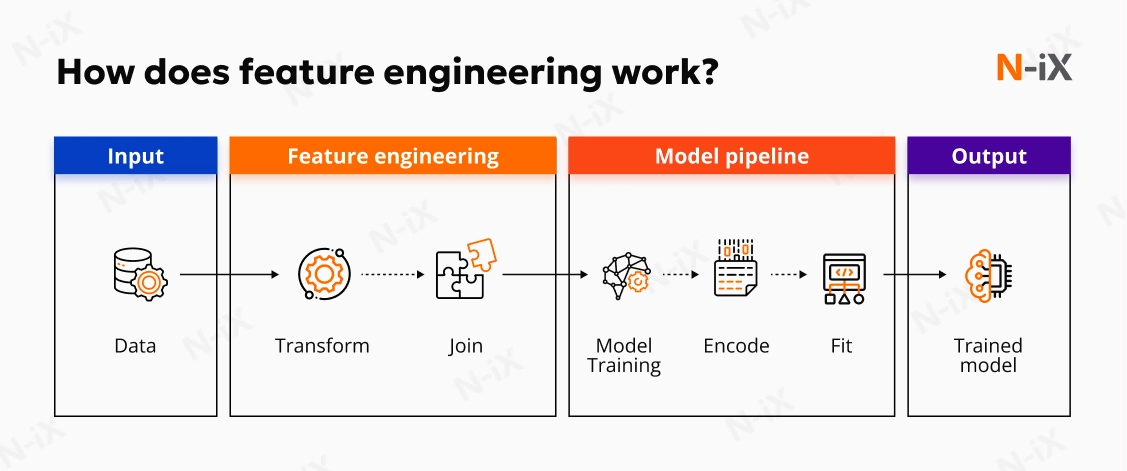
Step 4: Data transformation and feature engineering
Transformation often starts by scaling numerical features to comparable ranges. Without normalization or standardization, high-magnitude attributes dominate learning signals and distort training behavior. This work requires converting operational realities into measurable variables that algorithms can process. To give structure, teams typically refine the dataset through steps such as:
- Scaling numerical features to consistent ranges so the training process doesn't overweight specific inputs;
- Encoding categorical values using techniques appropriate for the model type and data sparsity;
- Blending datasets sourced from different systems or functional areas to provide a complete operational view.
But the most strategically impactful component is feature engineering. It captures business logic that the model would otherwise miss, whether that's aggregating purchase behavior into probability scores, creating risk-related time windows, or deriving relationship indicators across entities. This step often determines whether the algorithm learns what is relevant or becomes overwhelmed by noise.
Step 5: Data labeling
Labeling defines the correct answers the algorithm is expected to learn from, which means the quality of labeling directly shapes the behavior of the resulting system. What often surprises organizations is how much precision labeling requires. Labels must be consistent, unambiguous, and aligned to the intended business outcome. When definitions drift, even slightly, the model learns conflicting signals. If two teams interpret the same event differently ("fraud," "flagged," "needs review"), the model absorbs the inconsistency and produces uneven results.
Because of this, labeling is rarely a quick operational task within data preparation for AI. It requires clear taxonomies, domain-specific criteria, repeatable workflows, and continuous review. In sensitive areas, annotation often depends on expert knowledge that generalist annotators cannot replace. Even when automation assists with pre-labeling, human verification remains essential.
Step 6: Data reduction
Reducing dataset size without losing essential information becomes a practical necessity.
- Trim noise and redundancy. High-dimensional data can introduce instability, inflate computation time, and obscure the variables that truly matter. Dimensionality reduction techniques identify which features carry predictive value and which add little more than statistical friction. Similarly, feature selection narrows the dataset to the variables that meaningfully influence the target outcome, reducing computational costs and the risk of overfitting.
- Sampling. Rather than training on massive raw datasets, teams often create smaller curated subsets that mirror the statistical properties of the full population. These "data twins" accelerate experimentation and model iteration without sacrificing accuracy. Feature selection complements and identifies which variables are predictive.
The broader value of data reduction lies in control. Smaller, cleaner, more targeted datasets lead to faster iterations, clearer diagnostics, and better cost predictability, elements that become increasingly important as AI initiatives move from experimentation into production environments.
Step 7: Data validation
Before an AI model is trained, the prepared dataset must be tested to ensure it supports reliable learning and consistent real-world performance. This final step is the checkpoint that determines whether the entire pipeline up to this point has produced data that is stable, representative, and safe to deploy. At this stage, the question is simple: Can this data support a model that behaves predictably under operational conditions?
A structured split of the dataset creates the conditions to answer that question. By separating data into training, validation, and testing subsets, organizations establish clear boundaries between what the model learns, how it is optimized, and how its final performance is evaluated.
A standard, enterprise-ready split typically includes:
- Training set: The primary learning material (around 70-80% of the dataset), used to teach the model underlying patterns.
- Validation set: A smaller portion (10-15%) used to tune hyperparameters and compare model variants without contaminating the final benchmark.
- Test set: A final, untouched segment (10-15%) reserved exclusively to evaluate performance before deployment.
Once the split is complete, the data undergoes a validation process to assess its consistency, representativeness, and alignment with the intended use case. The procedure includes statistical, schema consistency checks, distribution analyses, and rule-based assessments to confirm whether the dataset meets the quality thresholds defined earlier in the preparation pipeline. Here, gaps often emerge, for example, when certain user groups appear underrepresented or when recent data differs meaningfully from historical records.
To ensure data readiness for AI for long-term production use, the validation step increasingly expands into continuous monitoring. As soon as models move from development to production, datasets evolve, customer behavior changes, systems generate new patterns, regulations shift, and new data sources come online. Without visibility into these shifts, AI systems can degrade quietly, often without clear failure signals.
Read also: Practical guide on AI data integration for streamlined, scaled, and optimized operations
How long does AI data preparation take and what does it demand from your team?
Predictable AI outcomes depend on more than choosing the correct algorithm. They depend on whether the organization can commit the time, expertise, and operational discipline needed to properly prepare the data.
What is the timeline for AI data preparation in an enterprise?
Data preparation consistently consumes 60-80% of the total AI lifecycle, and this rate holds for classical ML and AI implementations. Mature enterprises may move faster, yet even they rarely bypass the underlying constraints: fragmented sources, inconsistent histories, regional variations, and the need to reconcile definitions that have evolved.
Several activities contribute to this extended duration of data preparation for AI:
- Locating and accessing data across fragmented systems;
- Understanding its structure, inconsistencies, and lineage;
- Reconciling incompatible schemas and definitions;
- Cleaning, repairing, and validating;
- Engineering features and preparing unstructured content;
- Establishing governance boundaries and quality thresholds.
The determining factor is not data volume. The fundamental drivers are ambiguity, structural inconsistencies, and the number of decisions required to turn disparate records into a coherent dataset. Below is an approximate range for enterprise-grade AI data preparation:
|
Stage of data preparation |
Approximate duration |
|
Data discovery |
1-3 weeks |
|
Data ingestion and metadata capture |
2-6 weeks |
|
Data quality assessment |
2-4 weeks |
|
Data cleaning and normalization |
3-8 weeks |
|
Feature engineering and GenAI/LLM-specific processing |
2-6 weeks |
|
Data governance setup, validation, and readiness checks |
2-4 weeks |
Actual timelines of data preparation for AI depend on the source system's complexity, the availability of domain experts, regulatory constraints, and the scale of the unstructured data involved.
What team structure is needed for AI data preparation?
Data preparation for AI/ML requires cross-functional execution. No single role or department can complete this phase end to end, as it combines engineering, statistics, business knowledge, and governance. A capable team typically includes:
- Data engineers, who design pipelines, resolve schema inconsistencies, and operationalize ingestion and transformation workflows.
- Data scientists, who explore datasets, evaluate distributions, guide feature design, and quantify bias or model risks emerging from the data.
- Domain experts, who provide contextual understanding, validate assumptions, and ensure that features and labels reflect real operational meaning.
- Governance and compliance specialists, who classify sensitive information and define access rules.
- Data and analytics leaders, who align preparation activities with business priorities, scope trade-offs, and manage investment decisions.
How much will data preparation for AI cost?
Organizations often request cost estimates for AI development before the data preparation phase has even begun. In reality, the cost depends heavily on what is discovered during ingestion, profiling, and cleaning. Missing history, fragmented systems, unstructured records, or heavily biased datasets can dramatically change the scope of work.
A reasonable way to frame cost is: the accuracy, reliability, and price of your AI system depend on the condition of the data uncovered during preparation, and this condition cannot be fully assessed in advance.
For that reason, no credible partner can estimate AI development costs accurately without first conducting an initial assessment of data readiness. What can be stated confidently is that investing in robust data preparation prevents rework, reduces model failures in production, and avoids cost escalations caused by unstable or incomplete data.

What are the common challenges of preparing data for AI initiatives?
Every AI roadmap eventually reaches the same inflection point: once real data work begins, assumptions fall away, and the appropriate level of complexity becomes visible. What initially looked like "we already have the data" becomes a sequence of gaps, inconsistencies, and hidden dependencies that reshape timelines, budgets, and even feasibility. Below is a consolidated view of the challenges that consistently surface across enterprise AI initiatives.
Incompleteness of real-world data
Almost every organization assumes its operational data is cleaner than it actually is. That assumption rarely survives the first ingestion run. Raw datasets routinely contain missing attributes, sparsely populated fields, overwritten history, inconsistent encodings, and values that follow internal logic rather than documented standards. These issues do not always break dashboards or BI reports, but they directly affect model learnability, calibration, and resilience.
Fragmentation across systems and lack of unified semantics
Preparing data for AI demands a level of semantic consistency that most organizations have never needed before. Core entities often exist in several systems with incompatible structures and different business rules. This fragmentation creates several challenges: identifying the correct source of truth, reconciling conflicting attributes, and establishing a unified schema that reflects how processes actually work today, not how they were designed years ago.
Complexity of working with unstructured and GenAI-relevant data
Most enterprises already depend on vast amounts of unstructured content. This data represents 70-90% of their total information footprint [5], and almost none of it is AI-ready. The challenge lies in the operational workload: detecting sensitive information, normalizing formats, resolving duplicates, structuring semantic units, generating embeddings, and organizing retrieval structures that minimize hallucination rates.
Manual processes and weak reproducibility
Many data preparation for generative AI activities still relies on manual scripts, legacy transformations, or spreadsheet-driven processes. These methods work for one-off analytics but fail in AI environments where traceability, version control, and reproducibility are non-negotiable.
The challenges intensify when:
- Steps are undocumented or live only in personal notebooks;
- "One-time" preprocessing becomes impossible to reproduce six months later;
- Minor upstream changes break pipelines without clear visibility into the cause.
When AI systems begin informing decisions about pricing, credit risk, fraud, or operations, the lack of reproducibility becomes both a reliability problem and a governance risk. Debugging a model without traceable data lineage can take longer than retraining the model itself.
Evolving requirements and shifting scope
Data preparation is not static. As use cases mature, business rules evolve, and new datasets become available, the original preparation strategy often needs to be revisited. Early iterations tend to surface gaps that are impossible to spot upfront. For example, expanding a model to new geographies reveals missing attributes; adding new product lines exposes historical inconsistencies; extending forecasting horizons shows that temporal granularity is insufficient.

Taken together, these challenges explain why data preparation becomes the most unpredictable and resource-intensive phase of AI delivery. It is where assumptions meet reality, and where uncertainty must be resolved before any meaningful modeling can begin. That is why experienced partners put so much emphasis on discovery, profiling, and governance upfront.
How N-iX helps eliminate risks in AI data preparation
At N-iX, a significant portion of our AI consulting and development work is dedicated to addressing these sources of uncertainty early: profiling data, exposing hidden risks, aligning semantics, and building repeatable, governed preparation pipelines.

Organizations rely on N-iX when they need stable, governed, and production-grade AI-ready pipelines. Our teams combine deep technical expertise with strong domain understanding to resolve uncertainty early, expose hidden risks, and build data foundations that scale across business units and use cases.
- Over 60 AI and Data Science projects delivered, including complex multi-source and regulated data ecosystems;
- More than 200 AI, ML, and data engineering specialists with experience in implementing classical ML, LLMs, and GenAI systems;
- More than 400 certified cloud specialists with expertise in AWS, Azure, GCP, Snowflake, Databricks, and Microsoft Fabric;
- Over 23 years of experience designing enterprise data platforms, pipelines, and operational analytics;
- Trusted by Fortune 500 and global enterprises who rely on N-iX to build and scale their AI and data foundations;
- Proven capability in LLM-ready data pipelines, including chunking, embedding strategy, vector storage design, and retrieval optimization.
FAQ
Can we start building AI models before data preparation?
It is possible to prototype a model before preparing the data, but an AI system intended for production will most likely fail without a structured preparation phase. Most hidden issues surface only when the real data is inspected, not when a model is tested on a curated sample. Skipping preparation does not shorten the project; it only shifts the risk into later stages, where fixes are more expensive and timelines harder to control.
How much data do we actually need to train an AI model?
The required volume depends entirely on the use case, the stability of the patterns you're trying to predict, and how representative the available history is. Well-prepared, diverse data often outperforms large volumes of raw or noisy data, and for many structured use cases, thoughtful feature design matters more than scale.
How does data preparation contribute to the performance of AI applications?
Most of a model's eventual performance is determined before any training begins, during the steps that clean, structure, and contextualize the data. Thorough preparation reduces noise, avoids leakage, handles imbalanced populations, and eliminates contradictions that would otherwise mislead the algorithm.
Can we reuse the same dataset for multiple AI use cases?
A well-prepared dataset can support several initiatives, but each new use case still requires a tailored view of the data. Targets, time windows, privacy constraints, and performance thresholds differ, so the same dataset rarely works "as is." Reuse becomes practical only when lineage, context, and versioning are in place; without that foundation, teams often discover too late that what worked for one model does not meet the requirements of another.
Can AI or GenAI automate data preparation?
AI-driven tooling can significantly accelerate tasks such as anomaly detection, code generation, text chunking, and embedding creation, reducing manual effort and shortening preparation cycles. However, automation cannot replace decisions about business context, acceptable risk, privacy boundaries, or what "fit for purpose" means for a given model.
References
- A journey guide to deliver AI success through AI-ready data - Gartner
- How to evaluate AI data readiness - Gartner
- Data preprocessing for AI models - Scott John and James Chris
- CIO guide to AI-ready data - Gartner
Have a question?
Speak to an expert


