
Enterprise data management is in transition. Organizations are overwhelmed with data yet lack actionable insights. They grapple with fragmented tools while AI demands integrated infrastructure. The gap between data goals and reality is widening.
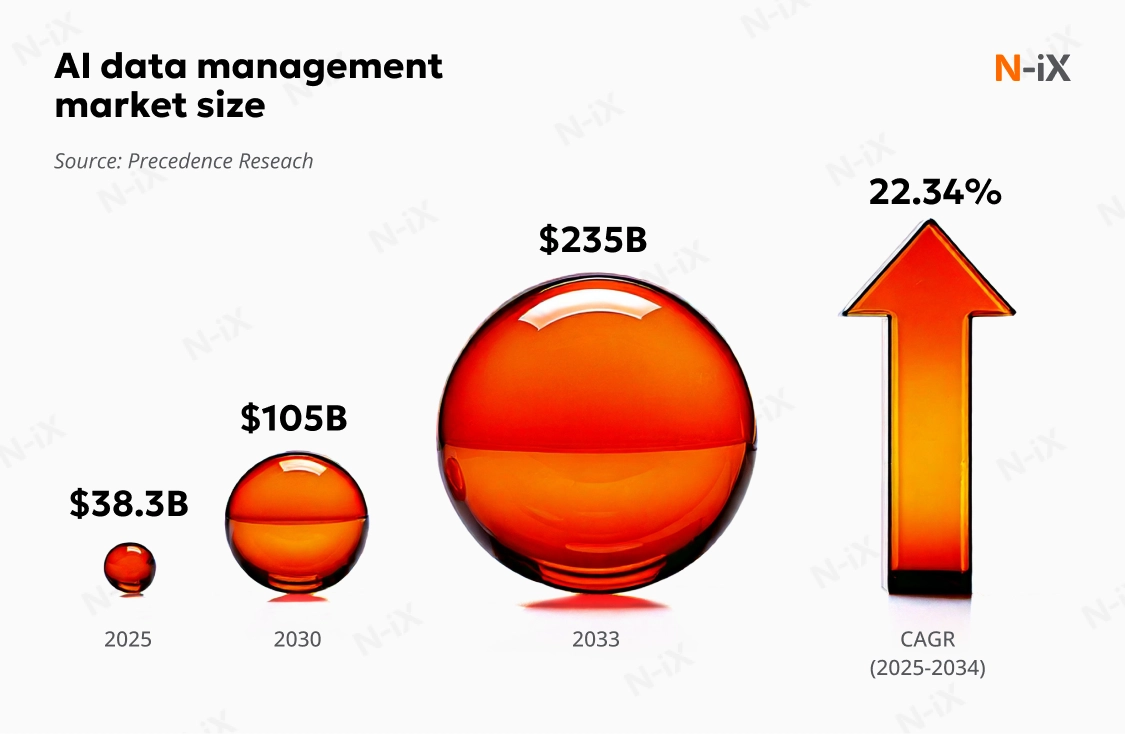
Despite 57% of organizations reporting their data isn't AI-ready (Gartner), global data and analytics spending will approach $420B by 2026 (IDC). Gartner also forecasts that by 2027, automation will transform data management: 60% of tasks will be automated, and 75% of new data flows will come from non-technical users.
We've identified 11 key trends for your enterprise data strategy in 2026. These trends signal a shift from manual to automated, centralized to federated, and reactive to intelligent data management. Embracing these changes will turn your data into a competitive asset. So, let's dive in.
Data management trends reshaping 2026
The 11 data management trends in this article fall into three groups. Five foundational trends define what to build. Four strategic enablers (platform consolidation, interoperability standards, specialized databases, and formal data contracts) determine implementation speed. Two emerging trends, augmented FinOps and data fabric, give early adopters future advantages.
1. AI-ready data: The foundation of enterprise AI success
Data readiness is the main factor contributing to the gap between AI ambition and AI achievement. According to Gartner's 2024 research, over half of organizations report that their data is not AI-ready. Data availability and quality remain the number one barrier to successful AI implementation.
AI-ready data goes far beyond traditional data quality. It requires proving fitness for specific AI use cases through three critical dimensions:
- Representativeness: Does the data align with the use case?
- Continuous qualification: Can you prove data fitness at scale?
- Robust AI governance: Are you managing bias, drift, and compliance?
Generative AI presents a dual challenge. Organizations are racing to implement GenAI across operations, while GenAI itself relies heavily on pretrained models from vendors. This, in turn, makes data the primary source of differentiation and competitive advantage. Organizations without AI-ready data practices face project setbacks, erroneous results, compliance violations, and biased outcomes.
Build a unified, AI-driven data ecosystem—get the white paper!

Success!
What makes data AI-ready in 2026? Of all the trends in data management reshaping enterprise strategy, AI-ready data has moved fastest, accelerating from innovation trigger to peak hype in a year. Forward-thinking organizations are implementing active metadata management, comprehensive data quality frameworks, and continuous observability. They're diversifying data sources to reduce bias, establishing minimum data standards for each use case, and creating feedback loops between data management and AI teams. Most critically, they're breaking down silos between data engineers and AI specialists.
The convergence of augmented data management tools with AI-specific practices creates an innovation cycle. Organizations investing in AI-ready data infrastructure today are positioning themselves to move rapidly from prototype to production, turning AI experiments into business value.

2. Data products and self-service: Democratizing data at scale
The traditional model of centralized data teams struggling to meet endless business requests is breaking. A product-centric approach is emerging that treats data like software: packaged, versioned, documented, and certified for reuse.
A data product differs fundamentally from a dataset. It's an integrated, curated combination of data, metadata, semantics, and implementation logic meeting three criteria. It's consumption-ready and trusted, up-to-date and maintained, and certified for use and governed. Think of it as an API for data: discoverable, documented, and designed for specific business outcomes.
Two forces are accelerating data products: generative AI and self-service. Gartner predicts non-technical users will create 75% of new data integration flows in 2026. This democratization is powered by AI-driven tools that translate natural language into SQL queries, automate data preparation, and provide intelligent recommendations.
The business impact is transformative. Organizations adopting data products report faster analytics delivery. Domain teams focus on outcomes without waiting for IT. Well-designed data products enable reuse at scale, serving multiple analytics projects, Data Science initiatives, and data monetization opportunities. Among the data management latest trends, this shift toward productized, self-service data models enables enterprises to scale insights, reduce operational bottlenecks, and accelerate AI adoption.
However, this approach requires new operating models, data product managers who bridge business and engineering, and DataOps practices. Organizations must be selective: not every dataset should become a product. Prioritize established, repeatable business challenges where scale and reuse justify the investment.
3. Lakehouse architecture: The unified analytics platform
The lakehouse architecture combines a data lake's semantic flexibility and raw data storage with a data warehouse's production optimization and query performance in a single platform. Based on client success across diverse use cases, Gartner has upgraded lakehouse from "high-benefit" to "transformational."
The technical foundation is the rapid adoption of open table formats like Apache Iceberg, Delta Lake, and Hudi. These formats create logical table structures around structured, semi-structured, and unstructured data while maintaining ACID transaction guarantees on low-cost object storage. Organizations can support SQL-based analytics, Python/Spark data engineering, and Machine Learning workloads on the same data without costly replication.
Why does this matter for business? As one of the top trends in data management, lakehouse architecture is accelerating cloud analytics modernization. Organizations are consolidating fragmented data infrastructure, reducing technical debt, and cutting operational overhead while maintaining service levels. Lakehouses are essential for generative AI projects requiring unified structured enterprise data with unstructured content like documents, images, and logs.
All major cloud providers (AWS, Google Cloud, Microsoft Azure) and leading vendors like Databricks and Snowflake support lakehouse platforms. This industry alignment signals genuine market transformation.
The productivity gains are measurable. Development teams iterate faster with unified exploratory and production environments. Data scientists access the same datasets as business analysts, eliminating version control issues. Organizations achieve the "holy grail" of analytics: supporting batch and streaming workloads, historical and real-time analysis, reporting, and AI-without moving data.
For organizations beginning their cloud journey or modernizing legacy data warehouses, lakehouse architecture has become the default starting point for 2026 and beyond.
Read more: Data management strategy 101: A guide to unlocking business efficiency
4. Data observability and DataOps: From reactive to proactive
Data pipeline issues happen. The key is detecting and resolving them quickly to minimize business impact. This reality drives rapid adoption of data observability and DataOps practices, representing the latest trends in data management. Gartner predicts that 60% of data management tasks will be automated by 2027.
Data observability provides a multidimensional view of data health, continuously monitoring pipelines, data quality, infrastructure performance, and usage patterns. Unlike traditional monitoring that only alerts on known issues, modern observability platforms use AI and Machine Learning to detect anomalies, predict failures, and provide actionable remediation recommendations. They answer critical questions: Is the data complete? Arriving on time? Has the schema changed unexpectedly? Are there quality issues impacting downstream consumers?
DataOps complements observability by bringing software engineering discipline to data delivery, applying Agile methodologies, CI/CD, automated testing, and version control to data pipelines. Together, they create a closed loop: detect issues automatically, assess business impact through lineage analysis, and deploy fixes rapidly through automated release pipelines.
The business case is compelling. Organizations implementing these practices report dramatic reductions in data downtime, faster resolution of quality issues, and improved trust in data-driven decisions. They're shifting from firefighting mode (where data engineers spend 80% of time troubleshooting) to innovation mode.
The AI imperative is accelerating adoption. AI models are particularly sensitive to data drift, schema changes, and quality degradation. Data observability provides continuous validation required to ensure AI readiness and maintain model accuracy in production. For 2026, leading organizations are embedding observability and DataOps as foundational requirements rather than operational afterthoughts.

5. Augmented data management: The AI-human partnership
The most profound shift in data management trends isn't about replacing humans but assisting them. Augmented data management (ADM) uses AI and Machine Learning to enhance every aspect of data work, from metadata tagging and schema generation to query optimization and pipeline recommendations. According to Gartner, 71% of organizations plan to invest in data management technologies embedding generative AI in the next two to three years.
This isn't a single technology; it's a wave of innovation transforming the entire data management stack. Natural language interfaces allow business users to ask questions in plain English and receive SQL queries, visualizations, or insights. AI-powered data catalogs automatically classify sensitive data, infer relationships, and suggest relevant datasets. Data integration platforms recommend pipeline designs, and quality tools predict issues before they occur.
The impact on productivity is substantial. Tasks that previously required specialized skills, such as writing complex SQL, designing schemas, mapping data lineage, or profiling datasets, are being automated or assisted by AI. This doesn't eliminate the need for data professionals; instead, it elevates their work from repetitive technical tasks to strategic problem-solving.
Generative AI is accelerating this shift. Modern platforms embed large language models enabling conversational interactions with data systems. Data engineers describe what they want to build in natural language, and the system generates code, tests, and documentation. Business users query catalogs using everyday language. Governance policies can be defined conversationally and automatically translated into executable rules.
The result is a fundamentally lower barrier to entry for working with data. In 2026, organizations leveraging augmented data management will support broader self-service, operate more efficiently, and scale their data capabilities without proportionally scaling headcount. This is a critical advantage in a market where skilled data talent remains scarce and expensive.
6. Data management platforms: The consolidation imperative
The average enterprise data stack has grown unmanageable. Dozens of disconnected tools handle integration, quality, cataloging, observability, and governance. Each requires separate maintenance, expertise, and integration effort. This fragmentation is unsustainable, and the market is responding with converged data management platforms that unify these capabilities under a single operational umbrella. As organizations rethink their data ecosystems, platform consolidation has become one of the defining enterprise data management trends, helping leaders reduce complexity and support scalable, AI-ready operations.
Data management platforms represent evolution from "some assembly required" to packaged experiences. They combine metadata management, data integration, governance, orchestration, and observability into cohesive environments serving technical and business users-simplified, unified, and dramatically easier to operate than stitching together point solutions.
Platform consolidation addresses real pain points. Integration complexity, technical debt, and operational overhead consume resources that should fuel innovation. According to Gartner's 2025 CDAO survey, one in two Chief Data and Analytics Officers now considers optimizing the technology landscape a primary responsibility. The urgency stems from AI: supporting AI-ready data while teams struggle with existing SLAs using overlapping tools has created an untenable situation.
The platform approach delivers four tangible benefits: reduced time to market through generative AI augmentation, improved data engineering productivity by eliminating technical overhead, cost savings through simplified footprints, and lowered change management burdens. Platforms also enable federated data management by centralizing metadata, allowing distributed responsibilities without losing control.
However, platforms aren't one-size-fits-all. Organizations must identify their optimal entry point: lakehouse platforms (Databricks, Snowflake), governance platforms (Collibra, Alation), data fabric platforms (Informatica, IBM), or full ecosystems (Microsoft, Salesforce, SAP). The choice depends on current investments, use case priorities, and long-term strategy.
The critical question for 2026: Is this a transient vendor expansion or a final strategic commitment requiring migration? Take three steps: test operational stability before committing, establish FinOps and platform operations disciplines early, and resist introducing new point solutions that undermine consolidation. The platform era is here; fragmentation is becoming a competitive liability.

7. Data contracts: Formalizing the promise
Data products need clear standards and accountability. When a marketing team depends on a customer dataset for daily campaign optimization, or a fraud detection system relies on transaction data for real-time decisions, informal agreements aren't enough. Enter data contracts: formal commitments from data producers to deliver data products adhering to specific structure, format, and quality standards, backed by enforceable service-level agreements.
A data contract is essentially an API specification for data. It explicitly defines what the producer promises (schema, refresh frequency, quality thresholds, governance controls) and what the consumer can expect (availability, performance, support). This transforms how organizations share data internally and externally, reducing integration failures and ensuring reliable downstream consumption.
The timing is perfect. As data products proliferate and organizations adopt federated operating models like data mesh, clear accountability between producers and consumers becomes critical. One of the key future trends in data management, data contracts provide the mechanism to validate agreements, automate testing, and prevent pipeline failures that disrupt operations.
The technical implementation is maturing rapidly. Modern data contracts are machine-readable, version-controlled, and integrated into DataOps workflows. When a producer updates a dataset, automated validation ensures changes don't violate contract terms. If schema drift occurs, consumers are notified before breaking changes hit production. Quality rules, access controls, and governance policies are codified and enforced automatically: a practice called "governance as code."
Organizations adopting data contracts report significant reductions in data-related incidents, faster resolution when issues occur, and improved trust between teams. The contracts create transparency: everyone knows what to expect and who's responsible when expectations aren't met.
However, this requires discipline. Data contracts work best for mission-critical, reusable data flowing between multiple producers and consumers. Overallocating effort for single-team usage or non-critical data wastes resources. Prioritize data products powering critical business processes, supporting multiple use cases, or shared through data marketplaces.
Forward-thinking organizations in 2026 are creating cross-functional teams to define contract terms, partnering with DataOps vendors to automate validation, and treating contracts as living documents that evolve with needs.
8. Open table formats: The interoperability foundation
Beneath the lakehouse shift lies a quiet technical breakthrough reshaping data storage: open table formats. Apache Iceberg, Delta Lake, and Apache Hudi have emerged as the standard abstraction layer allowing organizations to store data once and query it with multiple engines (SQL, Spark, Python, and Machine Learning frameworks) without costly replication or vendor lock-in.
Open table formats create logical table structures and ACID transaction guarantees on top of low-cost object storage. They support change data capture, data versioning, and time travel queries while allowing diverse processing engines to access the same underlying data. This solves a persistent enterprise issue: data proliferation driven by tool incompatibility.
The industry alignment is notable. AWS, Google Cloud, and Microsoft Azure have all integrated open table formats deeply into their data platforms. Leading technology companies including Apple, Netflix, and LinkedIn are contributing to development. Among all data management trends for 2026, this level of convergence is rare and signals genuine market transformation.
The business benefits extend beyond cost savings. Open table formats accelerate innovation by allowing teams to experiment with new tools without migrating data. They reduce vendor dependencies, providing insurance against platform changes or pricing increases. For organizations concerned about cloud lock-in, open formats offer a mitigation strategy: data stored in Iceberg or Delta Lake can be accessed by any compatible engine.
However, there are caveats. Not all vendors implement standards identically or maintain version parity, creating potential interoperability gaps. While table formats promise portability, vendor lock-in may shift to catalog and governance layers. Security models also require reassessment to accommodate multiple engines accessing storage directly.
Best practices for 2026: Use open table formats within bounded ecosystems led by a single vendor (typically the technical data catalog provider). Prioritize them for data engineering pipeline modernization and Data Science projects where flexibility matters most. Test portability scenarios continuously rather than discovering incompatibilities during emergencies. And evaluate catalogs for their ability to interoperate using open table format metadata-an inability here undermines the flexibility open formats promise.
The bottom line: Open table formats are strategic enablers, not just technical layers. They power lakehouse architectures, multi-engine analytics, and genuine flexibility in a complex data landscape.
9. Vector databases: The GenAI infrastructure layer
Every generative AI application needs memory. Vector databases provide this memory by storing numerical representations (embeddings) of text, images, and other content. They enable three key capabilities: grounding AI models with company knowledge, retrieving relevant context for prompts, and enabling semantic search that understands meaning, not just keywords.
Here's how it works: Content is converted into high-dimensional vectors where similar items cluster together mathematically. These vectors are stored in databases optimized for fast similarity search. When users query a GenAI system, the vector database retrieves relevant company data to feed the language model, a pattern called Retrieval-Augmented Generation (RAG).
RAG has become the standard approach for enterprise GenAI. It solves key problems with language models: hallucinations, outdated information, and lack of company-specific knowledge. By grounding responses in actual company data, RAG development services improve accuracy without expensive model retraining. Advanced approaches like GraphRAG combine vectors with knowledge graphs for even better results.
The market has responded with growth. Purpose-built databases like Pinecone and Weaviate gained rapid adoption, while established vendors (AWS, Google, Microsoft, MongoDB) added vector capabilities to existing platforms. This raises a key question: Do you need a specialized vector database, or will vector support in your current infrastructure work?
The answer depends on scale and complexity. High-traffic applications serving thousands of simultaneous users benefit from purpose-built performance. Smaller experiments may work fine with vector capabilities in PostgreSQL (pgvector) or MongoDB Atlas.
Key considerations for 2026: Prioritize developer experience and ecosystem integration. GenAI evolves rapidly, making vendor lock-in risky. Test multiple options through pilot projects-vendor benchmarks may not match your real-world patterns. Invest in understanding RAG architecture, including chunking strategies, embedding models, and hybrid search techniques. Vector databases aren't just infrastructure; they're the bridge connecting your company's knowledge with AI's transformative potential.
10. Augmented FinOps: Intelligent cloud cost optimization
Cloud data infrastructure offers flexibility and scale, but costs can spiral unpredictably. Organizations migrating analytics, AI, and data workloads to the cloud discover that knowing costs isn't the same as controlling them. Augmented FinOps uses AI to optimize cloud spending to meet business goals, shifting from reactive expense tracking to proactive value engineering.
Traditional FinOps focuses on visibility and chargeback: showing who spent what and when. Augmented FinOps goes further: AI predicts consumption patterns and automatically adjusts resources to match workload demands, optimizing price-performance across your data ecosystem. Imagine expressing objectives in natural language like "minimize latency for customer queries while keeping monthly costs under $50,000," and having the system automatically tune infrastructure to achieve those goals.
The business imperative is intensifying. Rapidly changing cloud costs require automated controls that human teams can't match. The programmability and granular cost-tracking data that cloud environments produce make augmented FinOps essential. Organizations must demonstrate ROI through efficient resource utilization or risk budget cuts and migration reversals.
The challenge extends beyond simple cost reduction. Modern data ecosystems span multiple services (warehouses, lakehouses, integration platforms, observability tools, and AI/ML services) each with different pricing models. Correlating technical costs with business results through unit economics (cost per customer, transaction, or prediction) requires sophisticated analysis that manual approaches can't deliver at scale.
Critical obstacles remain. Cloud provider pricing models are complex and constantly evolving. Standards like the FinOps Foundation's FOCUS specification are in early adoption, and APIs for cross-platform performance data haven't fully matured. Most importantly, augmented FinOps requires transparency and accountability. Organizations must track recommendations, measure results, and build trust over time.
For 2026, leading organizations seek offerings that automate performance, consumption, and pricing optimization through AI/ML. They regularly verify these capabilities deliver results, applying maturity models to assess vendors' ability to observe, report, recommend, predict, and optimize. Organizations use multiple tools rather than a single solution-some offer broad coverage with shallow optimization, others provide deep, specialized capabilities.
Though still emerging, augmented FinOps is transformational. As data workloads consume larger cloud budgets and AI training costs escalate, algorithmic financial optimization shifts from a competitive advantage to a requirement. Positioned among the most impactful emerging trends in data management, augmented FinOps enables leaders to move from reactive cost control to strategic value optimization.
11. Data fabric: The intelligent orchestration layer
Most organizations accumulate tools until their technology stack resembles a tangled web of integrations. Data fabric takes a different approach: it adds an intelligent layer over existing systems that observes infrastructure, learns patterns, and recommends optimal data access paths without replacing what you have. It's among the most important data management industry trends.
Data fabric is a design pattern, not a product. It uses metadata analysis, knowledge graphs, and Machine Learning to automate data management. The core principle is "observe and leverage" rather than "build to suit." Instead of manually designing every integration, data fabric analyzes where data lives, how it's used, and what transformations are needed. Then it intelligently orchestrates access through the most efficient method: virtualization, replication, APIs, streaming, or batch processing.
The business value is significant. Data fabric provides intelligent orchestration without always recommending system replacement. It capitalizes on existing investments, prioritizes where fresh spending matters, and reduces maintenance burdens. For engineers, it automates repeatable tasks while adding semantic context.
The technical foundation requires mature metadata management: the biggest adoption obstacle. Data fabric needs comprehensive, high-quality metadata across all systems, plus knowledge graphs and Machine Learning algorithms. Organizations with weak metadata practices will struggle regardless of vendor promises.
The AI connection is accelerating adoption. GenAI applications need comprehensive data access, lineage tracking, and semantic understanding-all provided by fabric architectures. Data fabric, data ecosystems, and AI-ready data form a reinforcing flywheel.
However, vendors use differing metadata standards, undermining fabric principles. Cultural change is equally challenging: organizations must shift from "design then build" to "observe and leverage" methodologies, fundamentally rethinking how initiatives are staffed and executed.
Practical steps for 2026: Build metadata management practices where tools share metadata bidirectionally. Invest in augmented data catalogs supporting multiple ontologies. Prioritize knowledge graphs in domains with mature metadata. Use integration platforms that consume fabric insights across multiple modes. Make data fabric the foundation for data product creation and federated data mesh models.
Data fabric represents a five-to-ten-year journey, but incremental benefits accrue immediately. Organizations starting today are positioning themselves for intelligent, automated orchestration at scale.
From exploring trends to taking action
The data management trends outlined here signal a major shift in how organizations handle data. AI-ready data, data products, lakehouse architecture, observability, and augmented management are becoming baseline requirements. Organizations adopting these data management trends early report faster insights and lower costs. Four strategic enablers determine your implementation speed: platform consolidation, data contracts, open table formats, and vector databases. Emerging trends like augmented FinOps and data fabric offer early advantages.
Your starting point depends on your current state. If you're modernizing legacy systems, focus on infrastructure and observability first. If you're struggling with slow delivery, prioritize data products and self-service. If you're scaling AI, invest in making your data AI-ready.
The window for strategic advantage is closing. Organizations that implement these data management trends in 2026 will set the competitive baseline for the next decade, those that delay will spend years catching up. Assess your current data maturity, identify your biggest gap, and start implementing today.
Have a question?
Speak to an expert

