
What happens when autonomous AI agents start making decisions across your enterprise, but you can't clearly see how or why those decisions were made? You may notice subtle inconsistencies: an answer that contradicts previous logic, a tool invoked without reason, or a workflow that suddenly behaves differently from the day before. At a small scale, these moments feel like minor anomalies.
Unlike traditional ML models or even LLM-based assistants, agents don't simply take an input and generate an output. They plan multi-step tasks, retrieve and modify information, call external systems, and adjust their behavior based on outcomes. This is the core promise of AI agent development: building systems capable of independently completing complex workflows, but it also introduces far more opacity into how decisions are formed. And because so much of this happens outside the immediate view of engineering or business teams, it becomes difficult to answer basic but critical questions:
- Why did the agent choose this path and not another one?
- Which tools did it call along the way?
- Did it comply with and follow access rules?
- Is its behavior consistent or drifting over time?
- What drove an unexpected cost increase?
When these questions can't be answered, it's because the organization lacks the visibility to manage it responsibly. AI agent observability provides structured insight into how agents operate: their reasoning summaries, action sequences, memory, adherence to guardrails, and the performance and cost patterns that emerge from their decisions.
In the sections ahead, we'll look closely at what observability must include, why traditional ML/LLM monitoring falls short, and how enterprises can build an approach that ensures AI agents operate predictably and responsibly in real-world environments.
What is AI agent observability?
AI agent observability is the practice of monitoring and understanding the full set of behaviors an autonomous agent performs, from the initial request it receives to every reasoning step, tool call, memory reference, and decision it makes along the way. It extends the broader field of observability, which relies on telemetry data such as metrics, events, logs, and traces (MELT). It applies those principles to agentic systems that operate through multi-step, dynamic workflows rather than deterministic code paths.
At the forefront of AI agent observability is the ability to answer a set of essential questions:
- Is the agent producing accurate responses based on the available data?
- Are reasoning steps or tool calls creating unnecessary latency or cost?
- Is the agent selecting external tools appropriately and executing them reliably?
- When a failure occurs, what sequence of events led to it?
- Is the agent respecting governance, ethics, and data protection requirements?
These questions matter because agentic systems don't operate in isolation. They interact with LLMs, APIs, enterprise databases, operational tools, and user-facing applications. Each interaction creates the potential for variability or error, especially when reasoning, memory, or tool conditions shift over time.
A concrete example illustrates this concept. Consider an online retailer facing a sudden surge in negative feedback for an AI agent assisting customers with product inquiries. The observability dashboard reveals the trend, prompting a deeper investigation. Reviewing the agent's logs shows that the agent relies on a specific database tool called to fetch product details. However, the responses include outdated or incorrect information. A trace of the agent's execution path highlights the exact step where it retrieved obsolete data, and further inspection pinpoints the underlying dataset that had not been refreshed.
With this visibility, the retailer updates or removes the faulty dataset and adds a validation step to the agent's workflow. Once corrected, the agent resumes providing accurate, reliable answers, and customer satisfaction improves.
Read more: AI observability tools overview
Explore high-impact AI agent use cases—get the guide!

Success!
Why do AI agents need observability?
AI agents require observability because their behavior cannot be fully predicted, constrained, or governed through traditional software development methods. Their autonomy, dependence on LLMs, reliance on external tools, and ability to generate dynamic execution paths introduce new risks and operational uncertainties that organizations must proactively manage.
In short, AI agents need observability because:
- You cannot govern what you cannot see.
- You cannot fix what you cannot reproduce.
- You cannot trust what you cannot verify.
- You cannot optimize what you cannot measure.

The following sections explain why observability is indispensable by addressing the operational, technical, and governance challenges that arise once agents begin executing real workflows.
1. Non-deterministic behavior requires continuous visibility
AI agents behave differently from deterministic applications. For any given input, an agent may generate multiple plausible reasoning paths, select different tools, or pursue alternative plans. This variability is inherent to probabilistic models and cannot be eliminated through parameter tuning.
Observability is required because teams need to understand when variability is intentional and when it indicates a flaw.
Agents often take different execution paths for the same request; without visibility, it is impossible to determine whether the divergence is benign or harmful. Slight phrasing changes, ambiguous user instructions, or variations in retrieved memory can produce materially different decisions. Even with tightly controlled parameters, LLMs can drift, interpret context inconsistently, or add unnecessary steps.
2. Debugging and troubleshooting require visibility into multi-step reasoning
Traditional debugging methods are insufficient once an agent operates through multi-step workflows involving planning, tool use, memory retrieval, and conditional decision-making. Failures rarely surface as simple errors; they manifest as incorrect reasoning, incomplete tasks, inefficient strategies, or misaligned tool selections.
Observability is needed because root-cause analysis depends on reconstructing the agent’s entire decision process.
Traces reveal the exact step where the agent diverged, whether due to a tool error, a misinterpreted instruction, or an unexpected branch in reasoning. Logs expose the internal transitions that precede failure, including faulty assumptions, stale context, or inappropriate tool parameters. Without an observability trail, teams cannot diagnose why a task went wrong, nor can they replicate conditions to verify fixes.
3. Reliability, safety, and compliance cannot be assured without traceability
As AI agents interact with sensitive data, external systems, and high-impact workflows, organizations must ensure that every action is auditable and compliant. Because agents operate autonomously, oversight cannot depend solely on design-time controls; it must occur continuously and retroactively.
Observability is essential because it provides the accountability layer required by internal governance and regulatory standards.
Traceable actions allow teams to confirm that the agent followed approved policies, respected access constraints, and avoided prohibited operations. Security AI agent monitoring identifies unauthorized tool use, data exposure indicators, or attempts to manipulate the agent's instructions. Sensitive information must be detected and redacted consistently to prevent inadvertent leakage.
4. Continuous improvement and operational optimization depend on telemetry
AI agents evolve as models change, data shifts, user patterns adapt, and new tools are introduced. Their performance, cost efficiency, reasoning reliability, and output quality can improve or deteriorate depending on operational conditions.
Observability is necessary because improvement and optimization depend on feedback loops driven by real-world telemetry.
Performance metrics (latency, throughput, error rates) highlight where reasoning steps or tool calls slow down workflows. Token usage and cost telemetry reveal inefficiencies, excessive retries, or unnecessary expansions of context that inflate the budget. AI agent observability monitoring highlights when an agent fails to follow its intended orchestration, allowing teams to refine prompts, redesign workflows, or update tool logic.
How AI agent observability works
AI agent monitoring operates through several integrated activities: data collection, workflow reconstruction, performance measurement, decision and action logging, and ongoing evaluation of quality and compliance. Together, these activities generate the visibility required to manage autonomous systems at scale.
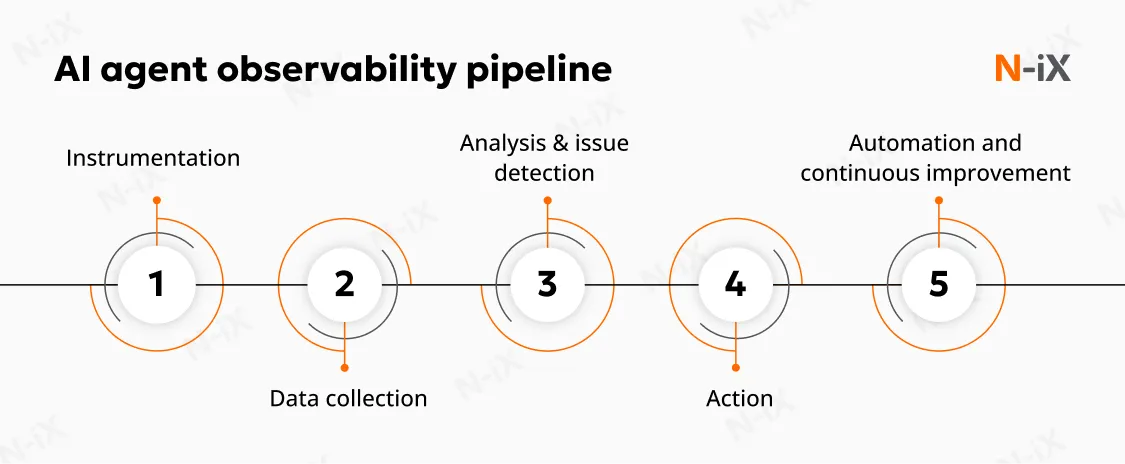
Data collection: capturing the telemetry that describes agent behavior
Observability begins with instrumentation. Every relevant component of the agent emits signals that reflect its internal state and external interactions. This data covers traditional telemetry (metrics, events, logs, traces) as well as signals unique to agentic execution.
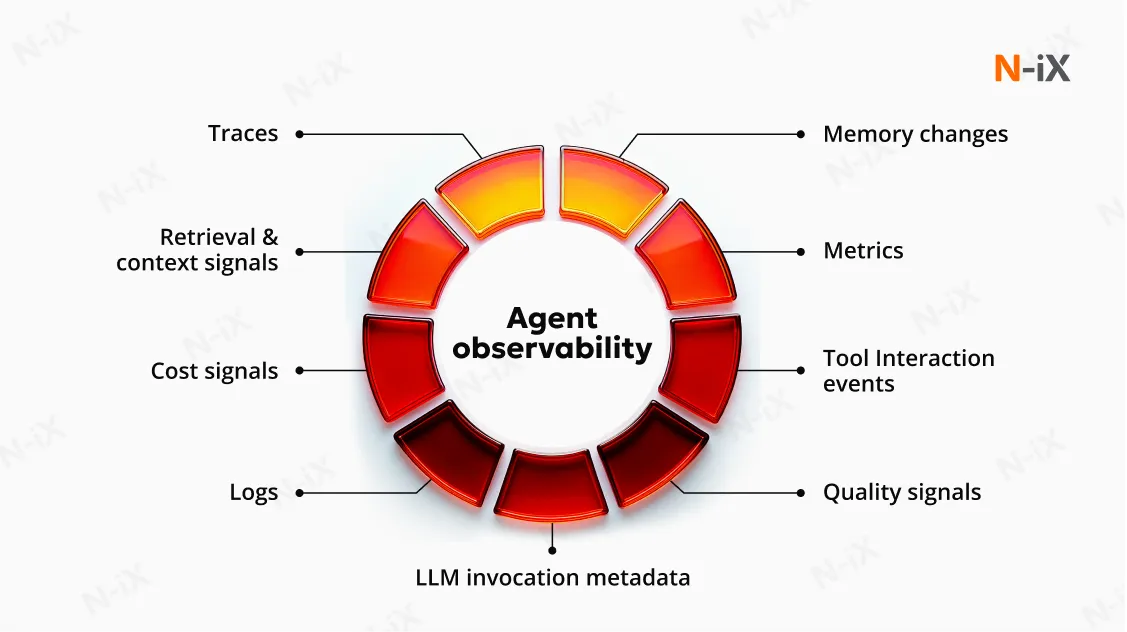
Traces and spans
Traces provide the end-to-end record of how a request was processed. They reveal each stage of reasoning, action, and interaction.
- A trace represents the complete lifecycle of an agent's task: goal interpretation, planning, tool calls, memory lookups, intermediate outputs, and final decision.
- Spans are the granular units within a trace that capture each notable action, such as an LLM invocation, a vector search query, or a system API call.
Collectively, spans form a detailed sequence that allows teams to identify unexpected branching, unnecessary steps, latency sources, or failures that occurred at specific points.
Metrics
Metrics quantify how the agent performs and how efficiently it uses resources. Observability systems typically track:
- Latency patterns: end-to-end response time, per-step latency, and bottlenecks within reasoning loops
- Error rates: failed tool calls, execution retries, LLM invocation failures, and incomplete tasks
- Throughput and concurrency: performance under real workload conditions
- Token consumption: cost drivers from LLM calls, aggregated per agent, per workflow, and per user session
Quality metrics extend beyond correctness to capture the integrity of AI-generated outputs. These may include: hallucination frequency or context deviation, response relevance, tool selection appropriateness, adherence to guardrails, and evidence of behavioral drift.
Logs
Logs supplement traces and metrics by capturing granular events and metadata associated with the agent's decisions. They provide a durable, auditable record of what occurred during execution and are often essential for compliance, risk analysis, or root-cause investigations.
Relevant log categories include:
- Decision-making logs: Record the inputs the agent received, how it interpreted them, and the decisions it produced. These logs often store structured representations of intermediate reasoning summaries, selected actions, and any fallback or correction steps.
- User interaction logs: Document incoming queries, user context, and final responses. These logs support quality evaluation, customer-impact assessments, and the refinement of agent behavior based on real usage.
- Tool execution logs: Capture each tool call, including parameters, execution time, returned results, and any associated warnings or errors. When issues arise, these logs help identify whether the problem originated in the agent's reasoning or in an external system.
Analysis and issue detection
Once telemetry is collected, the next phase of AI agent observability focuses on extracting insight from execution data and identifying behavioral patterns that require intervention. AI observability enables teams to distinguish between normal variability inherent to LLM-driven systems and deviations that signal design flaws, operational risks, or governance failures. Traditional monitoring tools are not equipped to surface these nuances; agentic systems require analytical methods that examine how decisions evolve across entire execution paths.
A core task in this phase is identifying behavioral variability. Because LLM-based agents do not follow fixed logic, their execution paths often differ even when processing similar inputs. Observability systems use advanced analytical techniques to determine whether these variations fall within the expected design envelope or represent unintended drift. One method used for this assessment involves process and causal discovery, which treats execution traces as event logs containing timestamped steps. Teams can detect dependencies between actions, observe where execution paths diverge, and identify points in the workflow where unexpected behaviors emerge.
This agentic AI monitoring analysis makes an important distinction:
- Intended variability, which reflects explicit branching logic or decision-making pathways designed into the agent.
- Unintended variability emerges when the LLM introduces steps, context, or tool calls that were not part of the intended specification.
Observability tools help isolate these "variation points," enabling teams to identify rare or inefficient execution paths. For example, an agent may unnecessarily invoke a tool, repeat an operation, or use a dataset unrelated to the task. These outlier trajectories often highlight opportunities to refine instructions, adjust tool definitions, or introduce guardrails to reduce ambiguity in the agent's reasoning.
In parallel, LLM-based static analysis complements behavioral discovery. This method evaluates the agent's natural language specification, including role definitions, goals, tool descriptions, and operational constraints, against the patterns uncovered in execution data. If a behavior appears consistently across variation points, static analysis helps determine whether the specification is overly vague, implicitly permissive, or missing critical constraints.
When observed behaviors diverge from documented expectations, static analysis helps determine whether the agent's specification is underspecified or ambiguous, the agent requires stricter constraints, tools need better-defined usage rules, or reasoning boundaries must be clarified to reduce unintended variability. Issue detection is integrated into this continuous analytical process. Modern observability platforms monitor for:
- workflow failures and incomplete tasks;
- degraded output quality or low-confidence responses;
- repeated tool errors or inefficient invocation patterns;
- anomalies in performance or cost metrics;
- deviations from compliance and safety policies;
- signals indicating prompt manipulation or unauthorized data access.
These alerts allow teams to address problems early, whether they stem from model behavior, tool reliability, dataset inconsistencies, or the broader application stack. By combining behavioral analysis, specification validation, and automated anomaly detection, agent observability provides a comprehensive mechanism for understanding how agents operate and identifying where corrective action is required.
Action and automation
The final stage of AI agent observability converts insight into operational improvement. With complete execution traces and correlated logs, teams gain a reproducible record of the agent's behavior. This enables precise root-cause analysis by showing the exact moment when behavior diverged from expectations, whether due to an incorrect tool invocation, an incomplete reasoning chain, misinterpreted user intent, or a violation of defined responsibilities. The ability to replay the execution path transforms intermittent or opaque failures into structured, diagnosable scenarios.
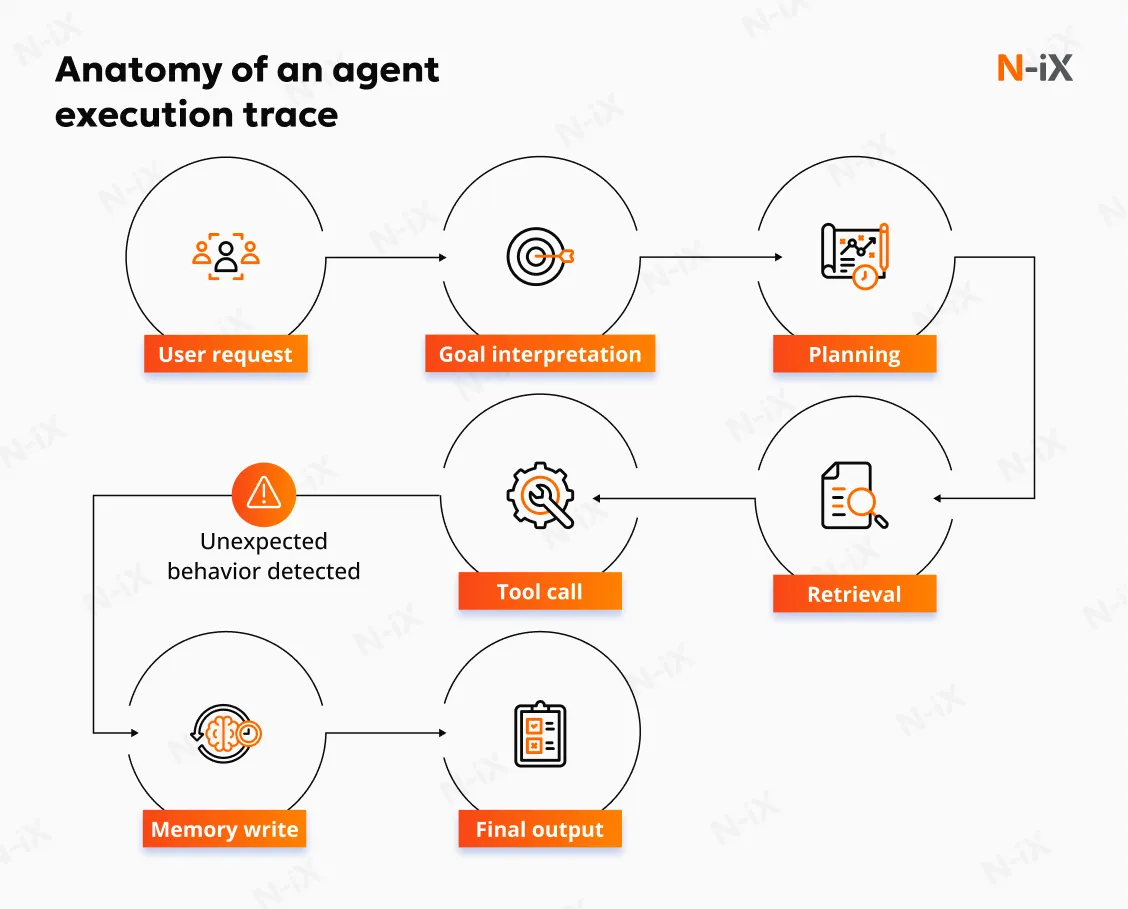
Observability functions as the enforcement layer for governance. Once an agent's actions are transparent, organizations can define and maintain guardrails with confidence. This includes enforcing access controls for tools, APIs, and datasets, applying redaction rules for sensitive or regulated data, and logging all actions for auditability and compliance reporting.
The insights produced during analysis often point to opportunities for refinement. These may encompass the following:
- clarifying prompt structures or role definitions to reduce ambiguity;
- improving task decomposition strategies;
- adjusting reasoning parameters to produce more stable outputs;
- eliminating redundant or inefficient tool calls;
- refining memory usage patterns to improve recall consistency;
- tightening specification boundaries where unintended variability occurs.
Automated operations and adaptive behavior
At advanced stages of observability maturity, organizations can introduce automation to close the loop between detection and correction. When the system identifies a high-confidence pattern, it can automatically adjust the agent's behavior.
Examples are the following:
- modifying prompts or instructions to correct a consistent misunderstanding;
- switching to a more cost-efficient or higher-precision LLM for specific tasks;
- adjusting temperature or other model settings for more stable reasoning;
- rerouting tool calls when a downstream dependency shows degraded performance;
- applying alternative execution plans in response to detected anomalies.
What encompasses AI agent observability?
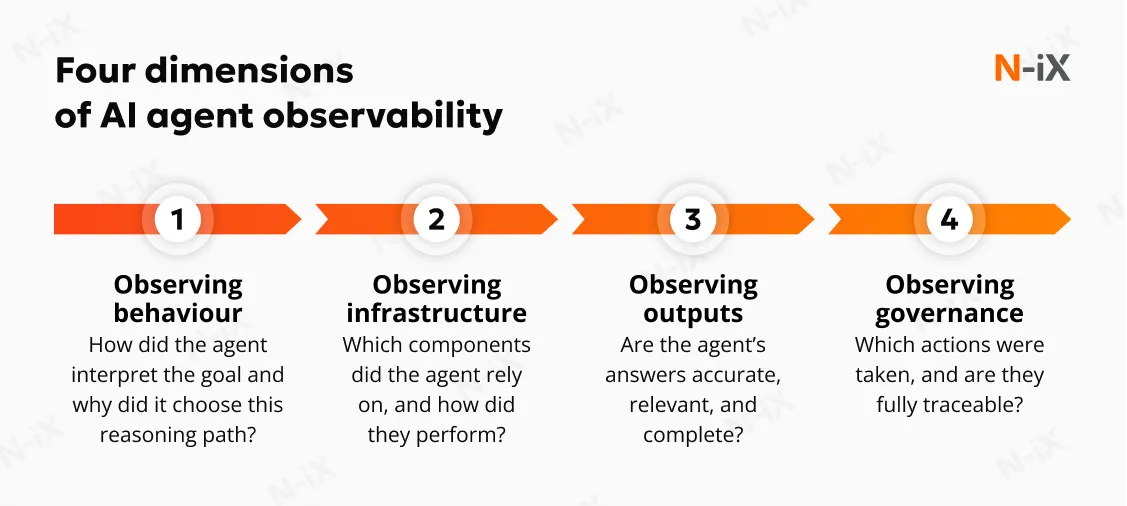
Observing behaviour
Behavioral observability focuses on the internal mechanics of agent reasoning. It reveals how an agent interprets its goals, structures its plans, and navigates alternative decision paths. Because autonomous agents do not follow pre-determined workflows, this visibility is essential for assessing whether behavior aligns with the intended design. It exposes the decision logic behind tool usage, the rationale for branching into different execution paths, and the subtle shifts in reasoning patterns that may indicate drift or unintended variability.
Observing infrastructure
Operational observability examines how the agent interacts with the underlying infrastructure. Autonomous systems rely on multiple components, LLMs, vector databases, orchestration layers, external APIs, and performance issues can emerge at any stage. By capturing latency patterns, throughput characteristics, error propagation, and resource consumption, operational observability enables teams to evaluate how efficiently agents execute tasks and how reliably they respond under fluctuating load. This insight supports capacity planning, cost optimization, and architectural decisions that impact both performance and financial sustainability.
You may also find it interesting to read: Why your business needs AI agent orchestration
Observing outputs
Decision observability connects an agent's technical behavior to its real-world outcomes. It evaluates whether the agent's outputs are accurate, relevant, and compliant with constraints, and whether they are consistent over time. This requires more than checking functional correctness; it involves assessing whether the agent applied appropriate reasoning, adhered to domain rules, and avoided hallucinations or misinterpretations that compromise trust.
AI evaluation and observability frameworks expand on this by benchmarking outputs against defined quality and policy criteria, creating a systematic approach for identifying performance degradation, improving prompt structures, and updating model configurations.
Observing governance
Governance provides the oversight required to deploy autonomous agents in environments where accuracy, safety, and compliance are non-negotiable. Observability supports governance by offering traceability of every decision, tool invocation, and data interaction, enabling organizations to demonstrate accountability and adherence to internal and regulatory requirements. It helps detect unauthorized actions, enforce access controls, and monitor the handling of sensitive data.
|
Observability layer |
What it captures |
Why it matters |
|
Behavioral observability |
Reasoning paths planning, branching logic, tool decisions, memory use. |
Shows how the agent interpreted instructions, why it made certain decisions, and whether reasoning is drifting or becoming unstable. |
|
Operational observability |
Latency, throughput, failures, model performance, dependency behavior. |
Ensures reliability and cost-efficiency across LLMs, vector stores, APIs, and orchestration layers. |
|
Decision/ output observability |
Quality, correctness, completeness, context adherence, instruction following. |
Validates that decisions are grounded, safe, and aligned with business rules and domain constraints. |
|
Governance observability |
Auditability, access control enforcement, PII redaction, safety violations. |
Provides traceability and compliance visibility necessary for enterprise deployment and regulated environments. |
Best practices for AI agent observation
Done well, AI observability becomes less a set of dashboards and more an operating discipline: you know how your agents behave, where they fail, what they cost, and whether they can be trusted in production.
The biggest misconception about AI agents is that reliability comes from better prompts or bigger models. In reality, reliability comes from observability.

At N-iX, we treat observability as a first-class requirement of AI agent development. The AI agent observability best practices below reflect how we design, implement, and operate for non-deterministic, agentic systems.
Standardize telemetry and instrumentation from the outset
High-quality AgentOps observability for AI agents starts with predictable telemetry. We standardize how agents, LLMs, tools, and supporting services emit metrics, logs, and traces, typically using OpenTelemetry with GenAI/agentic semantic conventions as the backbone. That means every agent we build is instrumented to emit consistent signals for: when a task starts and ends, which reasoning steps were executed, which tools were invoked, which data sources were queried, and which guardrails were triggered.
Instead of relying on ad-hoc logging buried in business logic, we embed instrumentation hooks into the agent orchestration layer and shared libraries. End-to-end traces then allow us to reconstruct an entire interaction as a single narrative: from user request, through planning and retrieval, to tool calls and final response. When something goes wrong, we can replay that exact trajectory and see precisely where it diverged from the intended design.
Focus on behavioral and decision observability
Traditional monitoring answers whether the system is "up." Agent observability must answer whether the system is behaving as intended. We routinely analyze execution trajectories to identify where behavior branches and whether those branches are expected. Techniques such as process and causal discovery help us reconstruct the actual workflows agents follow in production and highlight split points that represent new or unstable behavior. When we observe unexpected trajectories, we pair this with LLM-based static analysis of the agent specification to determine whether the instructions are too loose, conflicting, or incomplete.
Alongside this, we continuously monitor decision quality: correctness against known truth, adherence to retrieved context, instruction-following, safety and tone, and proper use of tools. These signals are not collected as vanity metrics; they inform concrete decisions about prompt redesign, tool gating, retrieval logic, or even whether a given model remains appropriate for a given task.
Embed observability throughout the development lifecycle
For agents, "test once and deploy" is not viable. We integrate observability into the whole lifecycle, so behavioral issues are caught early and revisited regularly. We use evaluation suites that include deterministic tests, scenario-based flows, and LLM-as-a-judge scoring to detect regressions in reasoning, quality, and safety. When an anomaly appears in staging, we already have the observability in agentic AI data to see whether it reflects a localized issue or a systemic shift in behavior.
We also treat drift monitoring as part of this lifecycle. Over time, we compare current behavior against baselines: response patterns, error profiles, tool usage, cost per task, and quality scores. When we see variance beyond defined thresholds, it triggers targeted investigation before the drift manifests as user-visible failures.
Use observability to manage efficiency and cost deliberately
We monitor token usage per agent, per workflow, and per request; we correlate it with latency, success rates, and quality metrics to understand which patterns are genuinely valuable and which are wasteful. Where appropriate, we route agent traffic through AI gateways that centralize enforcement and telemetry. Agentic AI observability provides a single layer for observing model selection, tracking per-model and per-tenant spend, and applying policies such as capping specific usage patterns, switching to cheaper models for low-risk tasks, or throttling problematic workflows.
Beyond LLM cost control, we also assess context engineering and the behavior of reference data. Many agent failures stem not from model weaknesses but from outdated, incomplete, or inconsistent context. By tracking which context sources were used, how often they are refreshed, and how retrieval quality impacts reasoning, observability becomes a guiding mechanism for maintaining knowledge accuracy.
Build or scale autonomous agents and need an observability layer that can withstand real-world production complexity. N-iX can help design the instrumentation, evaluation pipelines, and governance controls required to operate these systems with confidence. Our engineers have deep experience implementing telemetry, tracing, and evaluation frameworks for agentic architectures.

Extended perspective: Observability in multi-agent systems
Observability in multi-agent systems (MAS) takes on a different dimension once several autonomous agents begin reasoning, exchanging context, and coordinating their decisions simultaneously. With unified tracing and standardized telemetry, teams can reconstruct the full logic chain: which agent initiated the workflow, how tasks were decomposed, why delegation decisions were made, and where an interpretation drifted just enough to cause an unexpected result.
As soon as autonomy is distributed across several agents, governance and control become inseparable from observability. MAS introduces new classes of failures that don't appear in single-agent systems, coordination breakdowns, conflicting tool usage, agents overrunning their assigned roles, and subtle behavioral patterns that only emerge when agents respond to each other rather than to a user. Observability serves as the early-warning system for all of this, revealing where decision boundaries are slipping or responsibility lines are being crossed.
FAQ
How is AI agent observability different from traditional software monitoring?
Traditional monitoring focuses on system health and performance, while AI agent monitoring observability must also explain autonomous decision-making, reasoning paths, and tool usage. Because agents behave non-deterministically, observability must surface why a particular action occurred.
Do all AI agents require observability, even in small deployments?
Yes, because non-deterministic decisions can lead to unexpected outcomes even at a minimal scale. Early observability provides the clarity needed to detect misalignment, drifting behavior, or misuse of tools before these issues reach production workflows.
What are the first indicators that an agent needs better observability?
Early warning signs often include inconsistent answers, unexplained cost spikes, latent tool failures, or difficulty reproducing user-reported issues. These symptoms usually reflect hidden variability inside the agent's reasoning or data retrieval process.
Can observability reduce the operational cost of running AI agents?
Yes. Detailed telemetry on reasoning depth, token consumption, and tool selection helps teams identify unnecessary steps that inflate costs. With these insights, organizations can optimize prompts, restructure workflows, or direct traffic to more efficient models without sacrificing quality.
References
- Redesign Observability With Business and AI Context - Gartner
- Critical Capabilities for Observability Platforms - Gartner
- AI Agents in Action: Foundations for Evaluation and Governance - Capgemini
Have a question?
Speak to an expert


