
Processing a large amount of data in the Big Data world has become routine. Many companies offer common Big Data ETL solutions using Hadoop utilities, which have become popular and widely adopted. These solutions often involve data extraction (structured or unstructured), transformation into a user-required form (typically structured tables), and loading into accessible storage for end-users. To better understand and leverage these complex processes, delving into enterprise big data solutions can provide invaluable insights and expertise. This approach is pivotal for most current big data projects.
So here we will show you a brief description of how to work with it.
Back-End – What is under the hood?
Geo-Storage
Where do we store the geo-data? To answer this question, we need to ask “What do we want to get in the end?” We want to store the data somewhere and somehow. You can say, “Why don’t we use RDBS?” and that’s a good question. The answer to this question could be “yes”, but following a certain condition. What we’re trying to state here is that this approach is fine in case your data has a predefined schema and it’s not growing fast. Sounds good. But let’s say you want to have a possibility to work directly with geodata and all necessary tools for it. Or even more, let’s assume we have a real-time data processor pipeline which sends us an endless amount of schema-less data. Will the RDBMS be enough?
The most common way to store and process geo-data is to use NoSQL, which already has a good build on-top engine to store, process and transform geodata, similar to Accumulo or HBase for storing with GeoMesa.
Hello GeoMesa
As it’s been mentioned before, GeoMesa is one of the biggest and most popular on-top of the NoSQL DB engines, which gives the possibility of geospatial querying and performing analytics. GeoMesa includes a large number of functions for working with geodata, supporting common geo-types in the WKT format (see next chapter). Also, it implements command-line tools with various commands and provides API for Java language as well as Big Data tools, for example, Spark, which simplifies its interaction with a developer.
Geo-Types
The geodata domain presupposes a specific way of storing data, i.e. the “Well-Known Text” (WKT). In the context of the raw theory, WKT is a text markup language for the representation of geometric objects on a map, spatial reference system, etc. Briefly, this is a unified way of creating Points, Lines, Polygons, Multi-polygons, etc. from Integers, Decimals, Strings.
Here is how it should look like in examples:
 These data types are common for all geo engines.
These data types are common for all geo engines.
Front-End – Visualization engine
GeoServer as a geospatial view engine
So, now we have data stored in the proper way. However, how can we use this data for visualization? The simplest way to do that is to use GeoServer – a software server designed specifically for creating maps, viewing them, editing geospatial data or simply querying it with one of the geospatial standard languages. Let’s consider it in a broader context now.
GeoServer (as GeoMesa) uses CQL (Common Query Language) for querying data. It is a very simple matter for people who know SQL as far as their syntaxes are rather similar except for some limitations.
Moreover, GeoServer still does not run out of possibilities. It also has the implementations of geospatial protocols as for instance:
- WFS (Web Map Service) – by users request it generates map images from geospatial data as a response. For example, let’s look closely at some analytics on cell phone usage in the USA. The next picture is made from GeoServer with “Layer Preview” tool:
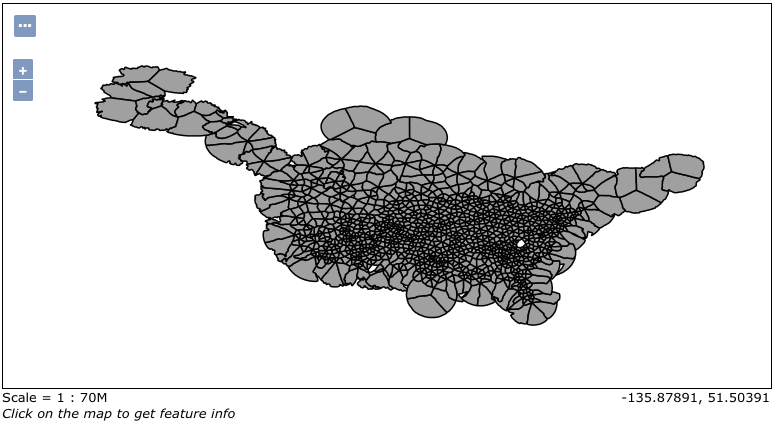
Going further, we can add style and put it as a separate layer on some map UI:

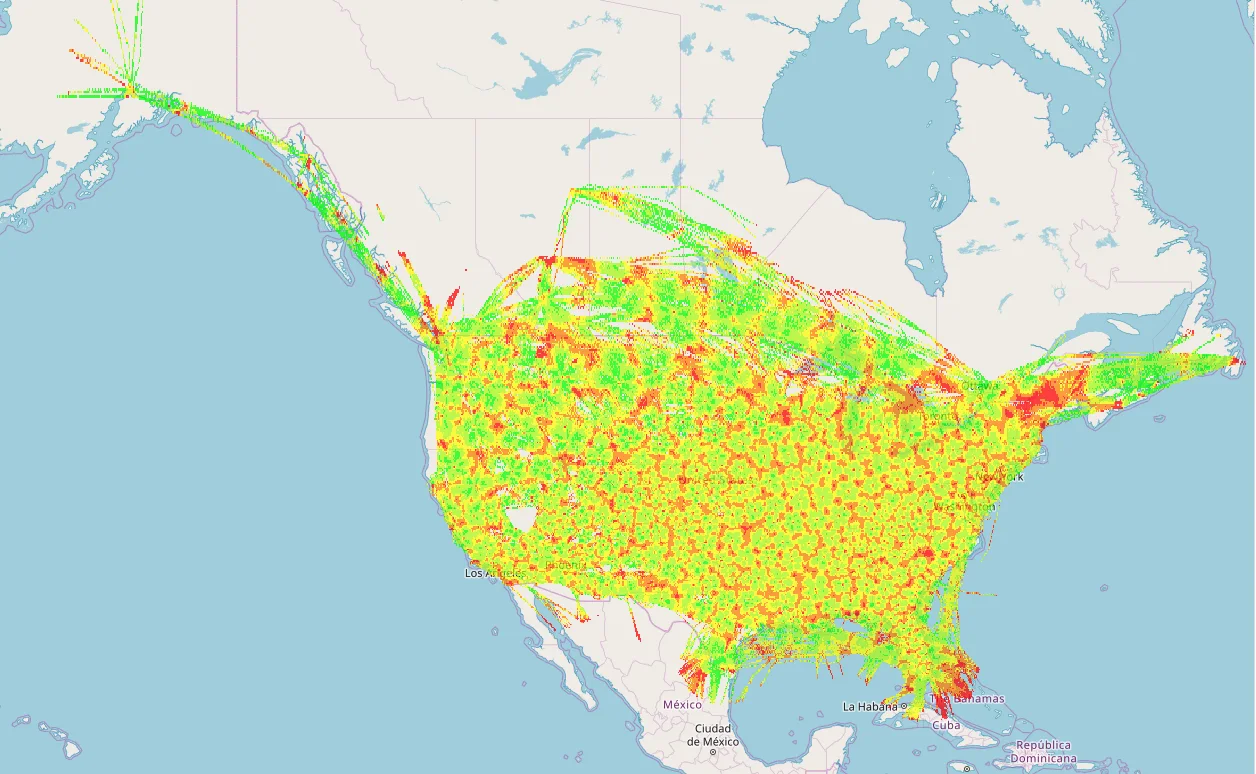
However, there are cases when the visualization part can take more time for rendering than we can afford. In this situation, we might use “Image Mosaic” layer. Basically, this layer is a mosaic of georeferenced rasters. That means, we can generate GeoTiff file from our data based on some main value which will bring the color to the final raster. Here’s how it looks on GeoServer:

As in the previous example, we can add style and put it as a separate layer on some map UI:
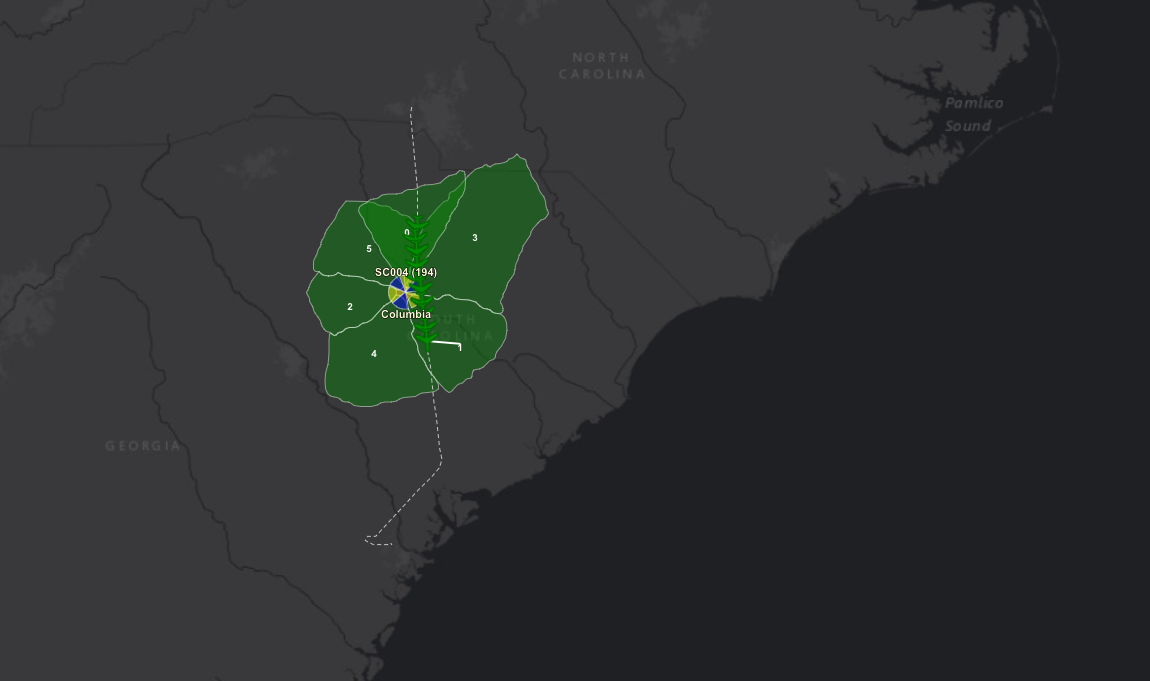
- WFS (Web Feature Service) – by users request it generates geographical features from geospatial data as a response. For example, we can get a response in JSON format:

Using this JSON we can create some shapes and features on UI with the help of OpenLayers.
- WPS (Web Processing Service) – defines how a client can request the execution of a process and how the output from the process is handled;
In case you need something more, something special and custom – GeoServer perfectly allows you to build your own extensions of each of these services.
Conclusion. Putting it all together
Everything mentioned above gives a user a wide range of possibilities for integrating big data into the geospatial word. Moreover, you do not need to worry about configurations, for example, how the storage distributes the data.
All these technologies can be used separately from each other. However, considering a wide array of data analytics services becomes essential when building an End-To-End application with raw data and a final picture within a flexible and easy-supporting environment.


